回顾:数据的逻辑结构 图: G =(V,E) 无向图(Undirected graph): 每条边的没有方向,eg:G1 有向图(Directed graph): 每条边都有方向,eg:G2 完全图: 任意两个顶点都有一条边相连(有去有回) 稠密图: 有较多边或弧的图。 网: 边 / 弧带权值的图。 邻接: 有边 / 弧相连的两个顶点之间的关系。 关联(依附): 边 / 弧与顶点之间的关系。 顶点的度: 与该顶点相关联的边的数目,记为:TD(v) 那么,问:当有向图中仅1个顶点的入度为0,其余顶点的入度均为1,此时是什么形状?(答案:有向树,如下图) 连通图(强连通图): 在无(有)向图 G = ( V, {E} )中,对任意两个顶点v、u,都存在从 v 到 u 的路径,则称G是连通图(强连通图)。 子图: 设有两个图 G = ( V, {E} ) 和 G1 = ( V1, {E1} ),若 V1 包含于 V,E1 包含于 E,则称 G1 是 G 的子图。 首先回顾一下上边提到的邻接,什么是邻接 无向图 无向图 遍历定义: 遍历实质: 找每个顶点的邻接点的过程。 图的特点: 图中可能存在回路,且图的任一顶点都可能与其他顶点相同,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问的顶点。(例如,图中v2 和 v3) 那么如何避免重复访问? 图的常用遍历 参考:视频讲解 青岛大学–王卓 首先,我们选择 v2 为起始点,则 visited[ 1 ] = 1( visited[ n ] = [ 0,1,0,0,0,0 ] ) 接下来,看邻接矩阵 v1 这一行,可以看出 v2、v3、v4 均与 v1 相连,则从后两者之间做出选择,选择 v3(设置 visited[ 2 ] = 1;visited[ n ] = [ 1,1,1,0,0,0 ]); 以此类推,下一个邻接点为 v5(设置 visited[ 4 ] = 1;visited[ n ] = [ 1,1,1,0,1,0 ]) ,接下来与 v5 邻接的 v2、v3 均已经访问过,则依次退回 v2、v1,发现有未访问的点 v4,则选该点为下一个邻接点,之后一直重复上述操作。。。 最终达到 visited[ n ] = [ 1,1,1,1,1,1 ],访问路径为 v2 – v1 – v3 – v5 – v4 – v6 用邻接矩阵来表示图(假设有 n 个顶点,则为 n*n矩阵) 用邻接表表示图 结论: 参考:视频讲解 青岛大学–王卓 其实就是一层一层的访问,如下例 BFS 算法效率分析 更多关于图的应用:
文章目录

一,图的定义的基本术语


稀疏图: 有很少边或弧的图(e < n*log n)。
互为邻接点;邻接到 vj,vj 邻接于 vi。


路径: 接续的边构成的顶点序列。
路径长度: 路径上边或弧的数目 / 权值之和。
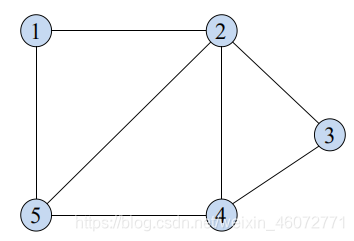
例,有无向图如上图,由 v5 到 v3 的路径可以是 [v5,v2,v3] 也可以是 [v5,v4,v3] 或 [v5,v2,v4,v3] 和 [v5,v4,v2,v3]。它们的路径长度分别为 2,2,3,3;若有权值的话需要将权值相加。
回路(环): 第一个顶点和最后一个顶点相同的路径。(起点与重点相同)
简单路径: 除路径起点和终点可以相同外,其余顶点均不相同的路径。
简单回路(简单环): 除路径起点和终点相同外,其余顶点均不相同的路径。

(a)简单路径:0 – 1 – 3 – 2,起点终点可以不同,但不能出现重复顶点。
(b)非简单路径:0 – 1 – 3 – 0 – 1 – 2,顶点 v0 和 v1 重复了。
(c)回路:0 – 1 – 3 – 0,起点和终点均为 v0

权与网: 图中边或弧所具有的相关数称为权(表明从一个顶点到另一个顶点的距离或耗费)。带权的图称为网。

连通分量(强连通分量)
极大连通子图意思是:该子图是 G 连通子图,将 G 的任何不在该子图中的顶点加入,子图不再连通。

极大强连通子图意思是:该子图是 G 的强连通子图,将 G 的任何不在该子图中的顶点加入,子图不再是强连通的。

极小连通子图: 该子图是G 的连通子图,在该子图中删除任何一条边子图都不再连通。
生成树: 包含无向图G 所有顶点的极小连通子图。
生成森林: 对非连通图,有各个连通分量的生成树的集合

