MySQL中默认有超级管理员用户root,但是在实际开发过程中,不能将管理员账号同时提供给讴歌项目去操作。 基本语法 (7)删除用户 (1)授予权限 (2)回收权限 注意:数据库.*表示该数据库中的所有数据表 ①创建测试数据表 先查看原表格中是没有数据的。 存储过程是数据库中的另一种高级对象:也称为存储程序,就是用户按照规范语法编写一组为完成特定功能的SQL语句集,然后经编译后存储在数据库中,用户通过调用固定的语法来执行该语句集代码。有点类似python中的函数。(调用方法时call) ①切换到该表进行操作 ①增强了sql语言的功能和灵活性 索引是数据库中的一个数据对象,是用来提升查询效率的。 索引的优点:创建索引可以大大提高系统的性能。 创建索引: 从存储结构上来划分:BTree索引(B-Tree和B+Tree索引),Hash索引,full-index全文索引,R-Tree索引,但是MySQL的InnoDB数据库引擎,只支持B+Tree索引。 Hash索引基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行的数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。 B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。 是B-Tree的改进版本,同时也是MySQL数据库索引默认的存储结构。数据都在叶子节点上,并且通过链表增加了顺序访问指针,每个叶子结点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。 问:为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
数据库进阶篇下
一、MySQL用户管理、权限操作
有时候会有这样的特殊情况:一个数据库管理系统中同时创建了多个数据库,同时服务多个项目。多个项目的开发人员都需要访问该数据库管理系统。如果这时候只用一个管理员账号的话,容易造成数据库中的数据安全问题。因此这个时候就需要给每个项目创建一个独立的子账号,让各个子账号具备一定的权限,单独管理对应的数据库即可。(一)账号管理
mysql8中的创建用户语法:
create user 账号@主机 identified by 密码;
兼容mysql创建用户的语法:
create user 账号@主机 identified with mysql_native_password by 密码;
(1)创建新用户

(2)登录新账号:
(3)创建数据库

由于新用户没有权限,所以无法创建数据库。
(4)修改用户密码
首先进入mysql数据库:use mysql
然后修改密码:
set password for root@localhost=“新密码”;
alter user lin@”%” identified by “新密码”;
但是现在本用户是没有办法修改密码的,因为没有权限

使用root用户操作
先进入mysql数据库:use mysql;
修改密码命令:alter user root@localhost identified by “新密码”;

修改后原密码登不了,需要使用新密码登录

(5)密码丢失/忘记密码
假如忘记了登录密码的情况下,mysql8以下的版本可以通过绕过密码登录重新设置密码,该方法在mysql8版本没有办法使用。
①第一步:先停止mysql服务,命令行执行net stop mysql

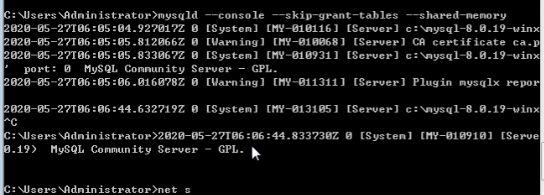
②第二步:然后在该命令行中使用mysqld –console –skip-grant-tables –shared-memory
此时该命令行窗口会停留在下图这种状态。

③此时重新打开一个cmd窗口,这时候就可以不用登录密码登录数据库了

④登录了数据库之后,就需要先将用户密码设置为空。use mysql; # 将root用户的密码设置为空 update user set authentication_string='' where user='root' and host='localhost'; # 刷新权限 flush privileges; 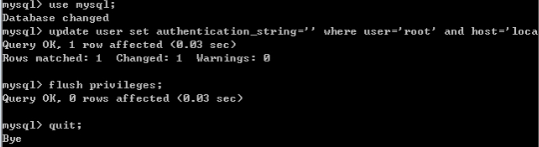
⑤做完上述操作之后就回到第一个cmd窗口,使用ctrl+c结束当前状态,重启mysql服务。(net start mysql)

