kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。二者的整合,有主要的两大版本。
在spark-stremaing-kafka-0-8的版本中又分为了两种方式:receiver的方式和direct的方式来读取kafka中的数据,主要区别就是是否依赖zookeeper来管理offset信息,以及是否拥有receiver。 API查询地址:https://spark.apache.org/docs/2.2.2/streaming-kafka-0-8-integration.html 导入下面要用到的Maven依赖 这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。 然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。 需要注意的地方 数据会丢失原因 具体操作: 首先创建一个topic 启动消费者 Direct.scala 输入参数 运行代码 输入信息 结果 DirectCheckPoint.scala 输入参数 输出 Direct方式的特点: 输入参数 Direct.scala 输出 输入参数 DirectCheckPoint.scala 输出 确保集群HBase服务开启,拷贝hdfs-site.xml、core-site.xml、hbase-site.xml至当前目录 HBaseConnectionPool.java 运行,测试连接,看到如下输入则连接成功 流程: 手动从hbase中读取上一次消费的offset信息 使用指定offset从kafka中拉取数据 拉取到数据之后进行业务处理 指定HBase进行offset的更新 Table hadoop-topic-offset 建表语句 DirectWithHBase.scala 启动,然后在生产者中发送消息!! 结果如下 这里把前面整合HBase中用到的一些方法提取出来 KafkaManager.scala 以上是官网上对一致性语义的说明,大意是为了使获得的结果保持输出一致性语义,你用来保存结果和偏移量到外部数据存储的操作必须是幂等或者是原子事务。 幂等操作 创建测试的mysql数据库 建表 新建topic:mytopic 运行程序之后,向mytopic发送数据,数据格式为 “字符,数字” 比如 abc,3 KafkaOffsetIdempotent.scala 测试结果如下: 原子性操作 基于scala-jdbc的方式操作数据库 建表 插入数据 往mytopic发送数据, 数据格式为 “字符,数字” 比如 abc,3 KafkaOffsetTransaction.scala 测试结果如下: 初始的offset信息: 增加数据后可以看到,每个offset被增加了一 sparkstreaming要从kafka拉取数据,并进行处理;下一次再循环,如果批次的间隔时间为2s,但是数据的处理时间为3s,所以会有越来越多的没有被处理的数据进行累积,最后会拖垮程序,这不是我们所期望的。 解决思路,只能限制流量。非常简单,通过一个参数搞定:spark.streaming.kafka.maxRatePerPartition spark.streaming.kafka.maxRatePerPartition: spark程序每秒中从每个partition分区读取的最大的数据条数。比如batchInterval为2s,topic的分区为3,该参数的值为100,请问,每个批次最多可以读取多少条数据?2×3×100=600条。 只用在Direct.scala的基础上改一个参数即可 输入参数 DirectLimit.scala 可以看到结果(这里的参数大小适合有数据重复次数超过六百次的):
文章目录

<properties> <spark.version>2.2.2</spark.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-8_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>org.scalikejdbc</groupId> <artifactId>scalikejdbc_2.11</artifactId> <version>3.2.0</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.39</version> </dependency> <!-- <dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency>--> </dependencies> 一、Receiver方式
1.kafka基于receiver方式一

kafka-topics.sh --create --topic hadoop --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka --partitions 3 --replication-factor 3 kafka-console-producer.sh --topic hadoop --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 package blog.kafka import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @Author Daniel * @Description SparkStreaming基于Direct整合Kafka方式一 * **/ object Direct { def main(args: Array[String]): Unit = { if (args == null || args.length < 3) { println( """ |Usage: <broker.list> <groupId> <topicStr> """.stripMargin) System.exit(-1) } val Array(brokerList, groupId, topicStr) = args //direct中的参数为一个set集合 val topics = topicStr.split(",").toSet val conf = new SparkConf() .setAppName("Direct") //没有Receiver这里给一个就行 .setMaster("local") .set("spark.streaming.receiver.writeAheadLog.enable", "true") val batchInterval = Seconds(2) val kafkaParams: Map[String, String] = Map[String, String]( "metadata.broker.list" -> brokerList, "group.id" -> groupId, "auto.offset.reset" -> "smallest" ) val ssc = new StreamingContext(conf, batchInterval) val input: InputDStream[(String, String)] = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) val ret = input .flatMap(_._2.split("\s+")) .map((_, 1)) .reduceByKey(_ + _) ret.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") rdd.foreach(println) } }) ssc.start() ssc.awaitTermination() } } hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka bdedev-group-1 hadoop 


2.kafka基于receiver方式二——使用checkpoint
