说起集合,算是三顾茅庐了,在我初学Java的时候,曾接触过集合,那个时候只会用像Collection接口下的List(ArrayList、Vector、LinkedList)和Set(HashSet、TreeSet)还有Map接口下的HashMap,当时只是会用,第二次学习集合是看到了网上一些大佬的文章,感觉自己差的太多,然后又了解了一点LinkedHashSet、TreeMap、HashTable的知识,直到今天的第三次,我意识到了集合和多线程之间的关系,这篇文章主要是把集合的知识点串起来,并加入并发下的集合问题。 ArrayList是List集合的一个实现类,其底层实现是数组 Vector也是List的一个实现类,其底层也是一个数组 既然不建议使用Vector,那么并发的时候怎么办呢,不要忘了,有一个包java.util.concurrent(JUC)包,它下面有一个类CopyOnWriteArrayList也是线程安全的。CopyOnWriteArrayList也是List的一个实现类。 底层数据结构 默认初始化容量
文章目录
概述
List
List集合的底层是数组和链表,其存储顺序是有序的。ArrayList
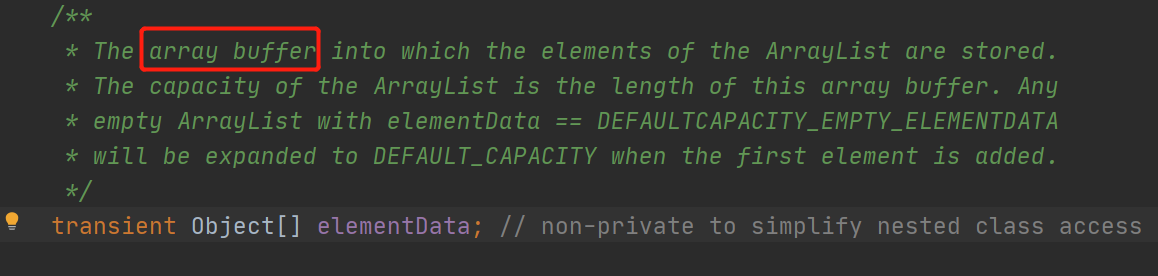
transient Object[] elementData;,数组的查询是直接通过索引,查询速度比较快,时间复杂度是O(1),增删的话,根据增删的位置,时间复杂度有所不同,如果是中间第i个位置,时间复杂度就是O(n-i),简单理解其时间复杂度是O(n),举个例子,一个有8个元素的数组,要在第6个位置插入元素,那么,需要把后2个元素往后移,来保证原来的顺序不变,其空间复杂度的话,为了防止数组越界,尾部会有一部分的空闲空间。
默认初始化容量
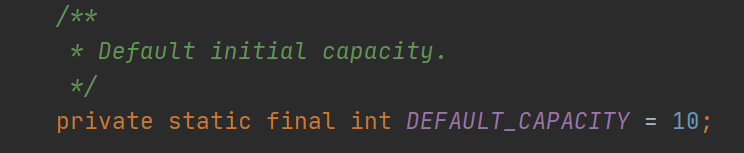
当构造方法中没有指定数组的大小时,其默认初始容量是10。
扩容机制
