最近python基础课讲到了多线程,老师让交个多线程的实例练习。于是来试试多线程爬虫,正好复习一下mooc上自学的嵩天男神的爬虫知识。想法很美好,过程却很心酸,从早上开始写,每次出现各种奇怪问题,到现在晚上了终于是搞好啦。害得我连晚上的课都没有听,不过最后看着文件夹中图片蹭蹭的往外冒,心里还是成就感爆棚~ 咳咳,不多bb,本例子是在下面大佬的博客中看见学习的, 先来看看我们的目标网站——https://www.doutula.com/ 这是他的官方首页 那么我们想要做到不仅仅爬取第一页的表情包,还想爬取第二页,第三页的表情包,只需要一个for循环,每次把url地址中的pages={}修改即可 ok,选取了目标网址,我们来看看他的网页源代码。按ctrl+U 找到我们需要的图片所在的html代码区域 今天这个程序主要是踩了一下几个坑: 第一个坑:找目标网站。爬取时必须很好的分析网站的源代码,我刚开始把原博客中的爬取首页换成了另一个板块,结果死活没有结果。原来两个页面虽然很相近,但是标签的属性有着细微的差别。 第二个坑:爬取下来的图片的命名问题,因为改了爬取网站。我不是太会向原博客中的代码那样截取每张图片的名字。看了看每张图片的名字都很像(心疼的抱住胖胖的你啦,胖胖的你啦啥的),就索性都命名为“心疼的抱住胖胖的你”+“给一个编号”,这样对我这个初学者来说比较方便。 第三个坑:刚开始命名时没有给编号,全部都叫“心疼胖胖的你”。好家伙,pycharm里一条条的下载成功飞速滚动,文件夹里却始终只有一张图片不同的内容闪来闪去。我后来明白了文件名字不能相同,不然会覆盖,就加上了编号解决了这个问题。 第四个坑:代码中下载图片原来是使用的urlretrieve,但是存在图片下载只有一半或者打不开的问题,欢乐种方式,效果好一些。 改一改 下面给出源代码,大部分还是原博客的代码。文章如果哪里写的有歧义或者不对,请大家帮我指出来,毕竟我也只是一个python多线程和爬虫的初学者orz 看看效果 哈哈哈哈,碎觉碎觉,狗命要紧 补充一波,如果要是爬取失败的同学,看看是不是保存的文件路径的问题。