package blog.kafka import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @Author Daniel * @Description SparkStreaming基于Direct整合Kafka方式二——使用checkpoint * **/ object DirectCheckPoint { def main(args: Array[String]): Unit = { if (args == null || args.length < 3) { println( """ |Usage: <broker.list> <groupId> <topicStr> """.stripMargin) System.exit(-1) } val Array(brokerList, groupId, topicStr) = args val topics = topicStr.split(",").toSet val conf = new SparkConf() .setAppName("DirectCheckPoint") .setMaster("local") val batchInterval = Seconds(2) val kafkaParams: Map[String, String] = Map[String, String]( "metadata.broker.list" -> brokerList, "group.id" -> groupId, "auto.offset.reset" -> "smallest" ) val checkpoint = "file:///F:/ssdata/checkpoint/ck2" def creatingFunc(): StreamingContext = { val ssc = new StreamingContext(conf, batchInterval) //使用checkpoint来存储offset信息 保证数据被依次消费 ssc.checkpoint(checkpoint) val input: InputDStream[(String, String)] = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) input.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") println("------------------------rdd's count: " + rdd.count()) } }) ssc } val ssc = StreamingContext.getOrCreate(checkpoint, creatingFunc) ssc.start() ssc.awaitTermination() } } hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka bde-dev-group-2 hadoop 
二、Direct方式
上是效率低下的,因为数据被有效地复制了两次:一次是Kafka,另一次是由预先写入日志(Write
Ahead Log)复制。这个第二种方法消除了这个问题,因为没有接收器,因此不需要预先写入日志。
只要Kafka数据保留时间足够长。1.kafka基于direct方式一
hadoop01:9092,hadoop02:9092,hadoop03:9092 bde-dev-group-3 hadoop package blog.kafka import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @Author Daniel * @Description SparkStreaming基于Direct整合Kafka方式一 * **/ object Direct { def main(args: Array[String]): Unit = { if (args == null || args.length < 3) { println( """ |Usage: <broker.list> <groupId> <topicStr> """.stripMargin) System.exit(-1) } val Array(brokerList, groupId, topicStr) = args //direct中的参数为一个set集合 val topics = topicStr.split(",").toSet val conf = new SparkConf() .setAppName("Direct") //没有Receiver这里给一个就行 .setMaster("local") .set("spark.streaming.receiver.writeAheadLog.enable", "true") val batchInterval = Seconds(2) val kafkaParams: Map[String, String] = Map[String, String]( "metadata.broker.list" -> brokerList, "group.id" -> groupId, "auto.offset.reset" -> "smallest" ) val ssc = new StreamingContext(conf, batchInterval) val input: InputDStream[(String, String)] = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) val ret = input .flatMap(_._2.split("\s+")) .map((_, 1)) .reduceByKey(_ + _) ret.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") rdd.foreach(println) } }) ssc.start() ssc.awaitTermination() } } 
2.kafka基于direct方式二——使用checkpoint
hadoop01:9092,hadoop02:9092,hadoop03:9092 bde-dev-group-4 hadoop package blog.kafka import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @Author Daniel * @Description SparkStreaming基于Direct整合Kafka方式二——使用checkpoint * **/ object DirectCheckPoint { def main(args: Array[String]): Unit = { if (args == null || args.length < 3) { println( """ |Usage: <broker.list> <groupId> <topicStr> """.stripMargin) System.exit(-1) } val Array(brokerList, groupId, topicStr) = args val topics = topicStr.split(",").toSet val conf = new SparkConf() .setAppName("DirectCheckPoint") .setMaster("local") val batchInterval = Seconds(2) val kafkaParams: Map[String, String] = Map[String, String]( "metadata.broker.list" -> brokerList, "group.id" -> groupId, "auto.offset.reset" -> "smallest" ) val checkpoint = "file:///F:/ssdata/checkpoint/ck2" def creatingFunc(): StreamingContext = { val ssc = new StreamingContext(conf, batchInterval) //使用checkpoint来存储offset信息 保证数据被依次消费 ssc.checkpoint(checkpoint) val input: InputDStream[(String, String)] = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) input.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") println("------------------------rdd's count: " + rdd.count()) } }) ssc } val ssc = StreamingContext.getOrCreate(checkpoint, creatingFunc) ssc.start() ssc.awaitTermination() } } 
3.kafka基于direct方式三——使用HBase管理offset
package blog.util; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.HBaseAdmin; import java.io.IOException; /** * @Author Daniel * @Description 测试与HBase的连接 **/ public class TestConnect { public static void main(String[] args) throws IOException { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181"); Connection conn = ConnectionFactory.createConnection(conf); System.out.println(conn); } }
