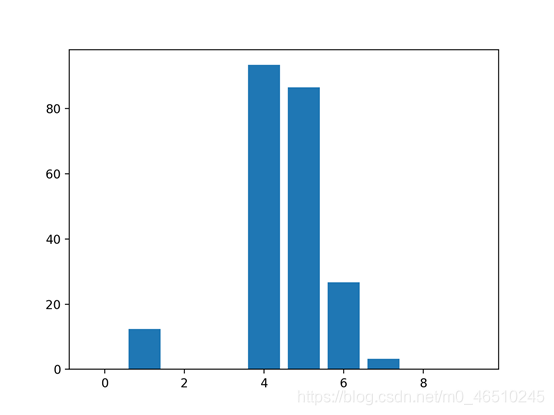
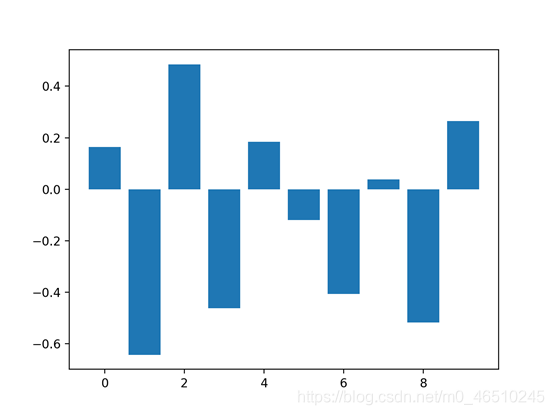
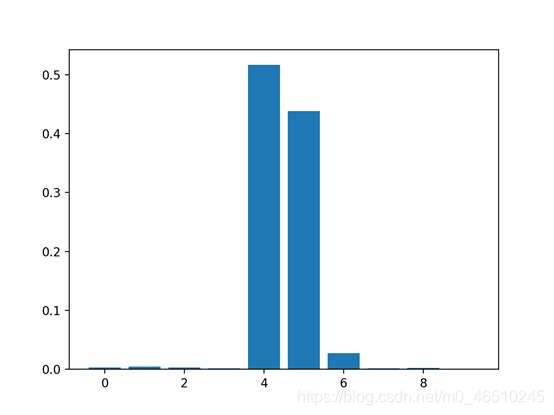
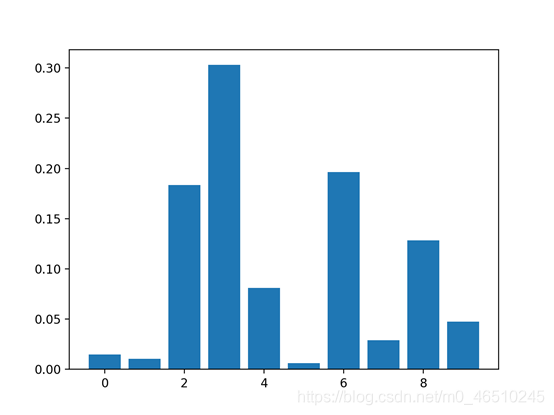
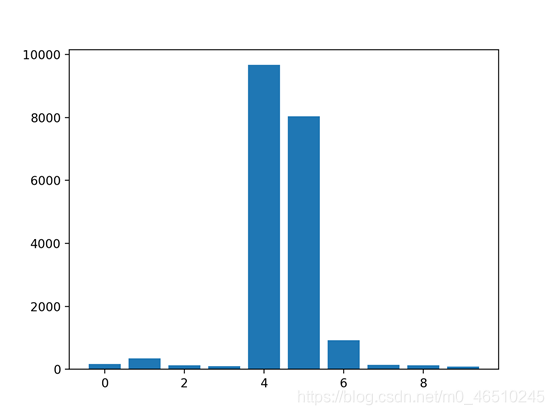
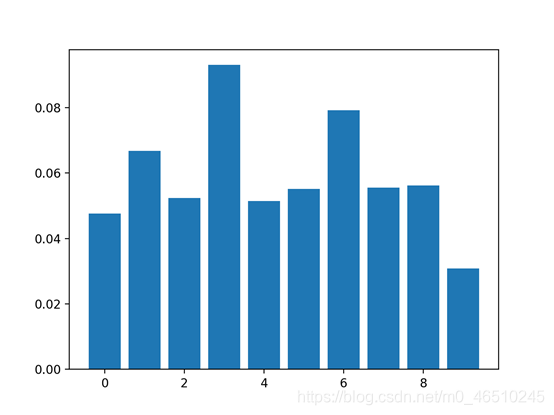
特征重要性评分是一种为输入特征评分的手段,其依据是输入特征在预测目标变量过程中的有用程度。 特征重要性有许多类型和来源,尽管有许多比较常见,比如说统计相关性得分,线性模型的部分系数,基于决策树的特征重要性和经过随机排序得到重要性得分。 特征重要性在预测建模项目中起着重要作用,包括提供对数据、模型的见解,以及如何降维和选择特征,从而提高预测模型的的效率和有效性。 在本教程中,我将会阐述用于python机器学习的特征重要性。完成本教程后,你将会知道: 现在让我们开始吧. 本教程分为五部分,分别是: 1.特征重要性 2.准备 2.1. 检查Scikit-Learn版本 2.2. 创建测试数据集 3.特征重要性系数 3.1. 基于线性回归系数的特征重要性 3.2. 基于Logistic回归的特征重要性 4.基于决策树的特征重要性 4.1. 基于CART的特征重要性 4.2. 基于随机森林的特征重要性 4.3. 基于XGBoost的特征重要性 5.随机排序特征重要性 5.1. 随机排序(回归)中的特征重要性 5.2. 随机排序(分类)中的特征重要性 特征重要性是一种为预测模型的输入特征评分的方法,该方法揭示了进行预测时每个特征的相对重要性。 可以为涉及预测数值的问题(称为回归)和涉及预测类别标签的问题(称为分类)计算特征重要性得分。 这些得分非常有用,可用于预测建模问题中的多种情况,例如: 特征重要性得分可以帮助了解数据集 相对得分可以突出显示哪些特征可能与目标最相关,反之则突出哪些特征最不相关。这可以由一个领域专家解释,并且可以用作收集更多的或不同的数据的基础。 特征重要性得分可以帮助了解模型 大多数重要性得分是通过数据集拟合出的预测模型计算的。查看重要性得分可以洞悉该特定模型,以及知道在进行预测时哪些特征最重要和哪些最不重要。这是一种模型解释,适用于那些支持它的模型。 特征重要性可用于改进预测模型 可以使用的重要性得分来选择要删除的特征(最低得分)或要保留的特征(最高得分)。这是一种特征选择,可以简化正在建模的问题,加快建模过程(删除特征称为降维),在某些情况下,还可以改善模型的性能。 特征重要性得分可以被输入到包装器模型,如SelectFromModel或SelectKBest,以进行特征选择。 有许多方法和模型可以计算特征重要性得分。 也许最简单的方法是计算每个特征和目标变量之间的统计学相关系数。 在本教程中,我们将研究三种比较高级的特征重要性,即: 现在让我们深入了解这三个! 在深入学习之前,我们先确认我们的环境并准备一些测试数据集。 首先,确认你已安装最新版本的scikit-learn库。