实例参考博客链接,根据这位大佬博客做了小小的改进https://www.cnblogs.com/jrb2018/p/10126753.html
这是我们选取的爬取板块,搜索想要爬取的关键词

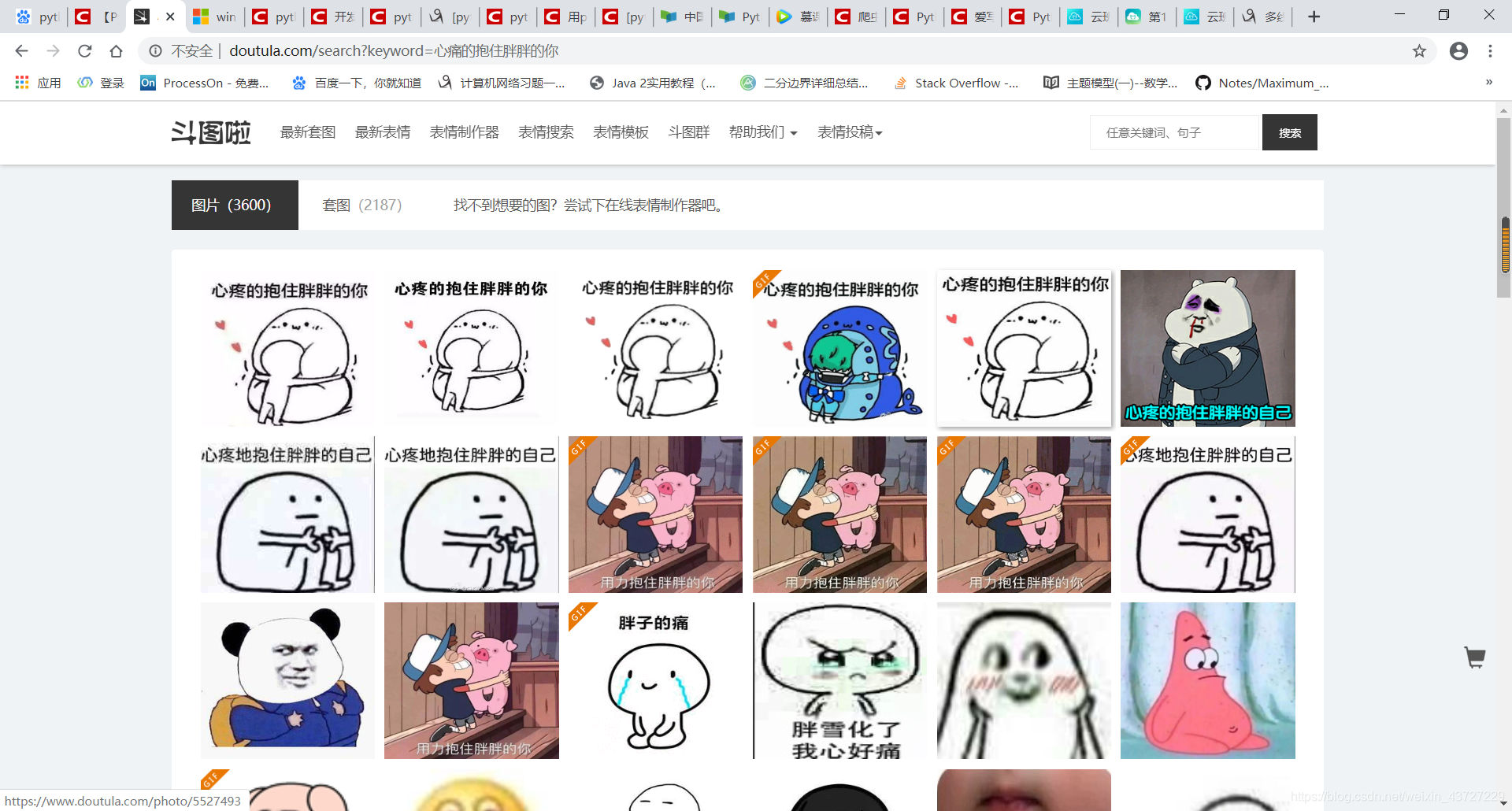
ps.搜索词还是要“温柔”一点。。。表情包嘛,各位老哥懂得,大多都是很骚气的话,有一些还。。。哈哈。还是得给老师看点“温柔”的图,所以我搜索的是“心疼的抱住胖胖的你”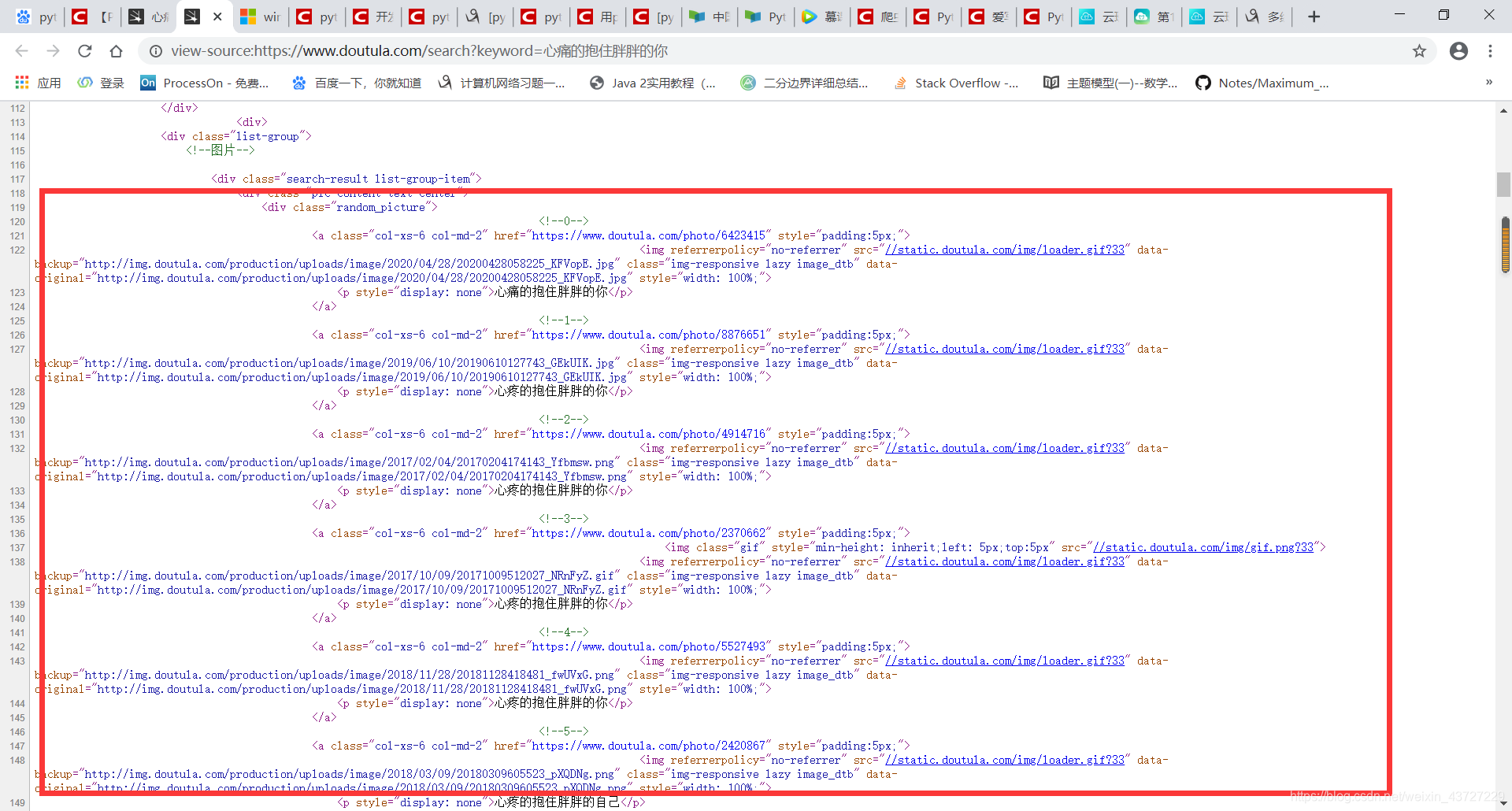
发现包含跟图片信息有关的标签是属性值为”random_picture”的这个div标签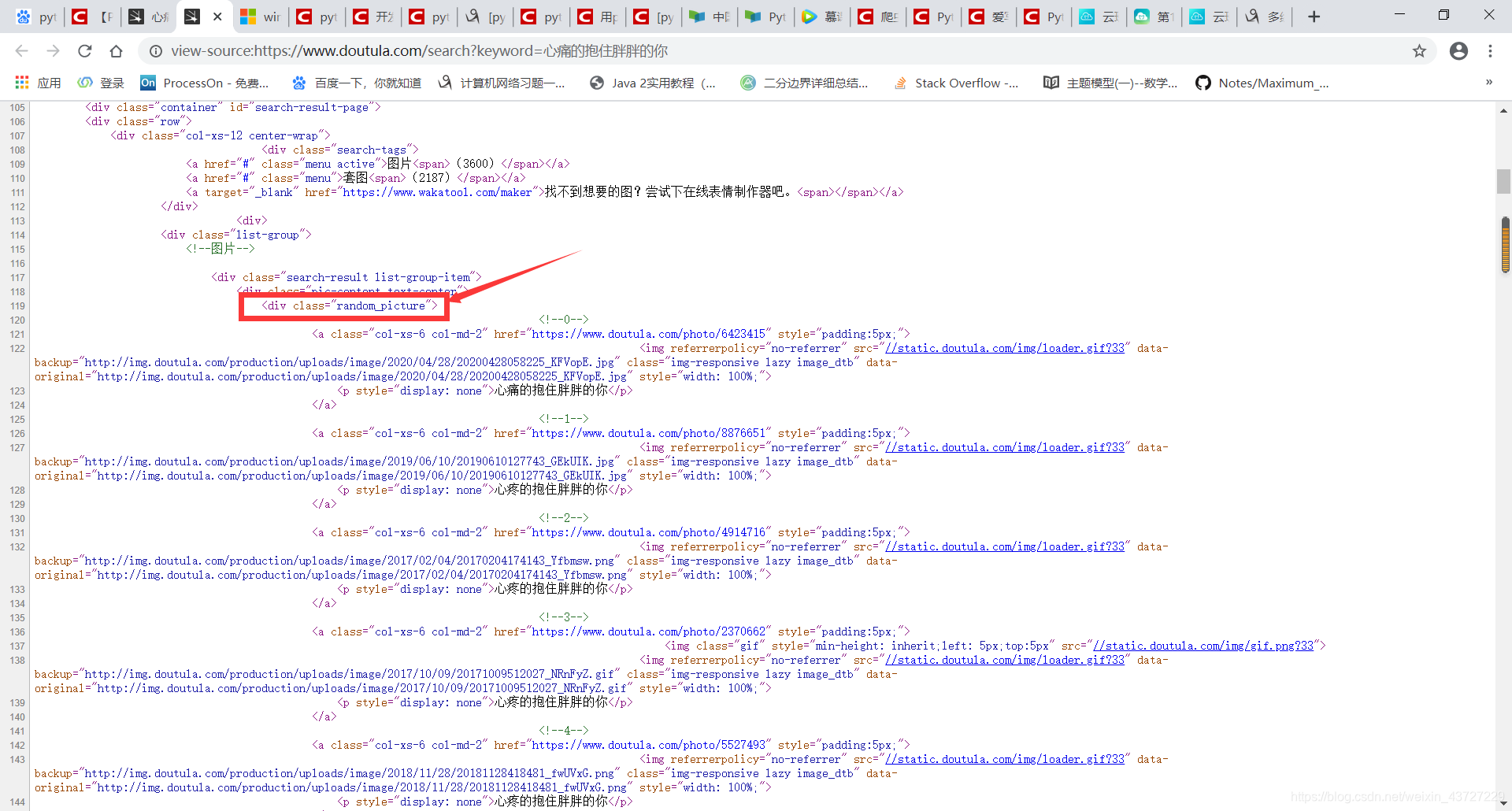
这里我们需要每一张图片的url链接,它在这里。
用lxml库对标签树进行层层的解析,这里我也不太会用,参考的是上面贴出的博客。mooc上讲的是BeautifulSoup库,不过我想二者应该功能类似。用urlretrieve爬取的效果不好,大部分图片存在打不开的问题 requests.get(data).content try: request.urlretrieve(url, 'images/' + filename) print(filename + ' 下载完成!') except urllib.ContentTooShortError: print( 'Network conditions is nt good.Reloading.') urllib.urlretrieve(url, filename) with open("images//"+filename, 'wb') as f: f.write(requests.get(url, timeout=30, headers=self.headers).content) f.close() print(filename + ' 下载完成!')
