俗话说,熟读唐诗三百首,不会吟诗也会吟’,请分析附件的唐诗300首文本文件。 统计每首诗歌的作者,如果第一行输入‘作者’,第二行则输入一个整数n,输出出现最多的作者前n个,每行输出一个名字和出现次数,以空格间隔,程序结束 统计出现的人名,如果第一行输入‘人物’,第二行则输入一个整数n,输出出现最多的人名前n个,每行输出一个名字和对应出现次数,以空格间隔,程序结束 如果输入某个字符串编号,范围和格式在“010-320之间(测试用例保证编号存在),输出对应该编号的诗句。 如果输入‘唐诗,输出文件中的诗词数量,程序结束 飞花令,如果第一行输入飞花,则可以在第二行输入中文字符(长度为1),然后按照在文件中出现的顺序,输出唐诗300首文件包含该中文字符的诗句(长度不超过7的诗句),每行一句。 如果非以上输入,输出‘输入错误’,程序结束 其实每一步难点地方都有写注释,涉及到的知识点都可以拓展的讲,例如 以上涉及的点均是写python以来习惯使用的东西,仅关于python的点有些能提高代码速度,请多多熟悉使用~
python+jieba分析唐诗三百首
代码及源文件地址:poem_300代码保证符合命名规范、遵循PEP8规则、导包顺序清晰、尽量做到复用性和不罗嗦如果有帮到您,还请给个评论或star~ 蟹蟹
1.题目描述:
完成下列功能:(部分功能需要使用jieba第三方库)
注:有的诗人在诗名或诗句中用到了别的诗人的名字。如“梦李白二首之一”。因此第1、2项目之间的数据可能有所差异。
输出格式:去掉首行诗歌编号,其余格式与文件中诗歌显示格式相同。2.细节分析
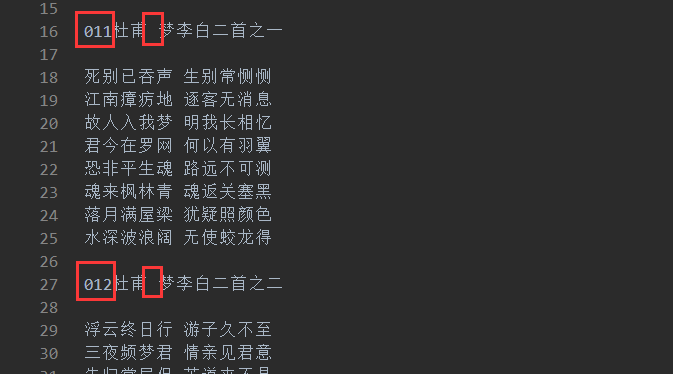
观察源文件规律,发现作者名都在三个数字字符和一个空格之间出现:
因此正则表达式用r'd{3}(.+?) '模式匹配,d{3}代替三个数字字符,(.+?)是我们要发现的部分,为什么用.+?而不是.*,前者是惰性匹配(加个?号),若是011杜甫 梦李白二首之一 测试,不用惰性匹配,就会找到杜甫 梦李白二首之一,使用惰性匹配只会匹配到杜甫(第一个空格前的内容,理解成尽可能少即可)
参考地址: Python 正则表达式
主要将第一步骤的代码复用、拿到作者清单,然后将古诗全文当作一个大的字符串,用jieba切词之后判断出是作者的词,这里代码罗嗦了一下,有两条没用的判断条件(我在等若要的是诗句中非作者的话,我就重新修改判断逻辑)
这个参考第一步骤的正则匹配,本题的思路是匹配传进来的三个数字字符和其他三个数字字符之间的内容(惰性匹配),然后再去掉一个空格两个换行符即可:

但是有个特殊情况—— 最后一首诗,应该改成传入的三个数字字符串和文件结尾之间的内容,然后再去掉换行符

数目的话根据第一步骤的作者的数目即可(不要去重,有些诗共同拥有一位作者!)