既然默认值是10,那么当超过这个默认值的时候,一定有一个扩容机制,其扩容机制是,当集合中元素的个数大于集合容量的时候,也就是add的时候集合放不下了,就会触发扩容机制,扩容后的新集合容量是旧集合容量的1.5倍,源码:int newCapacity = oldCapacity + (oldCapacity >> 1);。
线程问题
ArrayList是线程不安全的,在add()方法的时候,首先会检查一下数组的容量是否够用,如果够用,那么就会执行elementData[size++] = e;方法,该语句执行了两大步,第一大步是,将e放到elementData缓冲区,第二大步是,将size的大小进行加1操作,也就是说,这个操作并非原子性操作。当在并发的情况时,就会出现问题。import java.util.ArrayList; import java.util.List; public class Main { public static void main(String[] args) { List<String> list = new ArrayList<>(); for (int i = 0; i < 100; i++) { new Thread(()->{ for (int j = 0; j < 10; j++) { list.add("执行添加元素操作"); } }).start(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(list.size()); } } 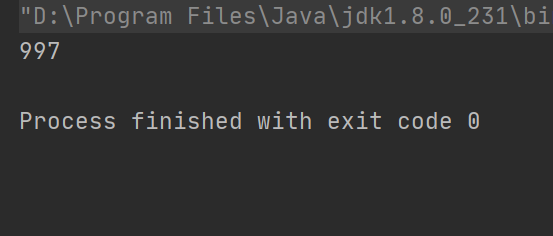
LinkedList
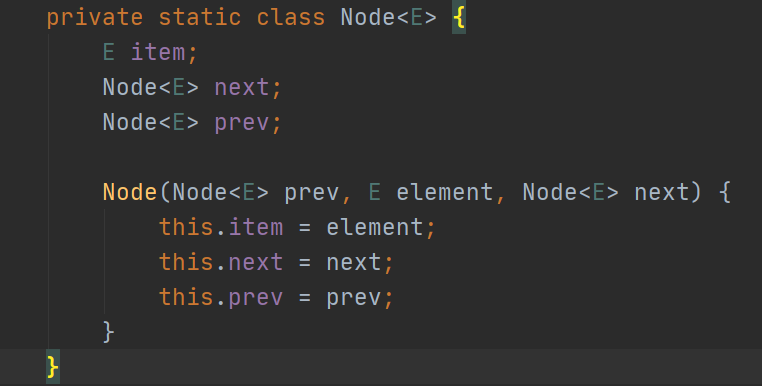
LinkedList也是List的一个实现类,其底层是双向链表,其内部有一个next指针指向下一个节点,一个prev指针,指向上一个节点,由于是链表的数据结构,所以在查询的时候相对就比较慢了,时间复杂度是O(n),因为当我们需要查询某个元素的时候,需要从第一个节点开始遍历,直到查询结束。而他的增删就比较快了,如果增加一个N节点,直接将后一个节点的prev指向N节点,N节点的next指向后一个节点,前一个节点的next指向N节点,N节点的prev指针指向前一个节点即可,时间复杂度为O(1),空间复杂度一般比ArrayList大,因为每个节点都要存储两个指针。
