首先我是小萌新一个,课程资料图片来自网络,最近在跟着百度飞浆学习强化学习和深度学习,欢迎大佬给我指出我写的不对的地方和解答一些我的疑惑。
强化学习在游戏有广泛应用,下面提供一个游戏链接的实例: 以下是我的一点小疑惑,请有系统学习过的同学或者老师可以解答下嘛: 强化学习四元组<S,A,P,R> 先把该导入的都导入了 下面定义一个类,我会按各个模块贴出来方便讲解 首先定义变量 根据输入观察值,采样输出的动作值,带探索,我们可以把这里的observation理解为局部的状态S,具体探索的概率可以自己设置合理的 根据输入观察值,预测输出的动作值 结合上面两个模块让我们测试一下我标注的到底是干嘛的 [ 0.7306868 -1.70580094 1.15283074 -0.26736715] 下面给出SRASA的更新公式 Qlearning和Sarsa算法唯一的区别是更新公式不一样因此我们只需要在sarsa基础上改一下更新公式就行 一句话总结:SRASA怕死,Qlearning不怕死莽夫好吧
强化学习笔记
概论和初印象
https://www.bilibili.com/video/BV1nE411H7qJ/?spm_id_from=333.788.videocard.1
其实第一次看这个视屏我陷入了哲学哈哈,万一他学习到最后学习到他们只是在游戏中开始消极对待怎么办,或者再后来,一开始消极对待,然后他意识到你说的这一点又开始假装积极对待。
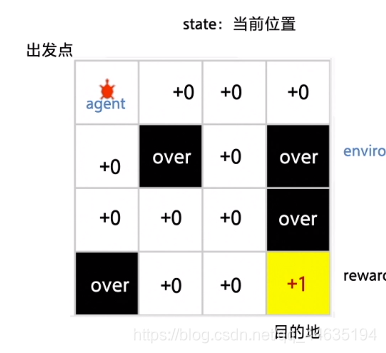
这是强化学习的一个实例,掉到坑里是负反馈,到达目的地给正反馈。(当时第一感觉是有点像DFS和BFS哎)
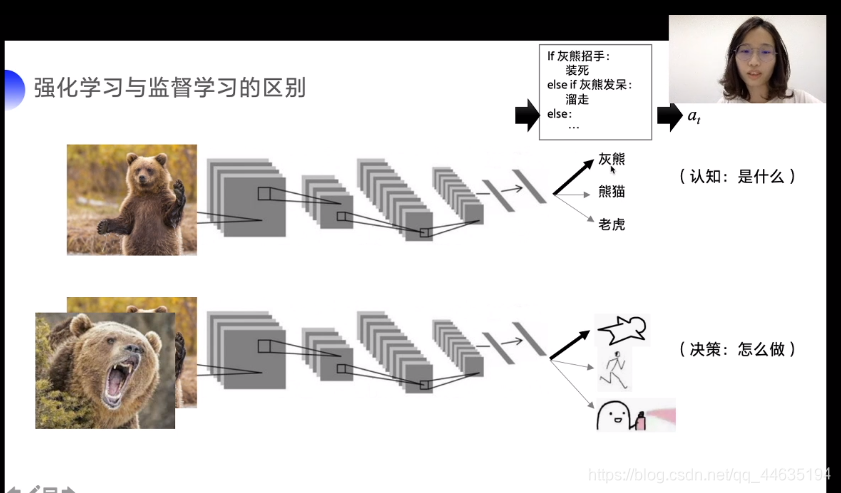
这是强化学习和监督学习的区别示例图,一般做预测的时候监督学习(比如深度学习的图像分类,前段时间刚入门)就会预测出图片中的物种是啥,但是强化学习则会告诉你决策,熊大熊二不是好惹的,赶紧撞死骗过去。
就是遗传算法,粒子群算法等和强化学习的区别和联系