二,邻接(Adjacency)
邻接: 有边 / 弧相连的两个顶点之间的关系。
互为邻接点;邻接到 vj,vj 邻接于 vi。2.1 列表表示(Adjacency-List)
可藉由 Adjacency-list 表示,将每一个相邻的点集合用一个List 存起來。
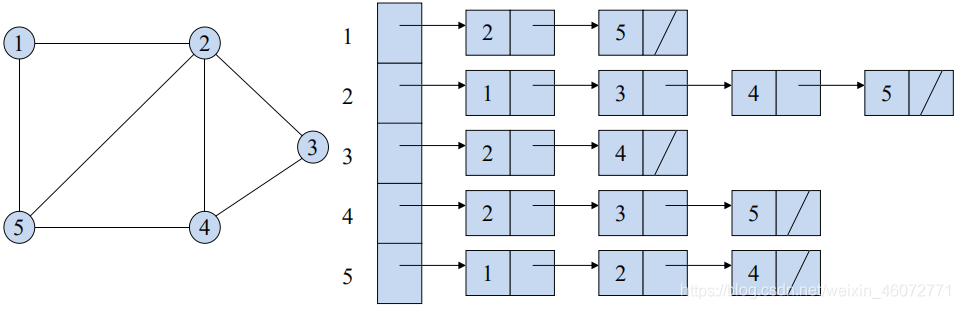
有向图
可藉由Adjacency-List表示,將每個點所指向的點集合存在List中。
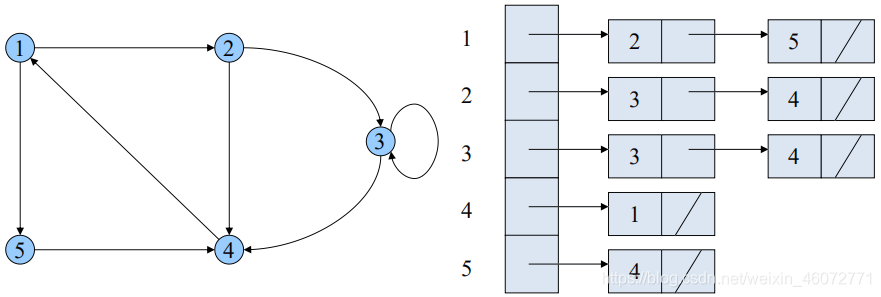
2.2 矩阵表示(Adjacency-Matrix)
可藉由 Adjacency-Matrix 表示,利用一個二維矩阵將每對點之間是否有邊連起來;

有向图
可藉由 Adjacency Matrix 表示,利用一個二維矩阵A

三,图的遍历

解决思路:设置辅助数组 visited[ n ],用来标记是否访问过该顶点
3.1 深度优先搜索(DFS)
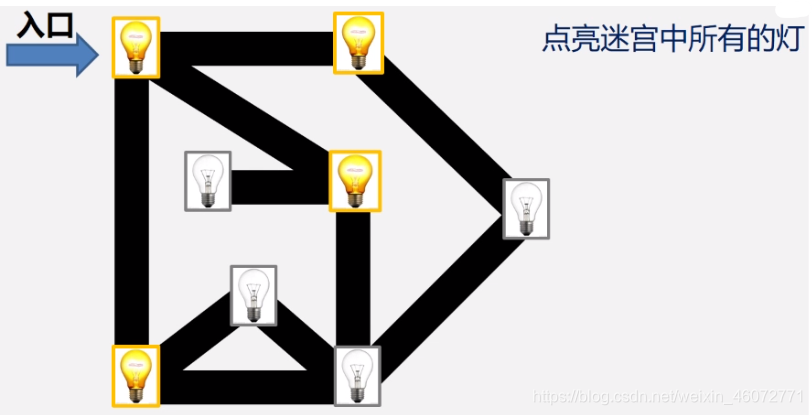
引例:点亮所有的灯
思路:选择一条路径,已知走到没有未点亮的灯或到尽头时再回头,每次退一步,若有未点亮的灯则选择该点,若没有未点亮的灯则再退回一步,直到所有灯全部都被点亮。
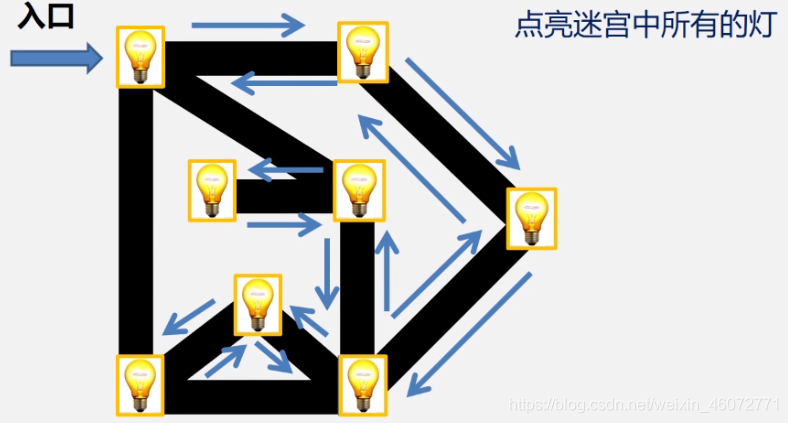
最初的选择不同,会有不同的访问路径。