线程问题
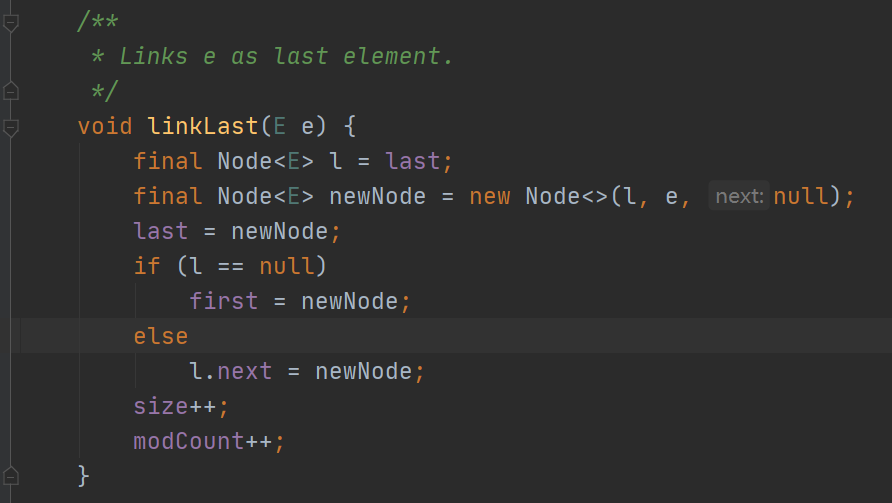
LinkedList也是线程不安全的,其添加元素的操作,通过linklast方法在尾部进行添加的,添加完之后,并把size的大小加1。其他的不说,单单一个size++就不是原子性了。
下面一个例子来演示加1操作。import java.util.LinkedList; import java.util.List; public class Main { static int a = 0; public static void main(String[] args) throws InterruptedException { List<String> list = new LinkedList<>(); for (int i = 0; i < 100; i++) { new Thread(()->{ for (int j = 0; j < 100; j++) { a ++; } }).start(); } Thread.sleep(1000);// 主线程延迟是为了保证那100线程先执行完 System.out.println(a); } } 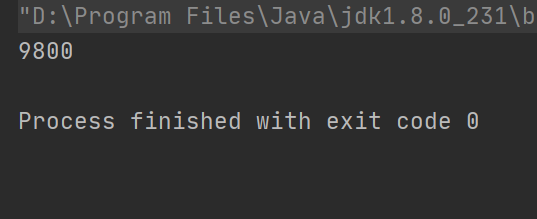
通过反编译下面的代码,来分析加1操作public class Main { public static void main(String[] args) { int a = 0; a ++; } } 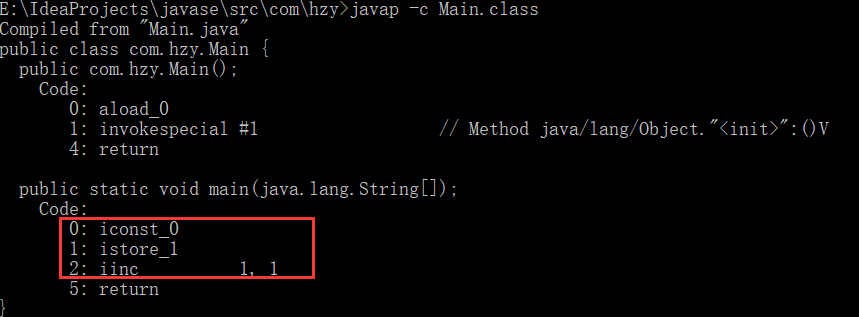
简单的加1操作会执行三步:
0:把a的值加载到内存
1:将内存中的值,存储到变量中
2:然后进行加1操作
兜了一大圈子,记住一句话,LinkedList是线程不安全的。Vector
protected Object[] elementData;,底层ArrayList差不多,也就是加了synchronized的ArrayList,线程是安全的,效率没有ArrayList高,一般不建议使用。