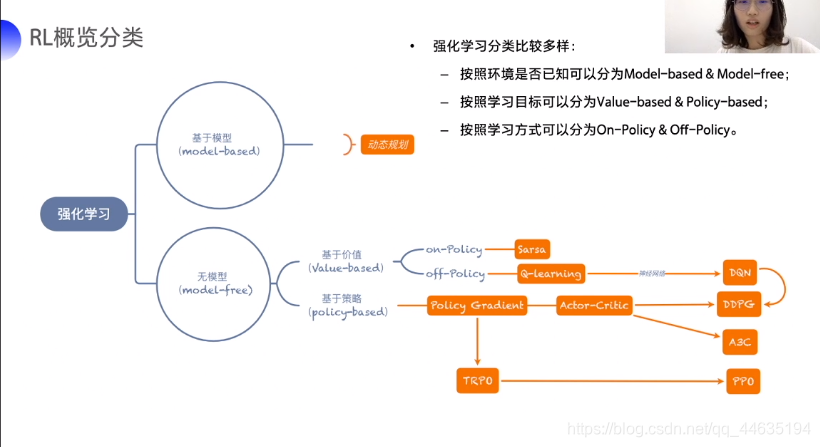
这个是强化学习的分类概况,以后学习的课程也是按这个分支来的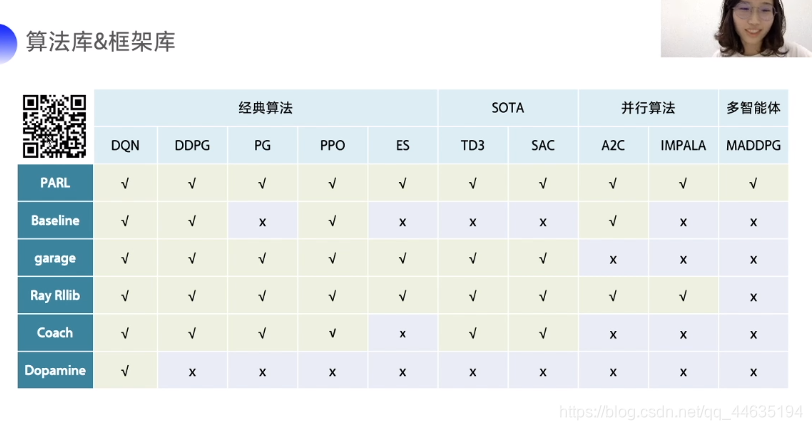
这是算法库和框架库
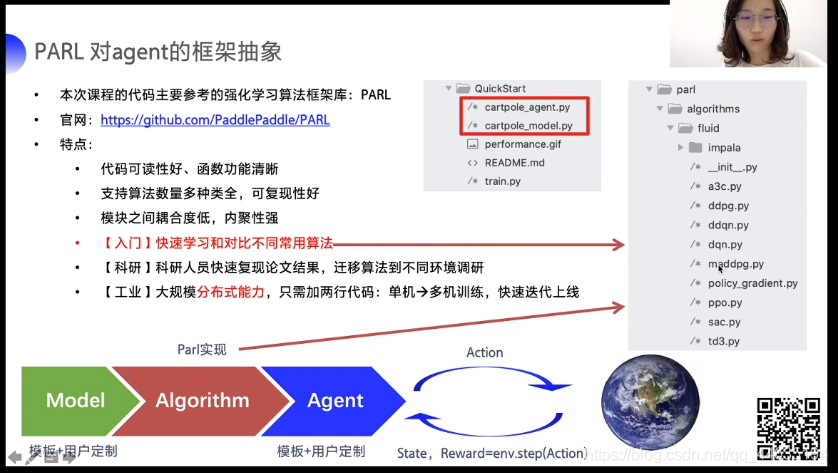
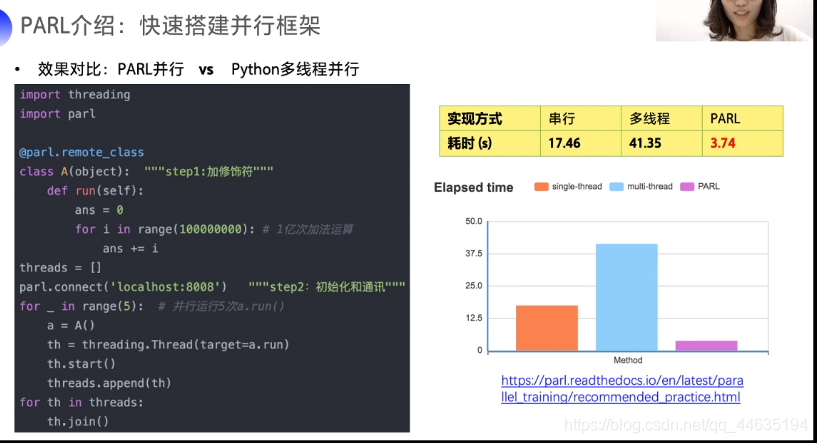
PARL有着优秀的并行能力
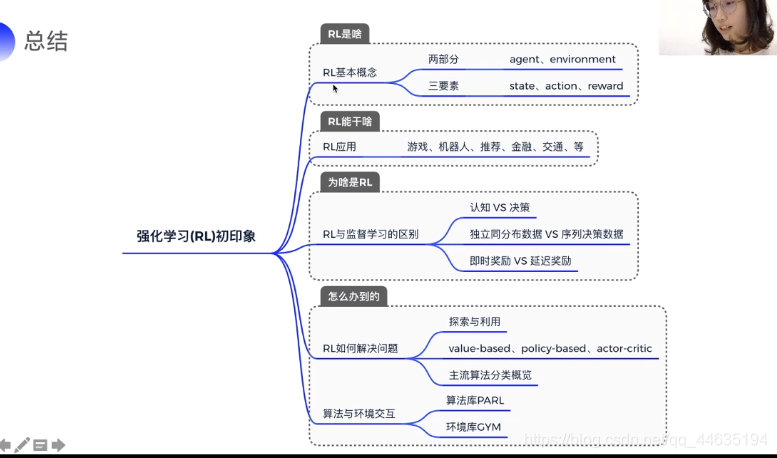
第一天学习
基础补充
s:state 状态
a:action 动作
r:reward 奖励
p:probability 状态转移概率
给个图方便理解
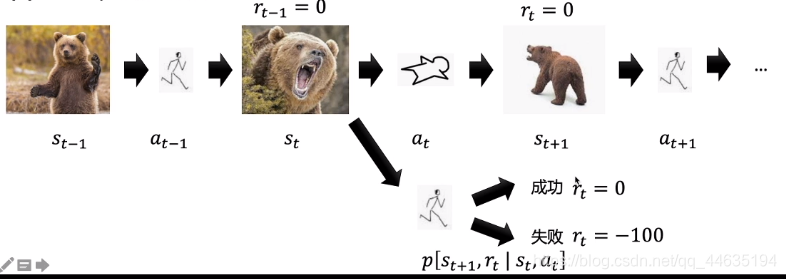
下面给出决策树更好地理解下
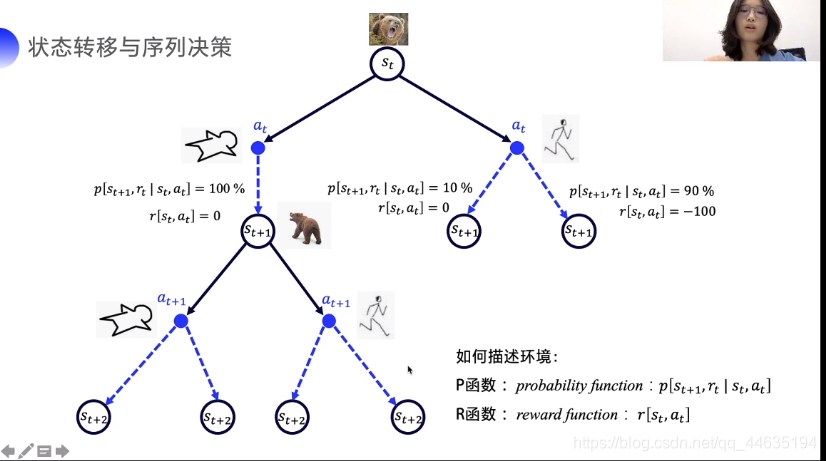
但是这样给了明确的概率和奖励对应函数,其实可以用动态规划做。但强化学习其实是一种P,R都未知的情况下的试错。
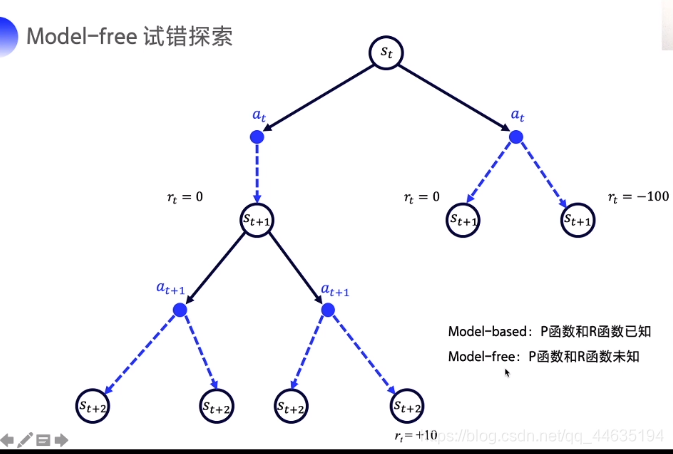
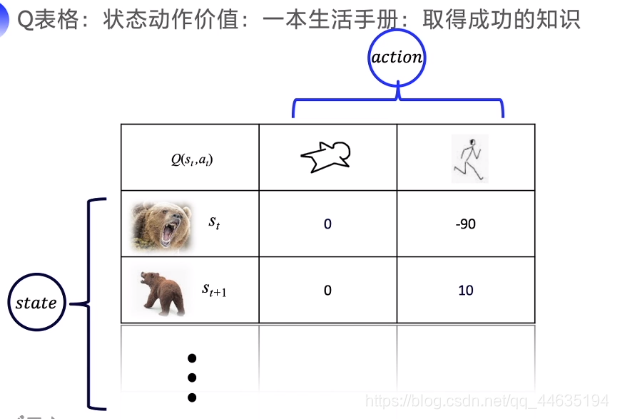
下面给出Q表格是如何存放内容的
怎么解读下面一个图呢,当前状态如果闯红灯会得到负反馈,但如果是一个抢救事件,那么把病人送到医院的奖励是巨大的,因此我们还要考虑未来收益,所以此种情况下闯红灯是可以的,因此算上未来总收益才能更好反应当前Q值。
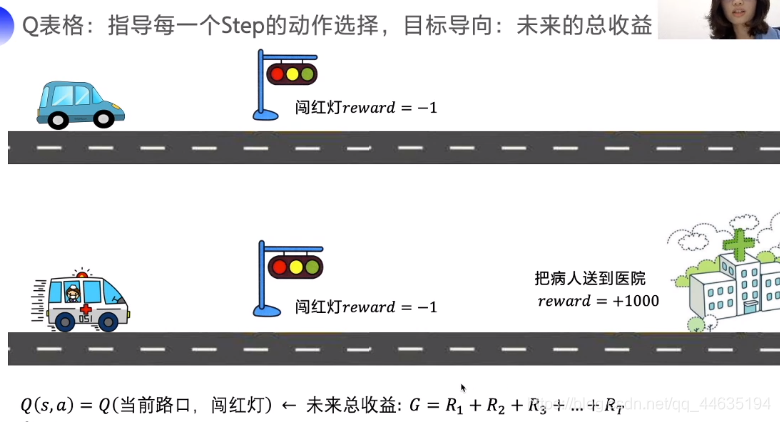
但是,真的是考虑的越远越好吗?我们做一个事顶多考虑后面一段时间的影响,真的会把几年甚至几十年后的事也要想清楚吗?这样显然是不合理的。
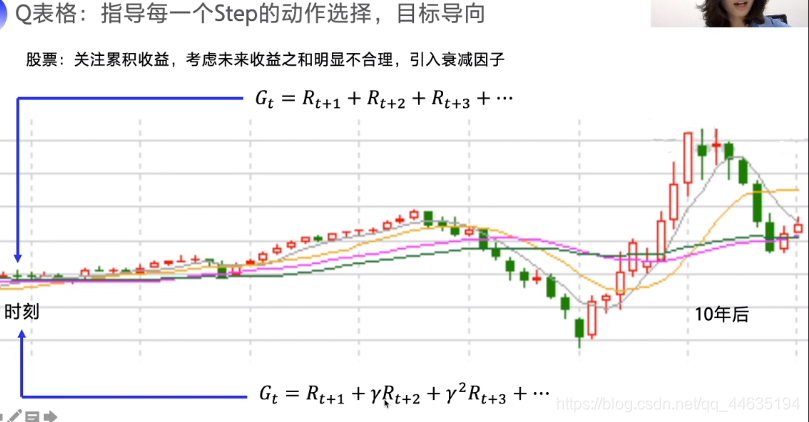
因此计算未来总收益引入了折扣率(我喜欢把它理解叫做“目光短浅-目光长远”平衡因素)当趋向于0时,想当时只考虑当前回报,趋向于1时就很贪心,所有回报都去考虑了。
