集成学习是机器学习中的一种思想,他通过多个模型的组合形成一个精度更高的模型,参与组合的模型称为弱学习器。在预测时使用这些弱学习器模型联合进行预测;训练时需要用训练样本集依次训练出这些弱学习器。通俗来讲就是:三个臭皮匠,顶个诸葛亮。常见的集成学习框架有:Bagging,Boosting。 在介绍具体的算法原理之前先谈一下数据抽样方法,抽样值指的是从一个样本数据集中随机选取一些样本,形成新的数据集,这里有两种选择:有放回抽样和无放回抽样。其区别在于某次抽样中被抽中过的样本在其他抽样回合时会不会再次抽中,会再次抽中的就是有放回,反之就是无放回。集成学习中数据集的生成就是对给定的样本数据集进行有放回抽样,生成更多的数据集。 Bagging的全称为:Bootstrap Aggregating;这里的Bootstrap就是一种随机抽样的方法,采用的是对训练样本集有放回抽样,每次抽样形成的数据集训练一个弱学习器模型,以此得到多个独立的弱学习器,最终用这些弱学习器的组合进行预测。 上述的Bagging算法只是一个抽象的框架,没有指明具体的每个弱学习器模型的具体形式,当弱学习器是决策树,即为随机森林。对于分类问题,一个测试样本会送到每一颗决策树中进行预测,然后投票,得票最多的类为最终分类结果。对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同) Boosting不是对样本数据集进行独立的随机抽样构造训练集,而是每一轮的训练集不发生改变,训练时重点关注被前一轮训练中错分的样本。Boosting 训练过程为阶梯状,基模型的训练是有顺序的,每个基模型都会在前一个基模型学习的基础上进行学习,最终综合所有基模型的预测值产生最终的预测结果,用的比较多的综合方式为加权法。 AdaBoost(Adaptive Boosting,自适应增强),其自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。 错误率: 样本权重: 正确样本权重: 错误样本权重: 算法是通过一轮轮的弱学习器学习,利用前一个弱学习器的结果来更新后一个弱学习器的训练集权重。第 k 轮的强学习器为: 优点: Func1: loadSimpData() Func2: stumpClassify(dataMatrix, dimen, threshVal, threshIneq) 单决策树分类 Func3:buildStump(dataArr, classLabels, D) 构建最佳单层决策树 Func4:adaBoostTrainDS(dataArr, classLabels, numIt=40) 训练多个弱分类器,得到各分类器的权重 Func5: adaClassify(datToClass, classifierArr)测试分类器
ML入门5.0 手写集成学习(Ensemble learning)
集成学习简介
Bagging特点:数据随权重抽样,并行构建分类器,投票。
Boosting特点:关注被错分的样本,串行构建分类器,加权投票。
集成学习在计算机视觉领域,计算机安全领域和电子医疗诊断领域已经有了较为广泛和成熟的应用。原理简介
随机抽样
Bagging

