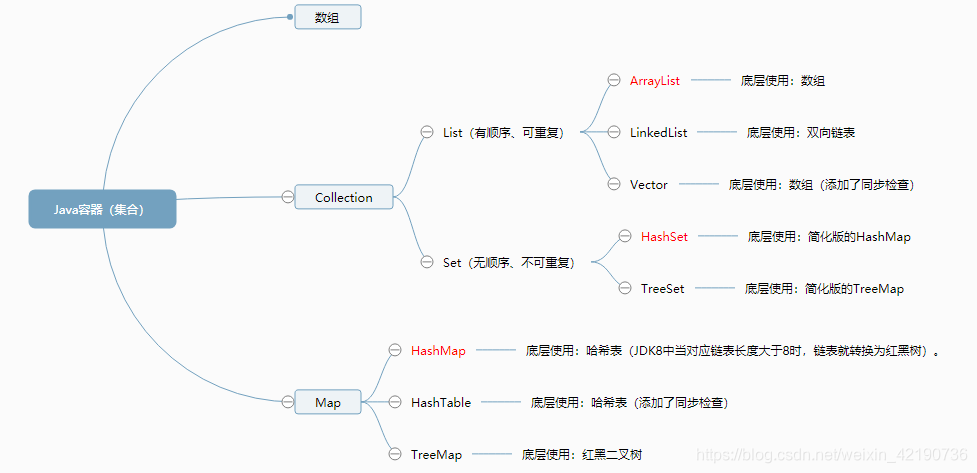
1、常见容器 2、泛型(数据类型的参数化) 3、Collection接口中的方法(List、Set中都可使用,因为继承了上述接口) 4、容器的遍历方法汇总 5、List(有顺序、可重复) 6、Set(无顺序、不可重复) 7、Map 8、Collections工具类
概念:“泛型”可以看做数据类型的一个占位符(形式参数),即告诉编译器,在调用泛型时必须传入实际类型。
注:对于未知的某个数据类型:泛型中一般采用<T,E,V>这3个字母表示。List<String> list = new ArrayList<String>(); //自定义泛型 MyList<String> mylist = new MyList<String>(); mylist.set("123", 0); class MyList<T>{//T表示泛型 Object[] objs = new Object[5]; public T get(int index) { return (T) objs[index]; } public void set(T e, int index) { objs[index] = e; } } Collection<String> collection = new ArrayList<String>(); Collection<String> collection2 = new ArrayList<String>(); collection.add("123");//添加元素 collection.addAll(collection2);//添加另一个容器内容 collection.remove("123");//移除(相同元素也只移除一个,并且移除的是存的地址,对象本身还存在在) collection.removeAll(collection2);//移除两容器的交集 collection.contains("123");//是否包含“123” collection.containsAll(collection2); collection.size();//元素数量 collection.toArray();//转数组 collection.isEmpty();//是否为空 collection.clear();//清空 collection.retainAll(collection2);//两个容器取交集 //迭代器iterator方法 Iterator<String> integer = collection.iterator();//获取迭代器对象,相当于new integer.hasNext();//判读是否有下一个元素 integer.next();//把当前内容返回,同时游标移到下一个 integer.remove(); //使用:List和Set相似 Collection<String> collection = new ArrayList<String>(); collection.add("one");collection.add("two"); for (Iterator<String> iter = collection.iterator(); iter.hasNext(); ) {//注意第三个参数不写 String string = iter.next(); System.out.println(string); } //使用:Map //方法一(常用): Map<Integer, String> map = new HashMap<Integer, String>(); map.put(1, "one");map.put(2, "two"); Set<Integer> mapkey = map.keySet();//获取map中key集合,并通过其获取迭代器对象 for (Iterator<Integer> iter = mapkey.iterator(); iter.hasNext(); ) { int key = iter.next(); System.out.println(key+"-"+map.get(key)); } //方法二(不常用): Set<Entry<Integer, String>> ss = map.entrySet(); for (Iterator iter = ss.iterator(); iter.hasNext();) { Entry e = (Entry) iter.next(); System.out.println(e.getKey()+"-"+e.getValue()); }
List:for、foreach、iterator
Set:foreach、iterator
Map:迭代器(两种)1、根据key获取value。2、使用entrySet
ArrayList:底层是用数组实现的存储。 特点:查询效率高,增删效率低,线程不安全。一般使用这个。
LinkedList:底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
Vector:底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。List<String> listCollection = new ArrayList<String>(); listCollection.add("123"); listCollection.add("456"); listCollection.add(0,"添加");//在指定索引位置插入元素,其他元素后推 listCollection.remove(0);//删除索引位置元素 listCollection.set(0, "替换");//替换指定索引位置元素 listCollection.get(0);//返回指定索引位置元素 listCollection.indexOf("456");//查找第一个找到位置的索引,找不到返回-1 System.out.println(listCollection.lastIndexOf("456"));//查找最后一个位置的索引
Set接口中没有新增方法,方法和Collection保持完全一致。
HashSet:采用哈希算法实现、底层实际是用HashMap实现的(HashSet本质是简化版的HashMap),查询、增删效率高。
TreeSet:底层实际是用TreeMap实现的(本质是简化版的TreeMap),通过key来存储Set的元素。
HashMap: 线程不安全,效率高。底层使用哈希表(允许key或value为null)。哈希表:本质:数组+单向链表(当对应链表长度大于8时,链表就转换为红黑树)。
HashTable: 线程安全(增加了同步检查),效率低。不允许key或value为null。
TreeMap:底层使用红黑二叉树,查找效率高,一般在频繁查找时使用。(会通过key排序)
注:map一般使于:用id作key值,将javabean对象作为value关联起来。Map<Integer, String> map = new HashMap<Integer, String>(); Map<Integer, String> map2 = new HashMap<Integer, String>(); map.put(1, "one");//存放键值对(key值相同只存在后一个) map.put(2, "two"); map.putAll(map2);//将map2的键值对全部存入 map.get(1);//通过key获取value值 map.remove(2);//通过key删除value System.out.println(map.containsKey(1));//通过key判断是否存在这个键值对 System.out.println(map.containsValue("one"));//通过value判断是否存在含有value这个键值对 import java.util.Collections;//引入包 List<String> list = new ArrayList<String>(); list.add("one");list.add("two"); Collections.sort(list);//对list容器内的元素排序,按照升序排序。 Collections.shuffle(list);//对list容器内的元素随机排列。 Collections.reverse(list);//对list容器内的元素逆序排列。 Collections.fill(list, "one");//用特定的对象重写list容器,将原来的全部覆盖。 Collections.binarySearch(list, "one");//对顺序的list容器,折半查找,返回索引位置
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