3.1.1 深度优先搜索遍历算法的实现
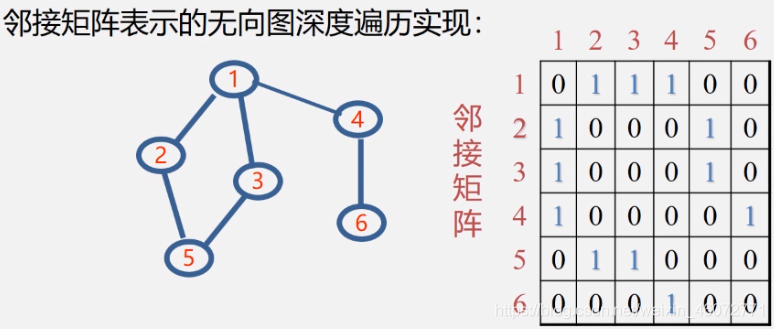
设置辅助数组 visited[ n ] = [ 0,0,0,0,0,0 ],分别对应每一个顶点 vi
然后来看邻接矩阵,只看 v2 这一行就可以,可以看出与 v1 相连,则我们走到顶点 v1(设置 visited[ 0 ] = 1;visited[ n ] = [ 1,1,0,0,0,0 ]);

void DFS(AMGraph G, int v){ //图G为邻接矩阵类型 cout<<v; //访问第v个顶点 visited[v] = true; //依次检查邻接矩阵v所在的行 for(w = 0; w < G.vexnum; w++) if((G.arcs[v][w] != 0)&&(!visited[w])) DFS(G, w), //w是v的邻接点,如果w未访问,则递归调用DFS } 3.1.2 DFS 算法效率分析
3.1.3 非连通图的遍历

以上图为例:
首先,以a为初始点(随机的),接下来按照上边的步骤依次找到邻接点直到全部都访问过(该连通分量已经遍历完成),因为我们知道是非连通图,则我们在没有访问过得顶点中再随机找一个顶点开始新的遍历。3.2 广度优先搜索(BFS)
与DFS不同,广度优先搜索是先选定一个初始点,然后访问他所有的邻接点,如下图所示
方法:

非连通图的广度遍历

3.2.1 实现和步骤

以上图为例:
visited[ n ] = [ 0,0,0,0,0,0,0,0 ] 用来记录顶点是否访问过,访问后设置 visited[ i ] = 1;
next[ n ] = [ -1,-1,-1,-1,-1,-1,-1,-1 ] 用来记录访问点的所有未访问邻接点;
visited[ n ] = [ 1,1,1,1,1,1,1,1 ]
next[ n ] = [ 1,2,3,4,5,6,7,8 ]3.2.2 BFS 算法及其效率
void BFS(Graph G, int v){ // 按广度优先非递归遍历连通图G cout<<v; // 访问第 v 个顶点 visited[v] = true; InitQueue(Q); // 辅助队列Q初始化,置空 EnQueue(Q, v); // v 进队 while(!QueueEmpty(Q)){ // 队列非空 DeQueue(Q, u); // 队头元素出队并置为 u for(w = FirstAdjVex(G,u);w >= 0;w = NextAdjVex(G, u, w)) if(!visited[w]){ // w 是 u尚未访问的邻接点 cout<<w; visited[w] = true; EnQueue(Q, w); // w 进队 }// }// }//
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