默认初始化容量
扩容机制

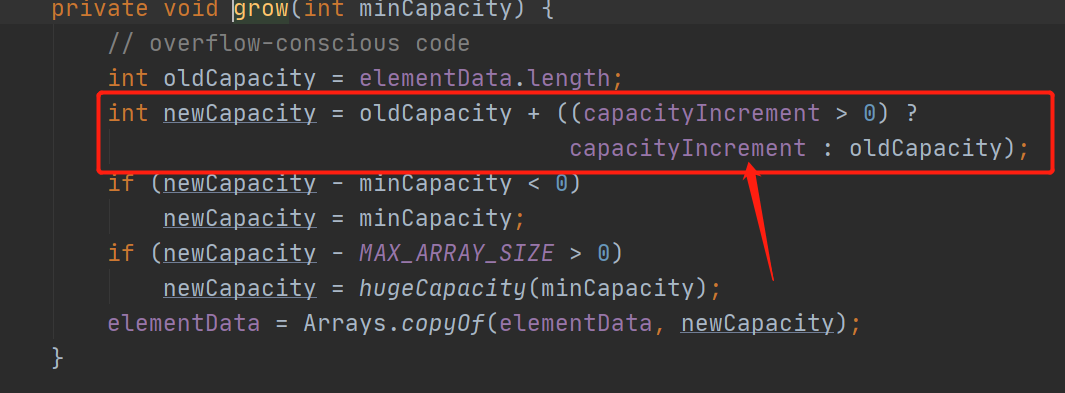
这里的扩容机制是通过capacityIncrement参数来实现的。
线程问题
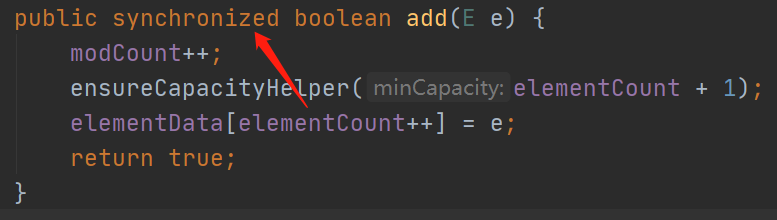
线程是安全的,因为它用了synchronized关键字,将整个方法进行了包裹,所以效率比较低,不建议使用。import java.util.Vector; public class Main { public static void main(String[] args) throws InterruptedException { Vector<String> vector = new Vector<>(); new Thread(()->{ for (int i = 0; i < 100; i++) { for (int j = 0; j < 10; j++) { vector.add("添加元素"); } } }).start(); Thread.sleep(1000);// 避免主线程先执行输出 System.out.println(vector.size()); } } 
CopyOnWriteArrayList
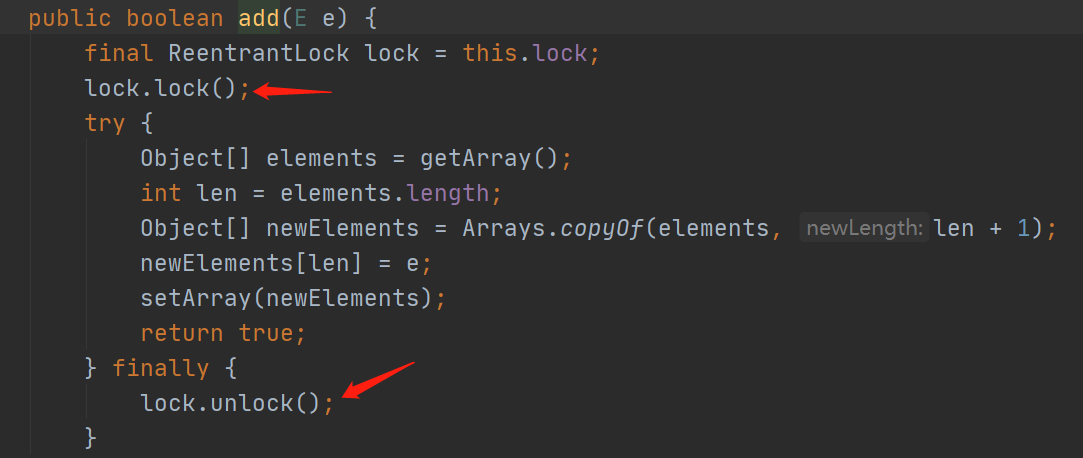
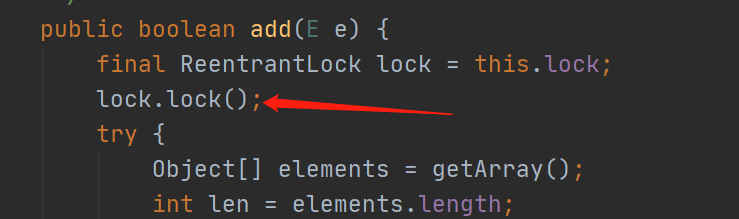
add方法用Lock锁来解决并发问题,其中在进行添加数据的时候,可以看到,用了copyOf方法,也就是复制了一份,然后再set进去。
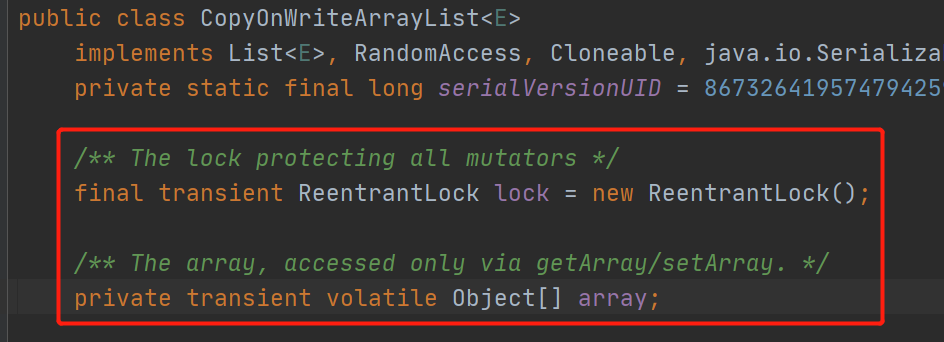
CopyOnWriteArrayList底层也是用的数组,但是它的数组是用volatile修饰了,主要是保证了数据的可见性。
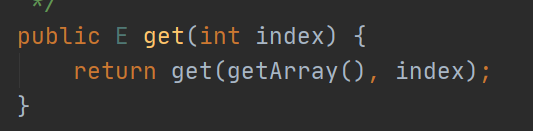
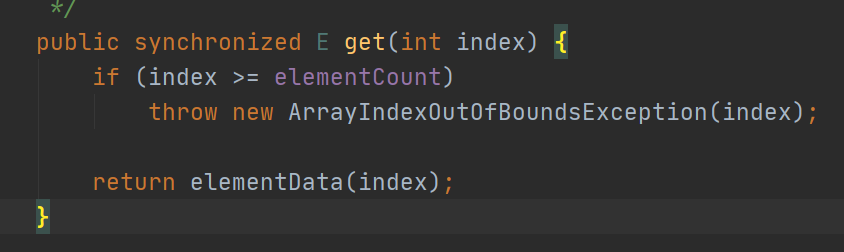