字段
注释
topic-group
行键(Rowkey)
cf
列族(Columns)
partition
分区
offset
偏移量
connection
连接
create 'hadoop-topic-offset', 'cf' package blog.kafka import blog.util.HBaseConnectionPool import kafka.common.TopicAndPartition import kafka.message.MessageAndMetadata import kafka.serializer.StringDecoder import org.apache.hadoop.hbase.TableName import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange} import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.JavaConversions._ import scala.collection.mutable /** * @Author Daniel * @Description SparkStreaming基于Receiver整合Kafka方式三——使用HBase管理offset **/ object DirectWithHBase { def main(args: Array[String]): Unit = { if (args == null || args.length < 3) { println( """ |Usage: <broker.list> <groupId> <topicStr> """.stripMargin) System.exit(-1) } val Array(brokerList, groupId, topicStr) = args val topics = topicStr.split(",").toSet val conf = new SparkConf() .setAppName("DirectWithHBase") .setMaster("local") val batchInterval = Seconds(2) val kafkaParams = Map[String, String]( "metadata.broker.list" -> brokerList, "group.id" -> groupId, "auto.offset.reset" -> "smallest" ) val ssc = new StreamingContext(conf, batchInterval) val input = createMsg(ssc, kafkaParams, topics) input.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") println("------------------------rdd's count: " + rdd.count()) //更新偏移量 storeOffsets(rdd.asInstanceOf[HasOffsetRanges].offsetRanges, kafkaParams("group.id")) } }) ssc.start() ssc.awaitTermination() } //保存偏移量 def storeOffsets(offsetRanges: Array[OffsetRange], group: String): Unit = { val connection = HBaseConnectionPool.getConnection val tableName = TableName.valueOf("hadoop-topic-offset") val cf = "cf".getBytes() for (offsetRange <- offsetRanges) { val rk = s"${offsetRange.topic}-${group}".getBytes() val partition = offsetRange.partition //偏移量 val offset = offsetRange.untilOffset //将结果保存到Hbase中 HBaseConnectionPool.set(connection, tableName, rk, cf, (partition + "").getBytes(), (offset + "").getBytes()) } HBaseConnectionPool.release(connection) } def createMsg(ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String]): InputDStream[(String, String)] = { //从zookeeper中读取偏移量 val offsets = getOffsets(topics, kafkaParams("group.id")) var messages: InputDStream[(String, String)] = null if (offsets.isEmpty) { //如果为空就从0开始读取 messages = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) } else { //有值就从指定的offset位置开始读取 val messageHandler = (msg: MessageAndMetadata[String, String]) => (msg.key(), msg.message()) messages = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, offsets, messageHandler) } messages } /** * create 'hadoop-topic-offset', 'cf' * rowkey * topic-group * * @return offsets */ def getOffsets(topics: Set[String], group: String): Map[TopicAndPartition, Long] = { val offsets = mutable.Map[TopicAndPartition, Long]() //获取连接 val connection = HBaseConnectionPool.getConnection //拿到HBase中的表名 val tableName = TableName.valueOf("hadoop-topic-offset") //数据库中的列族名 val cf = "cf".getBytes() for (topic <- topics) { //行键 val rk = s"${topic}-${group}".getBytes() //获取分区与偏移量信息 val partition2Offsets = HBaseConnectionPool.getColValue(connection, tableName, rk, cf) partition2Offsets.foreach { case (partition, offset) => { offsets.put(TopicAndPartition(topic, partition), offset) } } } HBaseConnectionPool.release(connection) offsets.toMap } } 
三、Spark Streaming与Kafka整合的常见问题