这非常重要,因为在本教程中,我们我们研究的一些模型需要最新版的库。 您可以使用以下示例代码来查看已安装的库的版本: 运行示例代码将会打印出库的版本。在撰写本文时,大概是version 0.22。你需要使用此版本或更高版本的scikit-learn。 接下来,让我们生成一些测试数据集,这些数据集可以作为基础来证明和探索特征重要性得分。每个测试问题有五个重要特征和五不重要的特征,看看哪种方法可以根据其重要性找到或区分特征可能会比较有意思。 分类数据集 我们将使用make_classification()函数创建一个用于测试的二进制分类数据集。 数据集将包含1000个实例,且包含10个输入特征,其中五个将会提供信息,其余五个是多余的。 为了确保每次运行代码时都得到相同的实例,我们将使用假随机数种子。下面列出了创建数据集的示例。 运行示例,创建数据集,并确保所需的样本和特征数量。 回归数据集 我们将使用make_regression()函数创建一个用于测试的回归数据集。 像分类数据集一样,回归数据集将包含1000个实例,且包含10个输入特征,其中五个将会提供信息,其余五个是多余的。 运行示例,创建数据集,并确保所需的样本和特征数量。 接下来,我们仔细看一下特征重要性系数。 线性的机器学习能够拟合出预测是输入值的加权和的模型。 案例包括线性回归,逻辑回归,和正则化的扩展案例,如岭回归和弹性网络。 所有这些算法都是找到一组要在加权求和中使用的系数,以便进行预测。这些系数可以直接用作粗略类型的特征重要性得分。 我们来仔细研究一下分类和回归中的特征重要性系数。我们将在数据集中拟合出一个模型以找到系数,然后计算每个输入特征的重要性得分,最终创建一个条形图来了解特征的相对重要性。 3.1线性回归特征重要性 我们可以在回归数据集中拟合出一个LinearRegression模型,并检索coeff_属性,该属性包含为每个输入变量(特征)找到的系数。这些系数可以为粗略特征重要性评分提供依据。该模型假设输入变量具有相同的比例或者在拟合模型之前已被按比例缩放。 下面列出了针对特征重要性的线性回归系数的完整示例。 运行示例,拟合模型,然后输出每个特征的系数值。 得分表明,模型找到了五个重要特征,并用零标记了剩下的特征,实际上,将他们从模型中去除了。 然后为特征重要性得分创建条形图。 这种方法也可以用于岭回归和弹性网络模型。 3.2 Logistic回归特征重要性 就像线性回归模型一样,我们也可以在回归数据集中拟合出一个LogisticRegression模型,并检索coeff_属性。这些系数可以为粗略特征重要性评分提供依据。该模型假设输入变量具有相同的比例或者在拟合模型之前已被按比例缩放。 下面列出了针对特征重要性的Logistic回归系数的完整示例。 运行示例,拟合模型,然后输出每个特征的系数值。 回想一下,这是有关0和1的分类问题。请注意系数既可以为正,也可以为负。正数表示预测类别1的特征,而负数表示预测类别0的特征。 从这些结果,至少从我所知道的结果中,无法清晰的确定出重要和不重要特征。 然后为特征重要性得分创建条形图。 