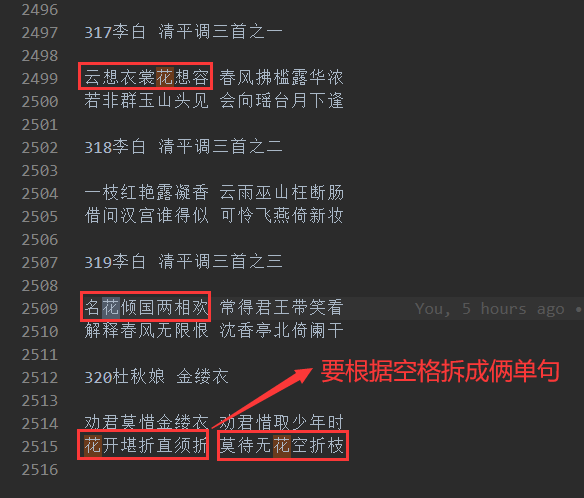
这里需要注意的点是if not bool(re.search(r'd', item))来判断非诗名的行和将诗句根据空格拆分成单句然后再判断含有某个中文字符的句子即可。
函数总入口
根据题目的描述,需要注意几点:
唐诗和输入错误,一个给if flag == ’唐诗‘,一个留到最后给else:即可3.代码分析
因为代码有问题可能随时修改push进仓库了,但是文章可能没法因为代码改了两行就重新编辑,耗时耗力,因此不会在文章贴出全部代码,讲解的话,根据看客需求吧。
read_poem_file()函数,将诗句源文件作简单处理后赋值给ori_data_list,可以看出,结果是个列表。if __name__ == "__main__": ori_data_list = read_poem_file(POEM_FILE) route(ori_data_list) read_poem_file()函数用with语句打开诗句源文件,顺带提一句,用with语句打开文件,不用自己考虑什么时候关闭文件,会自动处理;def read_poem_file(path): '''读取文件去除换行符,转换为列表 ''' with open(path, mode='r', encoding='utf-8') as poem_file: content = poem_file.readlines() clear_content_list = [x.strip() for x in content if x.strip() != ''] # 去除换行符、空字符 return clear_content_list
若输入"作者",还要用变量n来接收一个代表几位作者的整数,因为input()接收进来的值是字符串,这里需要用int()转换为整数,接着调用count_authors()函数,将ori_data和n塞进去,这里的ori_data就是上一步骤的ori_data_list,只不过进来之后名字变了;
以此类推,输入其他的就调用其他的函数;
我们还可以发现,有两处exit()退出函数,分别对应题目中输入”唐诗”和输入错误的情况;
判断语句结束后再次调用route()函数它自己,以达成每次输入完成回到主路由的功能,另外,这个不能称作递归函数。def route(ori_data): '''函数入口判断 ''' flag = input('') if flag == "作者": n = int(input('')) count_authors(ori_data, n) # 统计作者姓名频次 elif flag == "人物": n = int(input('')) count_names(n) # 统计人物姓名频次 elif flag == "唐诗": count_poems(ori_data) # 统计唐诗数量 exit() # 结束 elif flag == "飞花": s = str(input('')) poem_rhythm(ori_data, key_character=s) # 输出飞花令诗句 elif flag.isdigit() and len(flag) == 3: show_poem(flag) # 输出对应编号古诗 else: print("输入错误") exit() # 结束 route(ori_data) # 每次输入完成将重新回到主路由
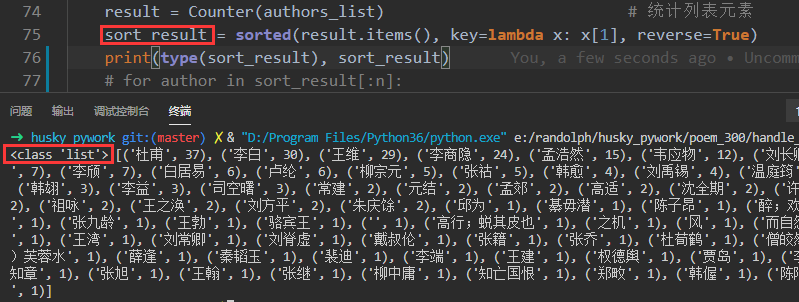