package blog.kafka import kafka.common.TopicAndPartition import kafka.message.MessageAndMetadata import kafka.serializer.StringDecoder import org.apache.curator.framework.CuratorFramework import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.{KafkaUtils, OffsetRange} import scala.collection.JavaConversions._ import scala.collection.mutable /** * @Author Daniel * @Description Utils * 将前面整合HBase的一些方法抽取出来 **/ object KafkaManager { //保存偏移量 def storeOffsets(offsetRanges: Array[OffsetRange], group: String, curator: CuratorFramework): Unit = { for (offsetRange <- offsetRanges) { val topic = offsetRange.topic val partition = offsetRange.partition val offset = offsetRange.untilOffset val path = s"${topic}/${group}/${partition}" checkExists(path, curator) curator.setData().forPath(path, new String(offset + "").getBytes()) } } def createMsg(ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String], curator: CuratorFramework): InputDStream[(String, String)] = { //从zookeeper中读取offset val offsets: Map[TopicAndPartition, Long] = getOffsets(topics, kafkaParams("group.id"), curator) var messages: InputDStream[(String, String)] = null if (offsets.isEmpty) { //为空则从0开始读取 messages = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) } else { //有就从指定位置开始读取 val messageHandler = (msgH: MessageAndMetadata[String, String]) => (msgH.key(), msgH.message()) messages = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, offsets, messageHandler) } messages } def getOffsets(topics: Set[String], group: String, curator: CuratorFramework): Map[TopicAndPartition, Long] = { val offsets = mutable.Map[TopicAndPartition, Long]() for (topic <- topics) { val parent = s"${topic}/${group}" checkExists(parent, curator) //此时目录一定存在 for (partition <- curator.getChildren.forPath(parent)) { val path = s"${parent}/${partition}" val offset = new String(curator.getData.forPath(path)).toLong offsets.put(TopicAndPartition(topic, partition.toInt), offset) } } offsets.toMap } //检测是否存在 def checkExists(path: String, curator: CuratorFramework): Unit = { if (curator.checkExists().forPath(path) == null) { //不存在则创建 curator.create().creatingParentsIfNeeded() .forPath(path) } } } 1.输出一致性语义的问题

create database db1; create table myorders(name varchar(20), orderid varchar(100) primary key); kafka-topics.sh --zookeeper hadoop01:2181/kafka --create --topic mytopic --partitions 3 --replication-factor 1 kafka-console-producer.sh --topic mytopic --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 package blog.kafka import java.sql.DriverManager import org.apache.curator.framework.CuratorFrameworkFactory import org.apache.curator.retry.ExponentialBackoffRetry import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka.HasOffsetRanges import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @Author Daniel * @Description 幂等处理 **/ object KafkaOffsetIdempotent { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf() .setAppName("KafkaOffsetIdempotent") .setMaster("local[2]") val processingInterval = 2 val brokers = "hadoop01:9092,hadoop02:9092,hadoop03:9092" val topic = "mytopic" // Create direct kafka stream with brokers and topics val topicsSet = topic.split(",").toSet val kafkaParams = Map[String, String]( "metadata.broker.list" -> brokers, "auto.offset.reset" -> "smallest", "group.id" -> "myspark" ) val ssc = new StreamingContext(sparkConf, Seconds(processingInterval)) val messages = KafkaManager.createMsg(ssc, kafkaParams, topicsSet, client) val jdbcUrl = "jdbc:mysql://localhost:3306/db1" val jdbcUser = "root" val jdbcPassword = "root" messages.foreachRDD(rdd => { if (!rdd.isEmpty()) { rdd.map(x => x._2).foreachPartition(partition => { //拿到connection val dbConn = DriverManager.getConnection(jdbcUrl, jdbcUser, jdbcPassword) partition.foreach(msg => { //按照格式切割 val name = msg.split(",")(0) val orderid = msg.split(",")(1) //幂等操作:如果主键相同,则覆盖这个结果 val sql = s"insert into myorders(name, orderid) values ('$name', '$orderid') ON DUPLICATE KEY UPDATE name='${name}'" val pstmt = dbConn.prepareStatement(sql) //执行SQL pstmt.execute() }) dbConn.close() }) //将数据保存到偏移量 KafkaManager.storeOffsets(rdd.asInstanceOf[HasOffsetRanges].offsetRanges, kafkaParams("group.id"), client) } }) ssc.start() ssc.awaitTermination() } //构建一个Curator的Client val client = { val client = CuratorFrameworkFactory.builder() .connectString("hadoop01:2181,hadoop02:2181,hadoop03:2181") .retryPolicy(new ExponentialBackoffRetry(1000, 3)) .namespace("kafka/consumers/offsets") .build() client.start() client } } 