上图是CopyOnWriteArrayList的get操作,并没有加锁,因为volatile保证了数据的可见性,当数据被修改的时候,读操作能立刻知道。
而vector的get操作加了锁,所以效率肯定就没有CopyOnWriteArrayList高。import java.util.List; import java.util.concurrent.CopyOnWriteArrayList; public class Main { public static void main(String[] args) throws InterruptedException { List<String> list = new CopyOnWriteArrayList<>(); new Thread(()->{ for (int i = 0; i < 100; i++) { for (int j = 0; j < 10; j++) { list.add("添加元素"); } } }).start(); Thread.sleep(1000);// 避免主线程先执行输出 System.out.println(list.size()); } } 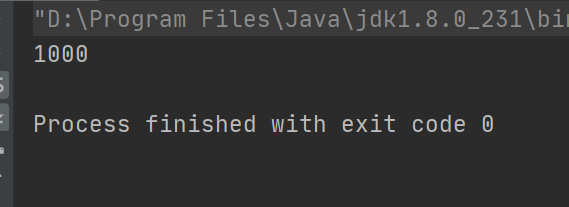
Set
Set集合中的元素是唯一的,不能有重复的元素。HashSet
HashSet是Set集合的一个实现类,其底层实现是HashMap的key,后面会详细讲解HashMap。不保证数据的存储顺序(即存的顺序和取的顺序不一定一样)。其线程不安全。LinkedHashSet



LinkedHashSet的初始容量也是16,默认加载因子也是0.75,继承了HashSet,底层基于LinkedHashMap,有一个维护顺序的双向链表,使得LinkedHashSet有序(存取有序)。其线程不安全。TreeSet
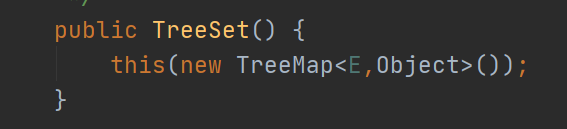
可以看出TreeSet是基于TreeMap的。它是有序的,是数值有顺序,通过树来维护的。其线程不安全。CopyOnWriteArraySet