def count_authors(data, n): '''统计作者及频次排行 应网友要求,不用正则匹配,也可以获取全量作者 第一个for循环中,注释了的三行和接下来的两行代码效果相同 ''' authors_list = [] sen = [] for item in data: # if bool(re.search(r'd', item)): # 搜索包含数字的行 # local = re.findall(r'd{3}(.+?) ', item) # 惰性匹配 # authors_list.append(local[0]) # 将字符串空格去掉后,判断是否全为字符,不全是字符,则说明包含数字,则取到数字和作者这行 if not item.replace(' ', '').isalpha(): authors_list.append(item.split(' ')[0][3:]) # 用空格切分字符串后从第三个字符取导最后即为姓名 result = Counter(authors_list) # 统计列表元素 sort_result = sorted(result.items(), key=lambda x: x[1], reverse=True) # 排序 for author in sort_result[:n]: author_info = list(author) print(author_info[0], author_info[1])
sort_result = sorted(result.items(), key=lambda x: x[1], reverse=True)表达式左边是排序结果,右边是sorted()函数,python内置的,用来给可迭代对象排序,第一个参数是result.items(),是列表authors_list统计后的对象,我打印了这个对象的类型

经过排序后被转换成了列表对象sort_result:
然后用for循环取前n个打印出来即可,这个操作完成后就会回到路由函数,出if条件就开始调用路由函数自己,又回到了最开始,不详述了,都是基础。
4.测试案例
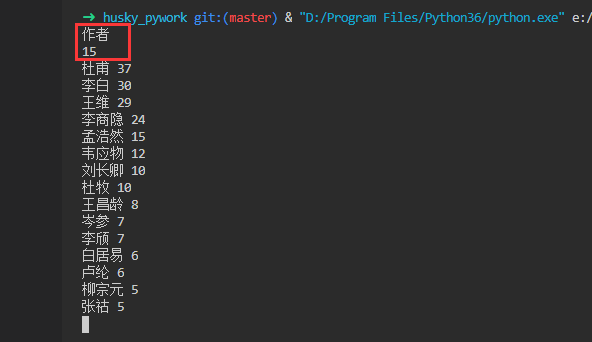


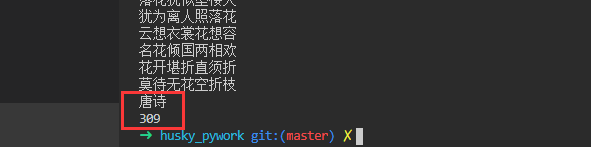
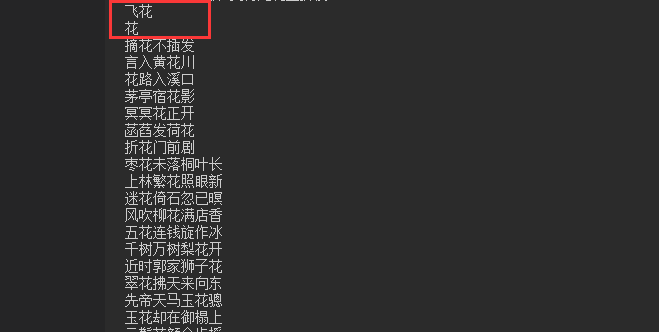
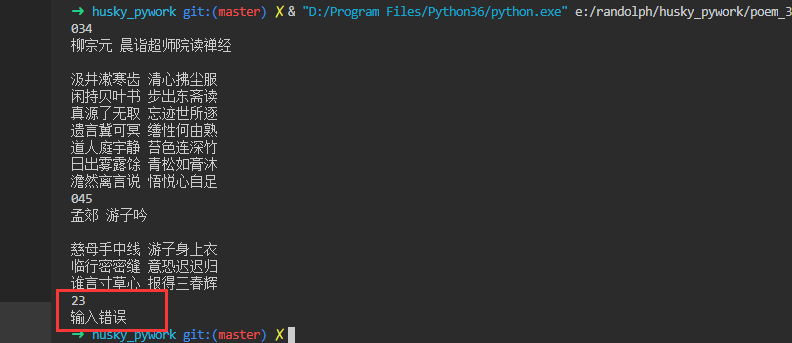
5.总结
re正则表达式,通过本次编程练习,熟悉了以前生疏的re正则匹配(匹配单行和多行、贪婪和不贪婪的区别)词性词性表
标签
含义
标签
含义
标签
含义
标签
含义
n
普通名词
f
方位名词
s
处所名词
t
时间
nr
人名
ns
地名
nt
机构名
nw
作品名
nz
其他专名
v
普通动词
vd
动副词
vn
名动词
a
形容词
ad
副形词
an
名形词
d
副词
m
数量词
q
量词
r
代词
p
介词
c
连词
u
助词
xc
其他虚词
w
标点符号
PER
人名
LOC
地名
ORG
机构名
TIME
时间
关闭jieba debug日志输出 jieba.setLogLevel(logging.INFO)jieba.initialize(),在导包后即初始化jieba,不需要每次在函数中初始化了Counter方法统计频次sorted方法中key用lambda函数可以根据某元素排序(在AD域中使用过的排序有根据多条件的更为复杂)列表推导式去除列表对象content中每一个元素的换行符、空字符[x.strip() for x in content if x.strip() != ‘’] ,以此代替for循环提高运行速度
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