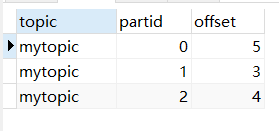
create table mytopic(topic varchar(200), partid int, offset bigint); create table mydata(name varchar(200), id int); insert into mytopic(topic, partid, offset) values('mytopic',0,0); insert into mytopic(topic, partid, offset) values('mytopic',1,0); insert into mytopic(topic, partid, offset) values('mytopic',2,0); package blog.kafka import kafka.common.TopicAndPartition import kafka.message.MessageAndMetadata import kafka.serializer.StringDecoder import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, TaskContext} import scalikejdbc.{ConnectionPool, DB, _} /** * @Author Daniel * @Description 原子处理 * 将偏移量存储在事务里面 **/ object KafkaOffsetTransaction { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setAppName("test").setMaster("local[2]") val processingInterval = 2 val brokers = "hadoop01:9092,hadoop02:9092,hadoop03:9092" val topic = "mytopic" // Create direct kafka stream with brokers and topics topic.split(",").toSet val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers, "auto.offset.reset" -> "smallest" ) val ssc = new StreamingContext(sparkConf, Seconds(processingInterval)) //相关配置信息 val driver = "com.mysql.jdbc.Driver" val jdbcUrl = "jdbc:mysql://localhost:3306/db1" val jdbcUser = "root" val jdbcPassword = "root" // 设置jdbc Class.forName(driver) // 设置连接池 ConnectionPool.singleton(jdbcUrl, jdbcUser, jdbcPassword) //隐式转换参数 val fromOffsets = DB.readOnly { implicit session => sql"select topic, partid, offset from mytopic". //r就是ResultSet结果集 map { r => //topic partition offset TopicAndPartition(r.string(1), r.int(2)) -> r.long(3) }.list .apply() .toMap //转换结果类型 } val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.topic, mmd.message()) val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler) messages.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") rdd.foreachPartition(partition => { //偏移量 val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //某个分区所对应的偏移量 val pOffsetRange = offsetRanges(TaskContext.get.partitionId) // scala中使用localTx 开启事务操作 DB.localTx { implicit session => //数据 partition.foreach(msg => { // 或者使用scalike的batch 插入 val name = msg._2.split(",")(0) val id = msg._2.split(",")(1) sql"""insert into mydata(name,id) values (${name},${id})""".execute().apply() }) // val i = 1 / 0//测试,若发生错误,则更新失败,进行事务的回滚操作 //偏移量 sql"""update mytopic set offset = ${pOffsetRange.untilOffset} where topic = ${pOffsetRange.topic} and partid = ${pOffsetRange.partition}""".update.apply() } }) } }) ssc.start() ssc.awaitTermination() } } 


2.限流的处理
hadoop01:9092,hadoop02:9092,hadoop03:9092 bde-dev-group-5 hadoop package blog.kafka import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @Author Daniel * @Description 限流处理 * **/ object DirectLimit { def main(args: Array[String]): Unit = { if (args == null || args.length < 3) { println( """ |Usage: <broker.list> <groupId> <topicStr> """.stripMargin) System.exit(-1) } val Array(brokerList, groupId, topicStr) = args //direct中的参数为一个set集合 val topics = topicStr.split(",").toSet val conf = new SparkConf() .setAppName("DirectLimit") //没有Receiver这里给一个就行 .setMaster("local") //设置spark程序每秒中从每个partition分区读取的最大的数据条数 .set("spark.streaming.kafka.maxRatePerPartition", "100") val batchInterval = Seconds(2) val kafkaParams: Map[String, String] = Map[String, String]( "metadata.broker.list" -> brokerList, "group.id" -> groupId, "auto.offset.reset" -> "smallest" ) val ssc = new StreamingContext(conf, batchInterval) val input: InputDStream[(String, String)] = KafkaUtils .createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) val ret = input .flatMap(_._2.split("\s+")) .map((_, 1)) .reduceByKey(_ + _) ret.foreachRDD((rdd, time) => { if (!rdd.isEmpty()) { println(s"Time: $time") rdd.foreach(println) } }) ssc.start() ssc.awaitTermination() } } 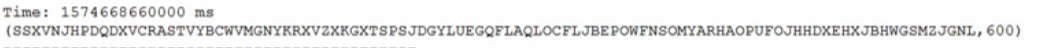
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