#使用Queue对象实现多线程爬取斗图网表情包,图片命名方面还是做的不太好,不太会解析源码中的名字用的自定义名字 import threading import requests from lxml import etree from urllib import request import os import re import urllib from queue import Queue class Producer(threading.Thread): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36', 'cookie':'自己的cookie信息' } def __init__(self, page_queue, img_queue, *args, **kwargs): super(Producer, self).__init__(*args, **kwargs) self.page_queue = page_queue self.img_queue = img_queue def run(self): while True: if self.page_queue.empty(): break url = self.page_queue.get() self.parse_page(url) def parse_page(self, url): count=0 response = requests.get(url, headers=self.headers) text = response.text html = etree.HTML(text) imgs = html.xpath("//div[@class='random_picture']//a//img") for img in imgs: #print(img.get('class')) if img.get('class') == 'gif': continue img_url = img.xpath(".//@data-backup")[0] if img_url.split('.')[-1] == 'gif': continue #print(img_url) suffix = os.path.splitext(img_url)[1] alt = "心疼的抱住胖胖的你"+str(count) count+=1 alt = re.sub(r'[,。??,/\·]', '', alt) img_name = alt + suffix self.img_queue.put((img_url, img_name)) class Consumer(threading.Thread): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36', 'cookie': '自己的cookie信息' } def __init__(self, page_queue, img_queue, *args, **kwargs): super(Consumer, self).__init__(*args, **kwargs) self.page_queue = page_queue self.img_queue = img_queue def run(self): while True: if self.img_queue.empty(): if self.page_queue.empty(): return img = self.img_queue.get(block=True) url, filename = img with open("images//"+filename, 'wb') as f: f.write(requests.get(url, timeout=30, headers=self.headers).content) f.close() print(filename + ' 下载完成!') #用urlretrieve爬取的效果不好,大部分图片存在打不开的问题 # requests.get(data).content # try: # request.urlretrieve(url, 'images/' + filename) # print(filename + ' 下载完成!') # except urllib.ContentTooShortError: # print( 'Network