大数据(BigData) :指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 将独立的具备不同功能和数据的主机连接起来,协同完成指定任务。 一种可以通过网络方便地接入共享资源池,按需获取计算资源的服务模型。共享资源池中的资源可以通过较少的管理代价和简单业务交互过程而快速部署和发布。 Google的伟大之处,不仅因为它建立了一个很好很强大的搜索引擎,而且还在于它创造了3项革命性的大数据技术:GFS、MapReduce和BigTable,即所谓的Google三驾马车。 MapReduce将计算过程分为两个阶段: Map 和Reduce.
一、大数据的概论
1.1 大数据概念
主要解决:海量数据的存储和海量数据的分析计算问题。PB,EB级别的数据存储单位。1.2 大数据的特点(5V)
数量巨大,通常在1PB(1024TB)以上,各行业标准不同。
数据增长速度快,读写、处理速度快、时效性高。
结构多样化或非结构化。
通过大量的数据才能刻画出有用信息,如深度学习中需要海量的样本数据。
数据的准确性和可信赖度高。传统的数据存储方式
1.使用关系表保存数据,可表现复杂的数据关系并方便查询
2.最大限度的消除了数据冗余,节省存储空间
3.数据持久化存储在磁盘上可靠性高
4.SQL功能强大,便于编程
1.频繁的约束性检查及索引维护导致写入效率低
2.数据的持久化存储,使得磁盘的IO读写速度成为瓶颈,导致读写效率低
3.SQL功能过于强大导致执行规则复杂,进而影响效率分布式技术
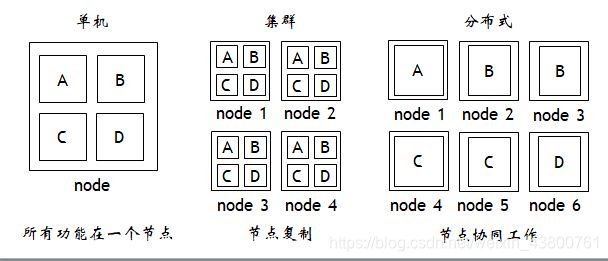
单机、集群和分布式的区别
新兴的数据处理技术——云技术
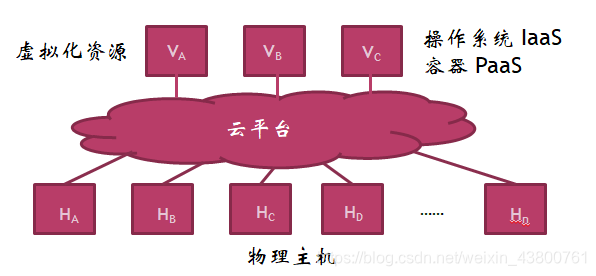
云计算类型
利用虚拟化技术将硬件设备等基础资源封装成服务提供给用户使用,如:阿里云、腾讯云等