现在我们已经看到了将系数用作重要性得分的示例,接下来让我们看向基于决策树的重要性得分的常见示例 决策树算法,比如说classification and regression trees(CART)根据Gini系数或熵的减少来提供重要性得分。这个方法也可用于随机森林和梯度提升算法。 OK.现在让我们看看相应的运行示例。 对于在scikit-learn中实现的特征重要性,我们可以将CART算法用于DecisionTreeRegressor和DecisionTreeClassifier类 拟合后,模型提供feature_importances_属性,可以访问该属性以检索每个输入特征的相对重要性得分。 让我们看一个用于回归和分类的示例。 基于CART(回归)的特征重要性 下面列出了拟合DecisionTreeRegressor和计算特征重要性得分的完整示例。 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的三个可能对预测很重要。 然后为特征重要性得分创建条形图。 基于CART(分类)的特征重要性 下面列出了拟合DecisionTreeClassifier和计算特征重要性得分的完整示例 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的四个可能对预测很重要。 然后为特征重要性得分创建条形图。 对于在scikit-learn中实现的特征重要性,我们可以将Random Forest算法用于DecisionTreeRegressor和DecisionTreeClassifier类。 拟合后,模型提供feature_importances_属性,可以访问该属性以检索每个输入特征的相对重要性得分。 这种方法也可以与装袋和极端随机树(extraTree)算法一起使用。 让我们看一个用于回归和分类的示例。 随机森林(回归)中的特征重要性 下面列出了拟合RandomForestRegressor和计算特征重要性得分的完整示例 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的两个或三个可能对预测很重要。 然后为特征重要性得分创建条形图。 随机森林(分类)中的特征重要性 下面列出了拟合RandomForestClassifier和计算特征重要性得分的完整示例 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的两个或三个可能对预测很重要。 然后为特征重要性得分创建条形图。 XGBoost是一个库,它提供了随机梯度提升算法的高效实现。可以通过XGBRegressor和XGBClassifier类将此算法与scikit-learn一起使用。 拟合后,模型提供feature_importances_属性,可以访问该属性以检索每个输入特征的相对重要性得分。 scikit-learn还通过GradientBoostingClassifier和GradientBoostingRegressor提供了该算法,并且可以使用相同的特征选择方法 首先,安装XGBoost库,例如: 然后,通过检查版本号来确认该库已正确安装并且可以正常工作。 运行该示例,你应该看到以下版本号或者更高版本。 