随机森林


Boosting

AdaBoosting
Adaboost 迭代算法有三步:
1.初始化训练样本的权值分布,每个样本具有相同权重;
2.训练弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权值就会被降低;反之提高。用更新过的样本集去训练下一个分类器;
3.将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重。细节
优缺点
分类精度高;
可以用各种回归分类模型来构建弱学习器,非常灵活;
不容易发生过拟合。
缺点:
对异常点敏感,异常点会获得较高权重。实现代码
def loadSimpData(): ''' load data :return: dataMat(特征向量),classlabels(标签) ''' datMat = matrix([[1., 2.1], [2., 1.1], [1.3, 1.], [1., 1.], [2., 1.]]) classLabels = [1.0, 1.0, -1.0, -1.0, 1.0] return datMat, classLabels def stumpClassify(dataMatrix, dimen, threshVal, threshIneq): # just classify the data ''' 单决策树分类 :param dataMatrix:特征矩阵 :param dimen: 特征对应维度 :param threshVal:分类阈值 :param threshIneq: 分类标准(大于或者小于) :return:预测类别结果 ''' retArray = ones((shape(dataMatrix)[0], 1)) if threshIneq == 'lt': retArray[dataMatrix[:, dimen] <= threshVal] = -1.0 else: retArray[dataMatrix[:, dimen] > threshVal] = -1.0 return retArray def buildStump(dataArr, classLabels, D): ''' 构建最佳单层决策树 :param dataArr:dataSet :param classLabels:类别标签 :param D:权重 :return:最佳决策树,最小误差,分类结果 ''' dataMatrix = mat(dataArr) labelMat = mat(classLabels).T m, n = shape(dataMatrix) numSteps = 10.0 bestStump = {} bestClasEst = mat(zeros((m, 1))) minError = inf # init error sum, to +infinity for i in range(n): # loop over all dimensions rangeMin = dataMatrix[:, i].min() rangeMax = dataMatrix[:, i].max() stepSize = (rangeMax - rangeMin) / numSteps # 设置迭代步长 for j in range(-1, int(numSteps) + 1): # loop over all range in current dimension for inequal in ['lt', 'gt']: # go over less than and greater than threshVal = (rangeMin + float(j) * stepSize) predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal) # call stump classify with i, j, lessThan errArr = mat(ones((m, 1))) errArr[predictedVals == labelMat] = 0 weightedError = D.T * errArr # 计算加权错误率 calc total error multiplied by D # print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError) if weightedError < minError: minError = weightedError bestClasEst = predictedVals.copy() bestStump['dim'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = inequal return bestStump, minError, bestClasEst def adaBoostTrainDS(dataArr, classLabels, numIt=40): ''' 训练多个弱分类器,得到各分类器的权重 :param dataArr:dataSet :param classLabels:分类标签 :param numIt:迭代次数 :return:弱分类器和对应权重 ''' weakClassArr = [] m = shape(dataArr)[0] D = mat(ones((m, 1)) / m) # init D to all equal aggClassEst = mat(zeros((m, 1))) for i in range(numIt): bestStump, error, classEst = buildStump(dataArr, classLabels, D) # build Stump print("D:",D.T) alpha = float( 0.5 * log((1.0 - error) / max(error, 1e-16))) # calc alpha, throw in max(error,eps) to account for error=0 bestStump['alpha'] = alpha weakClassArr.append(bestStump) # store Stump Params in Array print("classEst: ",classEst.T) # 对应原理中的公式 expon = multiply(-1 * alpha * mat(classLabels).T, classEst) # exponent for D calc, getting messy D = multiply(D, exp(expon)) # Calc New D for next iteration D = D / D.sum() # calc training error of all classifiers, if this is 0 quit for loop early (use break) aggClassEst += alpha * classEst print("aggClassEst: ",aggClassEst.T) aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m, 1))) errorRate = aggErrors.sum() / m print("total error: ", errorRate) if errorRate == 0.0: break # 这里注意当多种分类器的加权结果已经可以始总误差降为0时即可推出 return weakClassArr, aggClassEst def adaClassify(datToClass, classifierArr): ''' 测试训练好的分类器 :param datToClass:testdata :param classifierArr: 分类器 :return: 分类结果 ''' dataMatrix = mat(datToClass) # do stuff similar to last aggClassEst in adaBoostTrainDS m = shape(dataMatrix)[0] aggClassEst = mat(zeros((m, 1))) for i in range(len(classifierArr)): classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq']) # call stump classify aggClassEst += classifierArr[i]['alpha'] * classEst #print(aggClassEst) return sign(aggClassEst) 运行结果
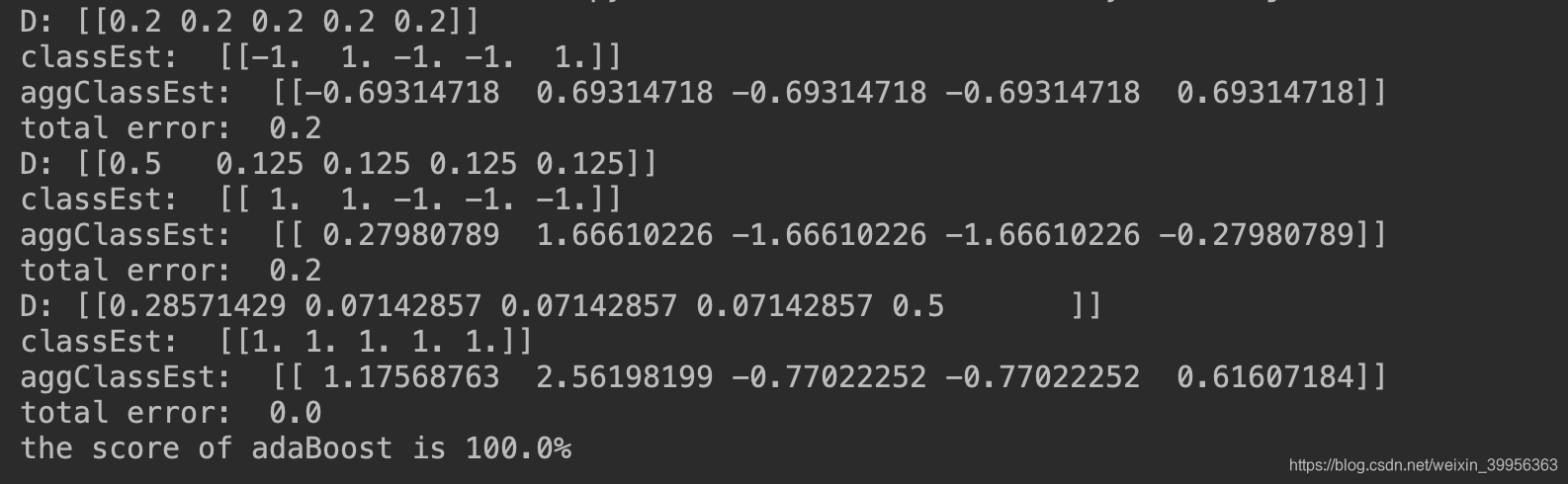
github地址
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