⑥然后重新登录数据库,不用输入密码。并重新设置用户密码。
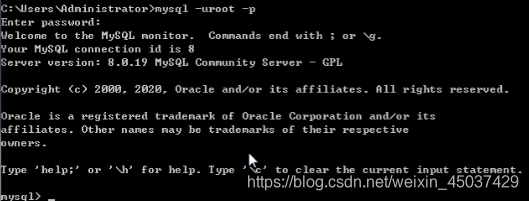
完成上述操作时候就完成重新设置密码的功能啦!
(6)远程登录用户# 第一步:查看用户名,地址和密码 use mysql; select user,host,authentication_string from user; # 第二步:将用户的主机设置成"%" update user set host="%" where user="root"; # 远程连接:在其他主机的命令行窗口输入命令即可连接 mysql -h 数据库所在主机地址 -u root -p drop user "用户名"@"%"; (二)权限管理
# 固定语法 grant all privileges on 数据库.数据表 to 用户@主机 with grant option; # 刷新权限 flush privileges; revoke 权限列表 on 数据库.数据表 from "用户名"@"主机"; 二、触发器
(一)什么是触发器?
(二)触发器语法
# 基本语法 create trigger trigger_name trigger_time trigger_event on tb_name for each row trigger_body; #trigger_name:触发器名称 # trigger_time:触发时间 before,after 在触发事件之前/之后 执行触发器中的代码 # trigger_event:触发事件 insert,update,delete # trigger_body:触发器的主体代码 -- 查看触发器 show triggers; -- a删除触发器 drop trigger trigger_name;
关键字
insert
delete
update
new.column_name
引用插入行中的某列数据
无
引用更新行中的某列新数据(更新后的值)
old.column_name
无
引用删除行中的,某列数据
引用更新行中的某列原来数据(更新前的值)
(三)案例操作(模拟自动下单操作)
create table goods( gid int auto_increment primary key comment '商品主键', gname varchar(20) not null comment '商品名称', gprice double not null comment '商品价格', gstock int not null comment'商品库存' ); create table goods_order( goid int auto_increment primary key comment '订单编号', goname varchar(20) not null comment '购买商品名称', goprice double not null comment '订单价格', gocount int not null comment'购买数量', subtotal double comment'小计金额' ); 
②创建触发器delimiter $$ -- 创建一个触发器 create trigger goods_sale_auto -- 在goods表发生变化后执行触发器 after update on goods for each row -- 要执行的程序开始操作 begin -- 声明两个变量 declare buycount int; declare subtotal double; -- 判断库存是否更新:更新前old,更新后new if new.gstock < old.gstock then -- 获取购买的数量 set buycount = old.gstock - new.gstock; -- 计算小票金额 set subtotal = buycount * old.gprice; -- 订单表中新增加数据 insert into goods_order(goname,goprice,gocount,subtotal) values(old.gname,old.gprice,buycount,subtotal); end if; -- 要执行的程序完结操作 end; $$ -- 触发器完成后,修改结束符号为默认的分号 delimiter; 
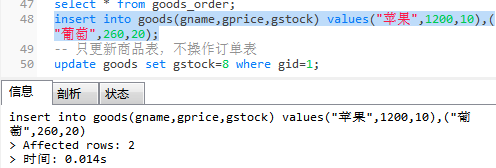
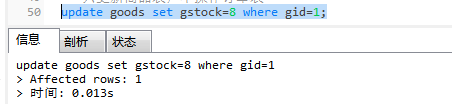
③执行测试语句-- 测试数据 select * from goods; select * from goods_order; insert into goods(gname,gprice,gstock) values("苹果",1200,10),("葡萄",260,20); -- 只更新商品表,不操作订单表 update goods set gstock=8 where gid=1;


向goods表中添加数据

更新goods表中苹果的库存。


发现goods_order表中也添加了数据。这就是触发器的功能了。三、存储过程
(一)什么是存储过程?
(二)基础语法
-- 将结束符转换成标识符d和delimiter功能一致 d 标识符 create procedure proc_name([参数]) begin ...存储过程中的各种操作 end 标识符 -- 将结束符设置回默认的分号符 d; -- 调用存储过程 call proc_name([参数]) (三)基本案例
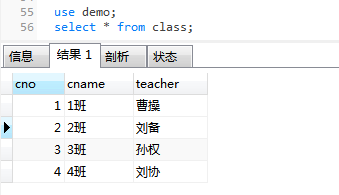
②设置向class表添加数据的存储过程-- 设置一个向class存储数据的存储过程 d $$ create procedure insert_class(in_cno int,in_cname varchar(20),in_teacher varchar(30)) begin insert into class values(in_cno,in_cname,in_teacher); end; $$ d ; -- 调用存储过程 call insert_class(5,"5班","阿斗"); 
(四)存储过程的优点
②存储过程在第一次编译后再调用就不需要再遍历,比sql语句执行效率高
③可以避免开发人员编写相同的sql语句
④减少客户端和服务端的数据传输四、数据库索引
(一)什么是索引?
(二)索引的种类
(三)索引的优缺点
索引的缺点:增加索引也有许多不利的方面(四)索引的使用
(五)索引案例(百万数据查询实验)
-- 使用存储过程 delimiter $$ -- 存储过程名为proc1,参数为cnt数据类型是int,为准备插入数据行的数量,调用时需要输入参数值 create procedure proc1(cnt int) begin -- 定义变量i为整形,默认值为1 declare i int default 1; -- 开启事务 start transaction; -- MySQL中repeat表示重复执行 repeat -- 插入数据库test中的t表,id列值对应为i,name列对应值为字符'a'与i值合并后的字符串 insert into test.t(id,name) values(i,concat("a",i)) -- 变量i自增1 set i = i+1; -- 当i值大于输入cnt值时,退出循环题 until i > cnt end repeat; commit; end; $$ delimiter ; 
-- 调用存储过程,设置插入一百万行数据 call proc1(1000000); 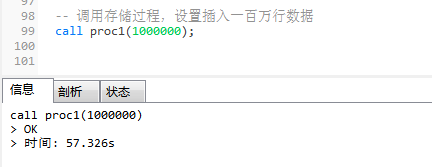
测试:
此时t表占用的数据内存大小是

给t表创建索引-- 给t表创建唯一索引 create unique index idx_id on t(id); 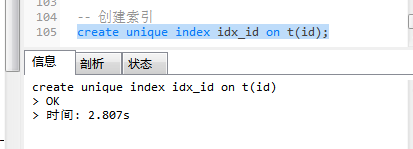
创建索引后t表的占用数据空间变大了。

删除索引
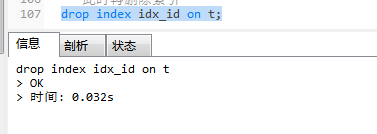
可是内存没有变化。因此,索引添加不能随意添加,当索引需要调整时,原来的索引就会变成了垃圾数据且无法删除。

(六)索引的底层原理
1、Hsah索引
Hash索引能最快速的进行数据的定位,对于固定数据的查询效率是最高的,但是如果是范围查询的情况,由于Hash索引的不连续性,查询性能会下降。

2、B-Tree索引

3、Tree索引

(七)关于索引的问题
答:
hash:虽然可以快速定位,但是没有殊勋,IO复杂度高。
二叉树:树的高度布局云,不能自平衡,查询效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
问:为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