conditions is nt good.Reloading.') # urllib.urlretrieve(url, filename) def main(): page_queue = Queue(15)#存储网站每一页图片的url链接 img_queue = Queue(20) for x in range(1, 10): url = "https://www.doutula.com/search?type=photo&more=1&keyword=%E5%BF%83%E7%97%9B%E7%9A%84%E6%8A%B1%E4%BD%8F%E8%83%96%E8%83%96%E7%9A%84%E4%BD%A0&page={}" .format(str(x))#根据爬取网站不同页面的url地址规律设置爬取的每一页url链接 #print(url) #url = "http://699pic.com/tupian/139787-{}.html".format(str(x))这是另一个图片网站,也可以试试这个 #print(url) page_queue.put(url) for x in range(5): t = Producer(page_queue, img_queue) t.start() for x in range(5): t = Consumer(page_queue, img_queue) t.start() if __name__ == '__main__': main() 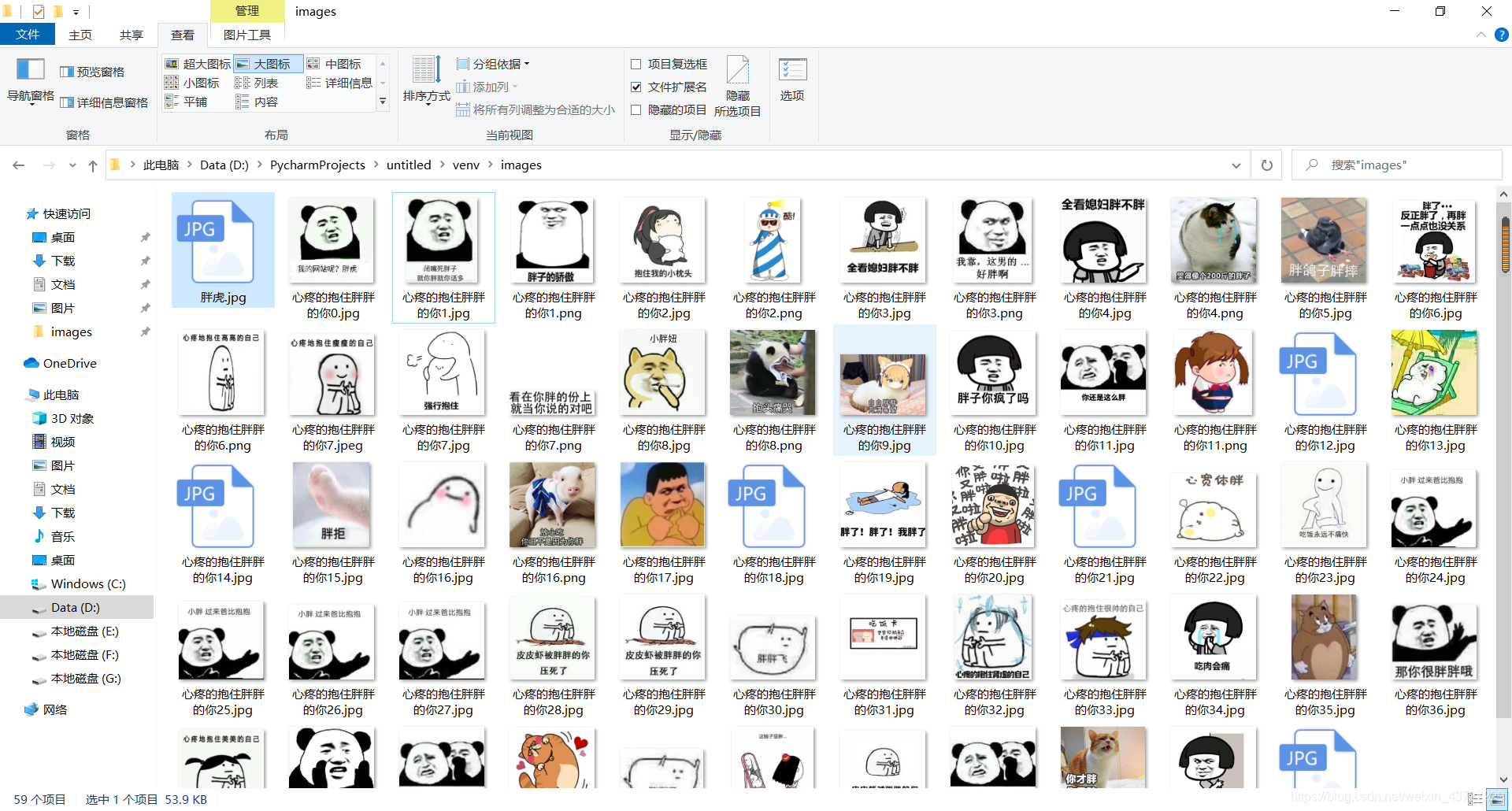
芜湖~太香啦~赶紧发到宿舍群里试试,舍友们手段极其残忍
cookie信息不写貌似也能爬下来。保险起见这有个找自己的cookie信息的方法视频教程:https://v.qq.com/x/page/f0951sww5ms.html
只不过是爬取淘宝网时的,大家在把网址换成斗图网也按视频里的步骤就可以了
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











