python爬取三国演义,生成词云、图表 项目目标:三国人物名称及出现次数—–数据统计分析 bs4数据解析必备知识点:标签定位,提取标签中的数据值 2.查找 3.所有符合条件的标签 4.select放置选择器 类选择器. .代表的就是tang 常用层级选择器 6.获取标签中的属性值 1.爬取数据来源: 古诗词网《三国演义》 2.文本词频统计:中文分词库–jieba库,具体的解释已在代码处声明 –url首页 –我们要的是这个目录的标题和点击后的页面内容 点击后的页面,发现规律 详细页面要获取的内容 尽管我们说《三国演义》对汉室、对刘备有很明显的倾向性,但人物出场最多的还是曹操,这个结果会不会让你们惊讶呢?
1.目标
2.码前须知
提出问题:哪个人物在三国演义中出现的次数最多?,我们希望通过数据分析来获得答案。
分析工具:pandas,Matplotlib
pip install bs4
pip install lxml
pip install pandas
pip install Matplotlib
1.实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中,lxml是解析器,固定的参数,下面是举例
#本地html加载到该对象:
fp = open(’./test.html’,‘r’,encoding=‘utf-8’)
soup = BeautifulSoup(fp,‘lxml’)
print(soup)
#互联网上获取的源码数据(常用)
page_text = response.text
soup = BeautifulSoup(page_text,‘lxml’)
2.通过调用BeautifulSoup对象中相关的属性或者方法对标签进行定位和提取
bs4具体属性的用法
1.标签 ,如< p > < a >< div >等等
soup.tagName
例如
soup.a #返回的是html第一次出现的tagName的a标签
soup.div #返回的是html第一次出现的tagName的div标签
soup.find(‘div’) 用法相当于soup.div
属性定位, < div class=‘song’ >
soup.find(‘div’,class_=‘song’) class_需要带下划线
class_/id/attr
soup.find_all(‘a’) #返回符合所有的a标签,也可以属性定位
soup.select(’.tang’)
soup.select(‘某种选择器(id,class,标签,选择器)’)
返回的是一个列表
定位到标签下面的标签 >表示标签一个层级选择器
soup.select(’.tang > ul >li >a’[0])
空格表示多级选择器
soup.select(‘tang’ > ul a’[0]) 与上述的表达式相同
5.获取标签中间的文本数据
soup.a.text/string/get_text()
区别
text/get_text():可以获取某一个标签中所有的文本内容,即使不是直系的文本
string:只可以获取直系文本
soup.a[‘href’] 相当于列表操作3.操作流程
2.编码流程:
3.生成词云:wordcloud,具体的解释已在代码处声明
4.生成柱状分析图:matplotlib,具体的解释已在代码处声明