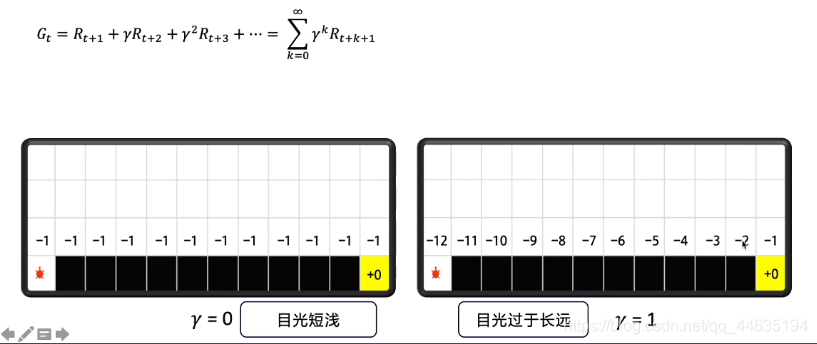
下面这个图解释得非常详细,Q是如何更新的,以及下一步的收益是如何影响当时收益的。不理解Q和G的同学可以把它们看成近似相等。下一步收益越大自然会导致当时的收益变大。

迷宫游戏(SRASA)
!pip install gym import gym import numpy as np import time class SarsaAgent(object): def __init__(self, obs_n, act_n, learning_rate=0.01, gamma=0.9, e_greed=0.1): self.act_n = act_n # 动作维度,有几个动作可选 self.lr = learning_rate # 学习率 self.gamma = gamma # reward的衰减率 self.epsilon = e_greed # 按一定概率随机选动作 self.Q = np.zeros((obs_n, act_n)) def sample(self, obs): if np.random.uniform(0,1)<(1-self.epsilon): action=self.predict(obs) else: action=np.random.choice(self.act_n)#没学过我觉得这里应该是返回动作集的索引而不是具体的动作? return action def predict(self, obs): Q_list=self.Q[obs,:] maxQ=np.max(Q_list) action_list=np.where(maxQ==Q_list)[0]#这一行不懂,测试看看放在此cell的下面 action=np.random.choice(action_list) return action a=np.random.randn(4) print(a) maxtext=np.max(a) print(maxtext) b=np.where(maxtext==a) print(b) c=np.random.choice(b[0]) print(c)