import java.util.concurrent.CopyOnWriteArraySet;
这个是并发包下的,线程安全。
说了这么多Set集合,感觉大多都是基于Map的,接下来看看Map到底是怎么实现的!Map
HashMap
底层是JDK1.7是通过数组+链表JDK1.8是通过数组+链表+红黑树组成。所有的数据都是通过一个Node节点进行封装,其中Node节点中封装了hash值,key,value,和next指针。hash是通过key计算出的hashCode值进行对数组容量减一求余得到的(官方的求余方式是通过&运算进行的)。不同的key计算出来的hash值可能相同,解决冲突是通过拉链法(链表和红黑树)进行处理。正是因为这种存储形势,所以HashMap的存取顺序是无序的。
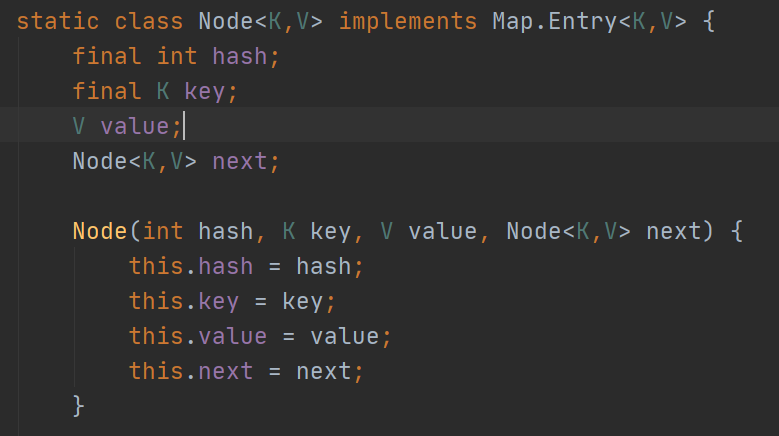
HashMap的底层是通过Node节点来维护的。

HashMap是Map的一个实现类,其默认初始化容量大小是16。
扩容机制
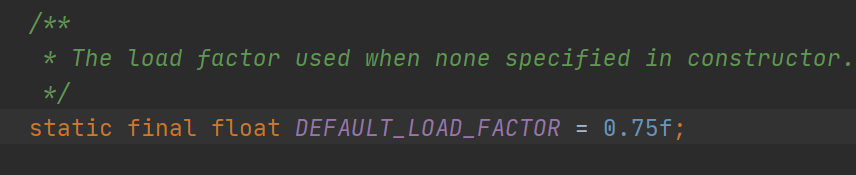
扩容机制是根据扩容因子来扩容的,当容量的使用量达到总容量的0.75时,就会触发扩容,举例说就是,当总容量是16时,使用量达到12,就会触发扩容机制。

扩容的新空间大小时就空间的2倍。
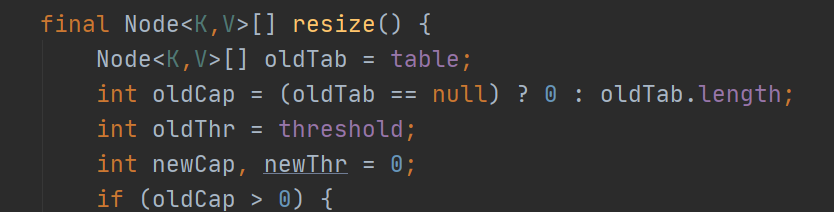
扩容操作最消耗性能的地方就是,原数组中的数据要重新存放,也就是resize(),即重新计算索引,重新分配。
处理冲突


当我们put一个值的时候,通过key来计算出hash值,计算出来的hash值做为数组的索引,Node节点中封装了hash值,key,value和next。


当链表的长度小于8的时候,处理冲突的方式是链表。大于等于8的时候,就会触发红黑树方式存储。
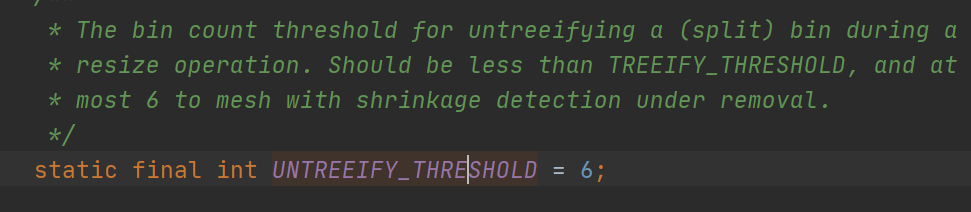