对资源进一步抽象,提供应用程序应用环境,用户只需上传自己的应用程序即可,类似以前的虚拟主机,如:微信小程序
将应用软件功能封装成服务,如:病毒云查杀、百度网盘、iCloud1.3 大数据应用场景



二、大数据生态
2.1 Hadoop是什么
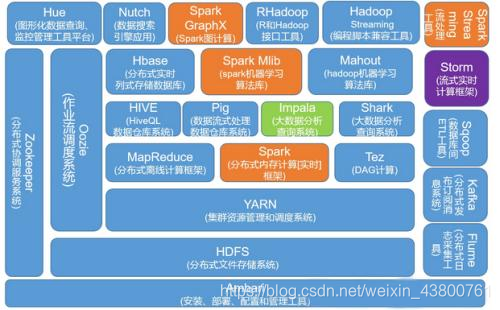
更细致的分层结构:
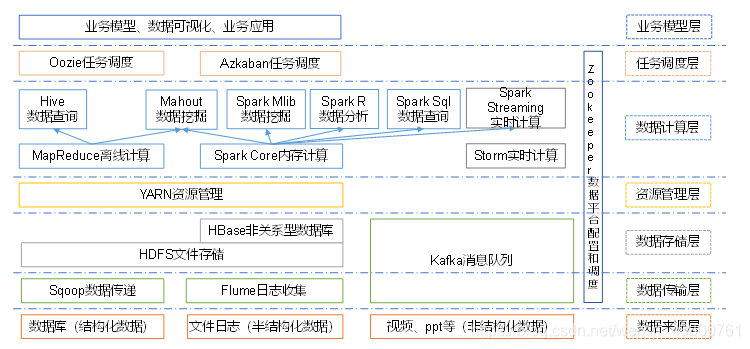
基于上图,对分层及其中的一些技术做了解释,其思维导图如下:
2.2 Hadoop发展历史
Google三篇论文影响深远,“山寨”产品如潮水般涌现……
Cutting和Cafarella根据其前两篇论文完善其开源搜索引擎项目Nutch
2006年,Yahoo!聘请Cutting将Nutch搜索引擎中的存储和处理部分抽象成为Hadoop,Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理,逐渐成为行业主流。这样,Google以一种独特的方式,影响了大数据处理的潮流。2.3 Hadoop的优势(4高)
2.4 Hadoop的组成
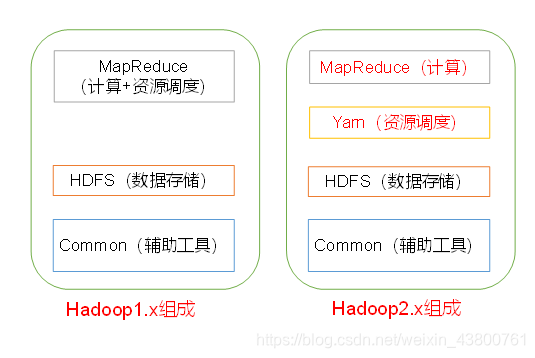
在Hadoop1x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yamn。Yarn只负责资源的调度,MapReduce只负责运算。2.4.1 HDFS架构概述
2.4.2 YARN架构概述
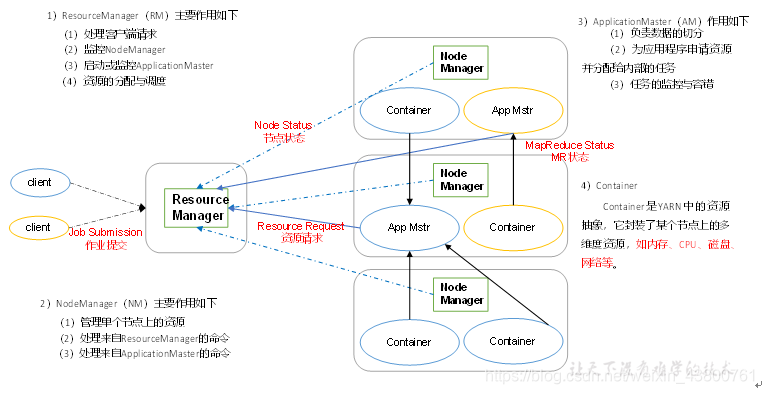
2.4.3 MapReduce架构概述
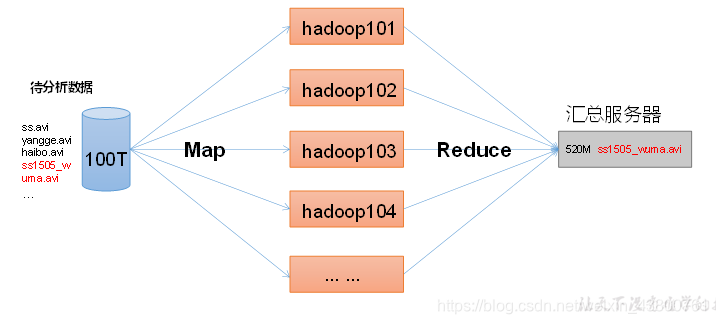
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 7万+
7万+