1.152830743940724
(array([2]),)
2
根据输出结果我们可以看出返回的确实不是具体动作而是动作的索引,但是choice返回的不应该是值嘛?为什么也是索引呢,这是因为放进choice的列表本身保存的就是一系列索引。
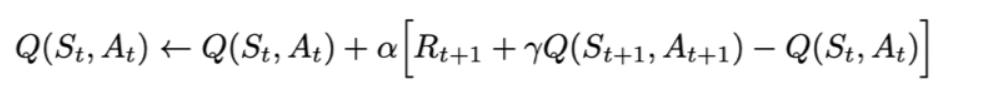
def learn(self, obs, action, reward, next_obs, next_action, done): """ on-policy obs: 交互前的obs, s_t action: 本次交互选择的action, a_t reward: 本次动作获得的奖励r next_obs: 本次交互后的obs, s_t+1 next_action: 根据当前Q表格, 针对next_obs会选择的动作, a_t+1 done: episode是否结束 """ predict_Q=self.Q[obs,action] if done: target_Q = reward else: target_Q = reward + self.gamma * self.Q[next_obs, next_action] self.Q[obs, action] += self.lr * (target_Q - predict_Q) def run_episode(env, agent, render=False): total_steps = 0 # 记录每个episode走了多少step total_reward = 0 obs = env.reset() # 重置环境, 重新开一局(即开始新的一个episode) action = agent.sample(obs) # 根据算法选择一个动作 while True: next_obs, reward, done, _ = env.step(action) # 与环境进行一个交互 next_action = agent.sample(next_obs) # 根据算法选择一个动作 # 训练 Sarsa 算法 agent.learn(obs, action, reward, next_obs, next_action, done) action = next_action obs = next_obs # 存储上一个观察值 total_reward += reward total_steps += 1 # 计算step数 if render: env.render() #渲染新的一帧图形 if done: break return total_reward, total_steps def test_episode(env, agent): total_reward = 0 obs = env.reset() while True: action = agent.predict(obs) # greedy next_obs, reward, done, _ = env.step(action) total_reward += reward obs = next_obs # time.sleep(0.5) # env.render() if done: break return total_reward # 使用gym创建迷宫环境,设置is_slippery为False降低环境难度 env = gym.make("FrozenLake-v0", is_slippery=False) # 0 left, 1 down, 2 right, 3 up # 创建一个agent实例,输入超参数 agent = SarsaAgent( obs_n=env.observation_space.n, act_n=env.action_space.n, learning_rate=0.1, gamma=0.9, e_greed=0.1) # 训练500个episode,打印每个episode的分数 for episode in range(500): ep_reward, ep_steps = run_episode(env, agent, False) print('Episode %s: steps = %s , reward = %.1f' % (episode, ep_steps, ep_reward)) # 全部训练结束,查看算法效果 test_reward = test_episode(env, agent) print('test reward = %.1f' % (test_reward)) 迷宫游戏(Qlearning)
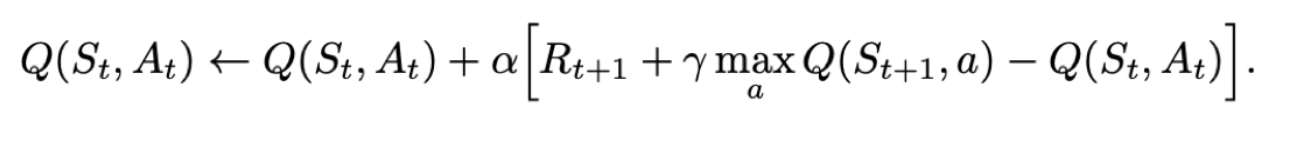
def learn(self, obs, action, reward, next_obs, done): """ off-policy obs: 交互前的obs, s_t action: 本次交互选择的action, a_t reward: 本次动作获得的奖励r next_obs: 本次交互后的obs, s_t+1 done: episode是否结束 """ predict_Q = self.Q[obs, action] if done: target_Q = reward # 没有下一个状态了 else: target_Q = reward + self.gamma * np.max(self.Q[next_obs, :]) # Q-learning self.Q[obs, action] += self.lr * (target_Q - predict_Q) # 修正q
还有我觉得动态规划和强化学习的区别应该就是动态规划都是预先知道所有奖励和概率的,因此填表可以求得最优解,但是强化学习奖励需要算,概率也未知
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 463
463