当元素个数小于等于6的时候,会触发红黑树转化为链表的形式,为什么不是小于等于7,是因为给一个过度,也就是防止添加一个刚好为8,删除一个刚好为7,这样来回转化。
线程问题
HashMap是线程不安全的。LinkedHashMap
LinkedHashMap继承了HashMap
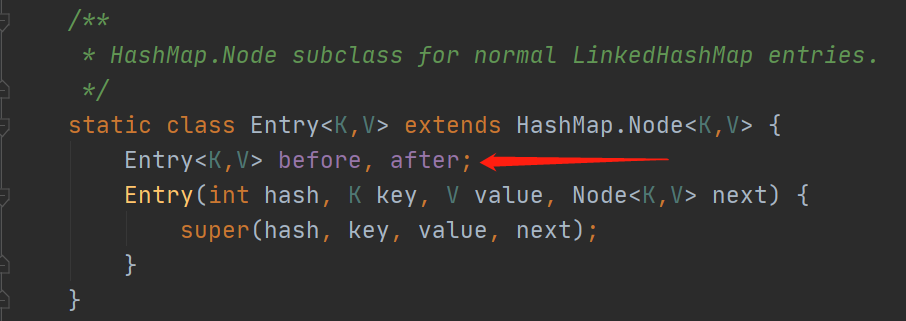
LinkedHashMap解决了HashMap不能保证存取顺序的问题。内部增加了一个链表用于维护元素存取顺序。Hashtable
Hashtable也是Map的一个实现类。
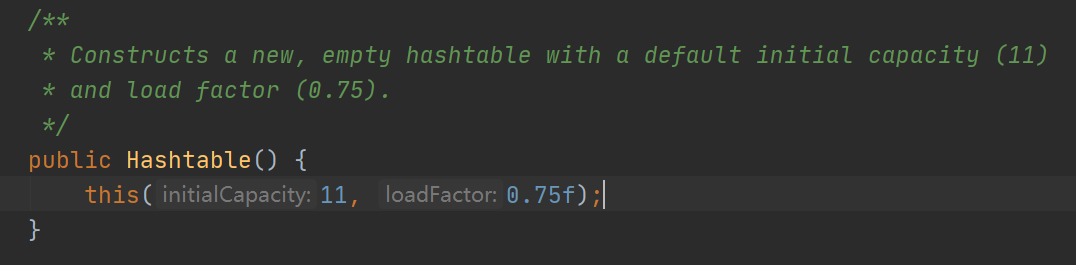
Hashtable的初始默认容量是11,扩容阈值也是0.75。
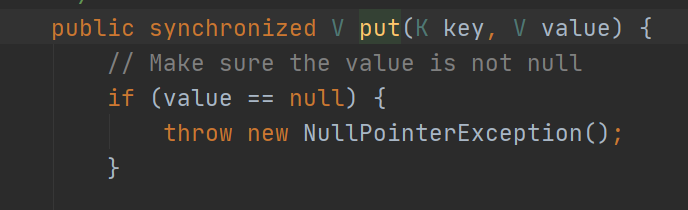
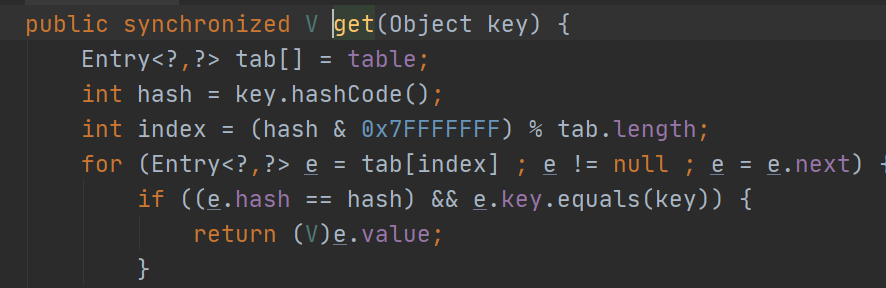
该类的出现主要是解决了HashMap的线程安全问题,直接用了synchronized锁,所以效率上不高,不建议使用(发现JDK1.0的线程问题,解决都很暴力)。TreeMap

TreeMap也是Map的一个实现类
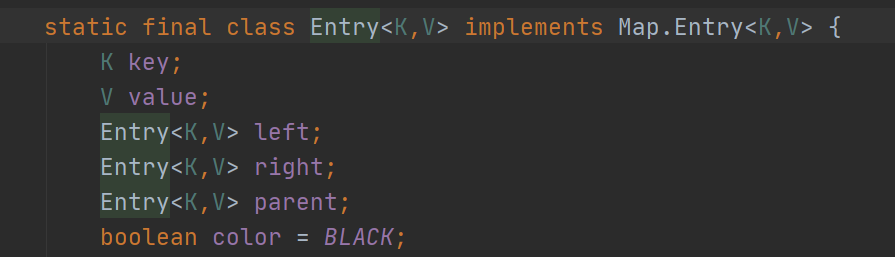
其底层是通过红黑树实现的,所以有序,这里的有序不是指存取顺序,而是数据大小的顺序。ConcurrentHashMap

ConcurrentHashMap是java.util.concurrent包下的,并发包下的。他就是对HashMap进行了一个扩展,也就是解决了他的线程安全问题。
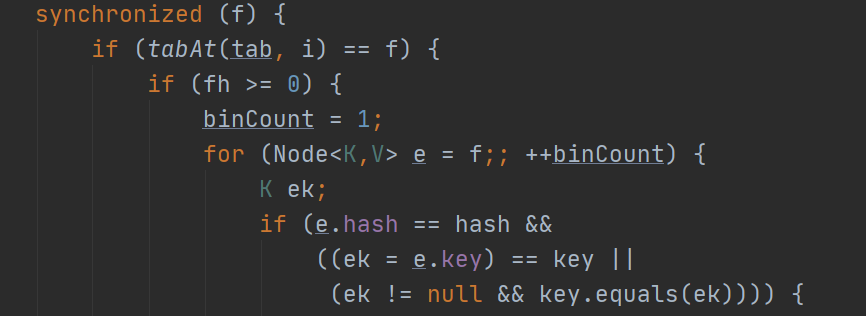
可以看到,锁的力度明显比Hashtable的小,其内部还用了很多的final、volatile和CAS的思想,如果想要学习多线程和并发编程的可以看我这篇文章https://blog.csdn.net/HeZhiYing_/article/details/105943962。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 4109
4109