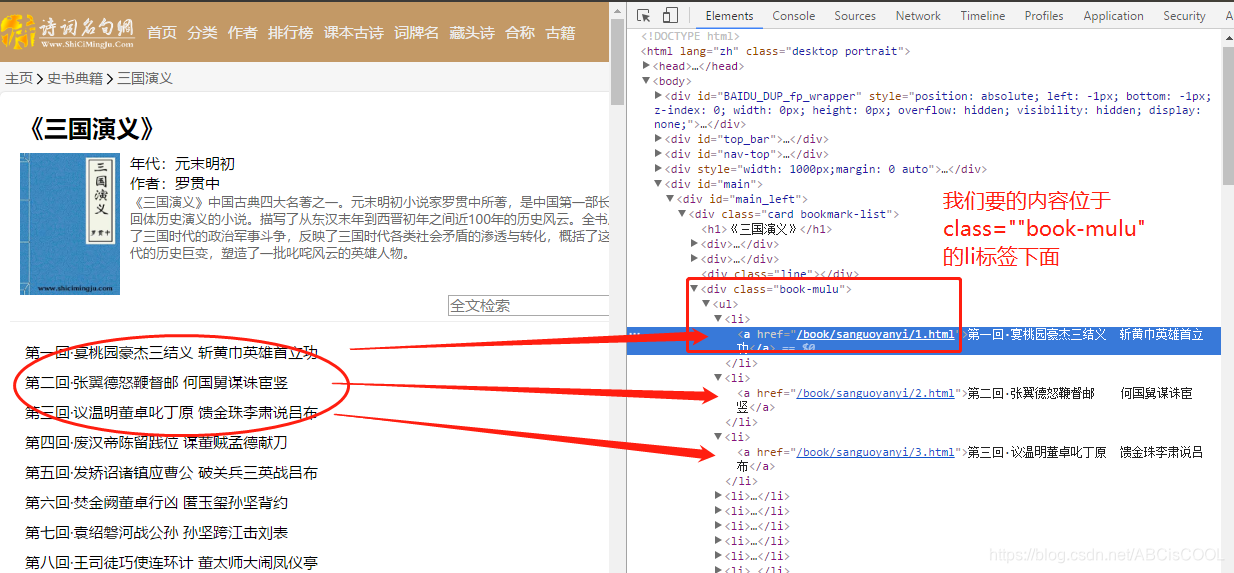


4.完整代码
from bs4 import BeautifulSoup import requests import jieba#优秀的中文分词第三方库 import wordcloud import pandas as pd from matplotlib import pyplot as plt #1.对首页html进行爬取 url = 'https://www.shicimingju.com/book/sanguoyanyi.html' headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } fp = open('./sanguo.txt','w',encoding='utf-8') page_text = requests.get(url=url,headers=headers).text #2.数据解析 #实例化对象 soup = BeautifulSoup(page_text,'lxml') #获得li标签 li_list = soup.select('.book-mulu > ul > li') #取得li标签里的属性 for li in li_list: #通过bs4的方法直接获取a标签直系文本 title = li.a.string #对url进行拼接得到详情页的url detail_url = 'https://www.shicimingju.com'+li.a['href'] #对详情页发起请求 detail_page_text = requests.get(url=detail_url,headers=headers).text #解析详情页的标签内容,重新实例化一个详情页bs对象,lxml解析器 detail_soup = BeautifulSoup(detail_page_text,'lxml') #属性定位 div_tag = detail_soup.find('div',class_='chapter_content') #解析到了章节的内容,利用text方法获取 content = div_tag.text #持久化存储 fp.write(title+':'+content+'n') print(title,'爬取成功!!!') print('爬取文本成功,进行下一步,jieba分词,并生成一个sanguo.xlsx文件用于数据分析') #排除一些不是人名,但是出现次数比较靠前的单词 excludes = {"将军","却说","荆州","二人","不可","不能","如此","商议","如何","主公","军士", "左右","军马","引兵","次日","大喜","天下","东吴","于是","今日","不敢","魏兵", "陛下","一人","都督","人马","不知","汉中","只见","众将","后主","蜀兵","上马", "大叫","太守","此人","夫人","先主","后人","背后","城中","天子","一面","何不", "大军","忽报","先生","百姓","何故","然后","先锋","不如","赶来","原来","令人", "江东","下马","喊声","正是","徐州","忽然","因此","成都","不见","未知","大败", "大事","之后","一军","引军","起兵","军中","接应","进兵","大惊","可以","以为", "大怒","不得","心中","下文","一声","追赶","粮草","曹兵","一齐","分解","回报", "分付","只得","出马","三千","大将","许都","随后","报知","前面","之兵","且说", "众官","洛阳","领兵","何人","星夜","精兵","城上","之计","不肯","相见","其言", "一日","而行","文武","襄阳","准备","若何","出战","亲自","必有","此事","军师", "之中","伏兵","祁山","乘势","忽见","大笑","樊城","兄弟","首级","立于","西川","朝廷","三军","大王","传令","当先","五百","一彪","坚守","此时","之间","投降","五千","埋伏","长安","三路","遣使","英雄"} #打开爬取下来的文件,并设置编码格式 txt = open("sanguo.txt", "r", encoding='utf-8').read() #精确模式,把文本精确的切分开,不存在冗余单词,返回列表类型 words = jieba.lcut(txt) #构造一个字典,来表达单词和出现频率的对应关系 counts = {} #逐一从words中取出每一个元素 for word in words: #已经有这个键的话就把相应的值加1,没有的话就取值为0,再加1 if len(word) == 1: continue elif word == "诸葛亮" or word == "孔明曰": rword = "孔明" elif word == "关公" or word == "云长": rword = "关羽" elif word == "玄德" or word == "玄德曰": rword = "刘备" elif word == "孟德" or word == "丞相": rword = "曹操" else: rword = word #如果在里面返回他的次数,如果不在则添加到字典里面并加一 counts[rword] = counts.get(rword,0) + 1 #删除停用词 for word in excludes: del counts[word] #排序,变成list类型,并使用sort方法 items = list(counts.items()) #对一个列表按照键值对的2个元素的第二个元素进行排序 #Ture从大到小,结果保存在items中,第一个元素就是出现次数最多的元素 items.sort(key=lambda x:x[1], reverse=True) #将前十个单词以及出现的次数打印出来 name=[] times=[] for i in range(30): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count)) name.append(word) times.append(count) print(name) print(times) #创建索引 id=[] for i in range(1,31): id.append(i) #数据帧,相当于Excel中的一个工作表 df = pd.DataFrame({ 'id':id, 'name':name, 'times':times, }) #自定义索引,不然pandas会使用默认的索引,这会导致生成的工作表 #也会存在这些索引,默认从0开始 df = df.set_index('id') print(df) df.to_excel('sanguo.xlsx') print("DONE!") print('生成文件成功,进行下一步,生成词云') #词云部分 w=wordcloud.WordCloud( font_path="C:\Windows\Fonts\simhei.ttf", #设置字体 background_color="white", #设置词云背景颜色 max_words=1000, #词云允许最大词汇数 max_font_size=100, #最大字体大小 random_state=50 #配色方案的种数 ) txt=" ".join(name) w.generate(txt) w.to_file("ciyun.png") print("done!") print("词云生成并保存成功!!!,进行下一步生成柱状图") dirpath = 'sanguo.xlsx' data = pd.read_excel(dirpath,index_col='id',sheet_name='Sheet1')#指定id列为索引 #print(data.head())#到此数据正常 print('OK!,到此数据正常') #柱状图部分 #直接使用plt.bar() 绘制柱状图,颜色紫罗兰 plt.bar(data.name,data.times,color="#87CEFA") #添加中文字体支持 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False #设置标题,x轴,y轴,fontsize设置字号 plt.title('三国人物名字前三十名出现的次数',fontsize=16) plt.xlabel('人名') plt.ylabel('统计次数') #因为X轴字体太长,利用rotation将其旋转90度 plt.xticks(data.name,rotation='90') #紧凑型布局,x轴太长为了显示全 plt.tight_layout() imgname = 'sanguo.jpg'#设置图片保存的位置 plt.savefig(imgname)#保存图片 plt.show() print('柱状图生成完毕!!!') print('所有程序执行完成') 

5.总结
缺点:其实人物排序也不准,比如都督,如果指周瑜的话,周瑜的排名可能会再靠前
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 3716
3716