有关XGBoost库的更多信息,请看: 让我们看一个用于回归和分类问题的示例。 基于XGBoost(回归)的特征重要性 下面列出了拟合XGBRegressor并且计算特征重要性得分的完整示例 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的两个或三个可能对预测很重要。 然后为特征重要性得分创建条形图。 基于XGBoost(分类)的特征重要性 下面列出了拟合XGBClassifier并且计算特征重要性得分的完整示例 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中有七个可能对预测很重要。 然后为特征重要性得分创建条形图。 随机排序特征重要性(Permutation feature importance)可以计算相对重要性,与所使用的模型无关。 首先,在数据集中拟合出一个模型,比如说一个不支持本地特征重要性评分的模型。然后,尽管对数据集中的特征值进行了干扰,但仍可以使用该模型进行预测。对数据集中的每个特征进行此操作。然后,再将整个流程重新操作3、5、10或更多次。我们得到每个输入特征的平均重要性得分(以及在重复的情况下得分的分布)。 此方法可以用于回归或分类,要求选择性能指标作为重要性得分的基础,例如回归中的均方误差和分类中的准确性。 可以通过permutation_importance()函数(以模型和数据集为参数)和评分函数进行随机排序特性选择。 让我们看下这个特征选择方法,其算法并不支持特征选择,尤其是k近邻算法( k-nearest neighbors)。 5.1随机排序(回归)特征重要性 下面列出了拟合KNeighborsRegressor并且计算特征重要性得分的完整示例。 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的两个或三个可能对预测很重要。 然后为特征重要性得分创建条形图。 5.2随机排序(分类)特征重要性 下面列出了拟合KNeighborsClassifier并且计算特征重要性得分的完整示例。 运行示例,拟合模型,然后输出每个特征的系数值。 结果表明,这十个特征中的两个或三个可能对预测很重要。 然后为特征重要性得分创建条形图。 在本教程中,您知道了在Python机器学习中的特征重要性得分。 具体来说,您了解到:
教程概述
1.特征重要性
2.准备
检查Scikit-Learn版本
生成测试数据集
3.特征重要性系数
4.基于决策树的特征重要性
4.1基于CART的特征重要性
4.2随机森林中的特征重要性
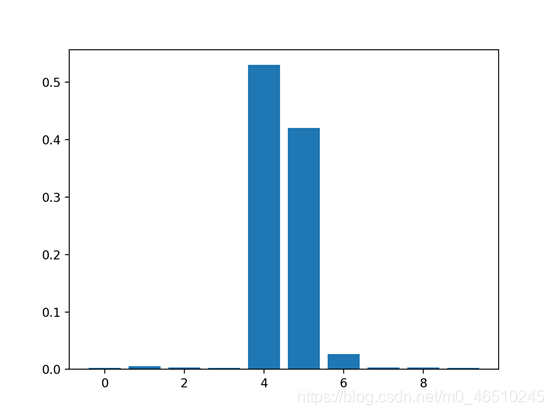
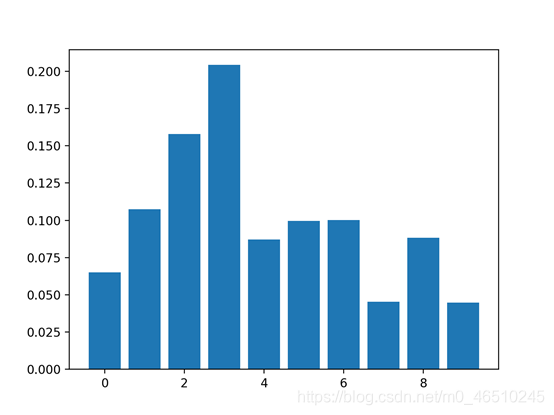
4.3基于XGBoost的特征重要性
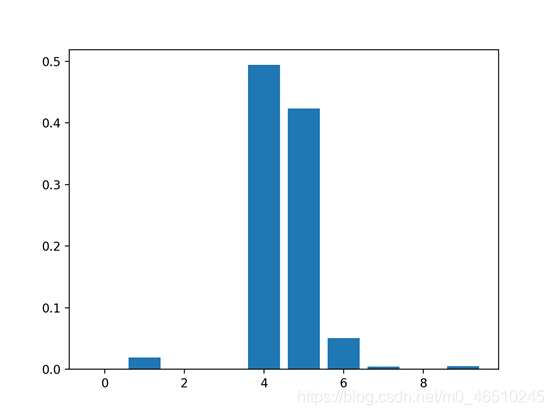
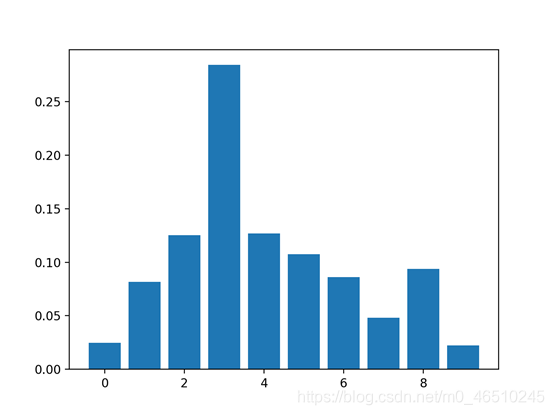
5.基于随机排序的特征重要性
总结
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


