前言
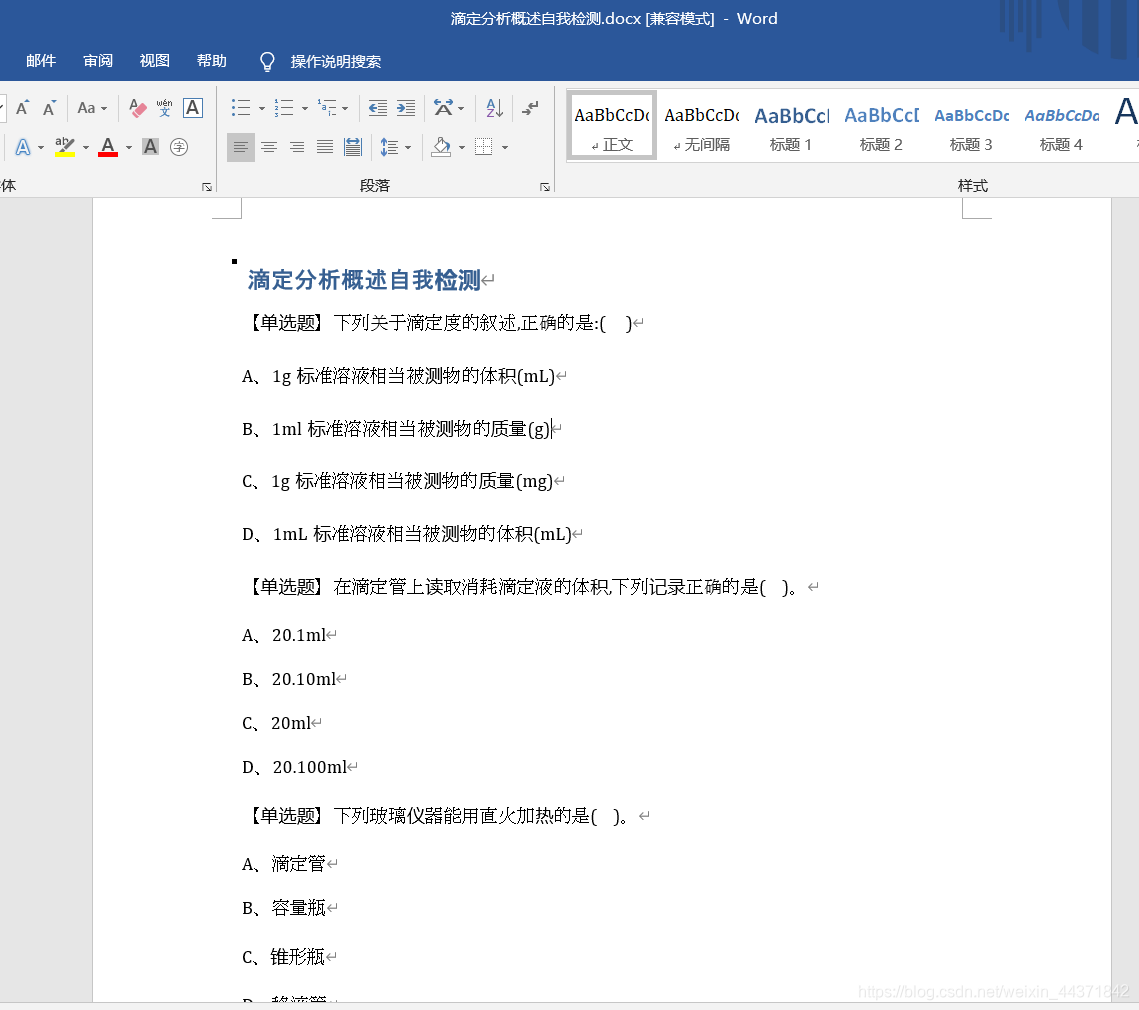
爬取流程
敲代码前的试探
import requests courseId = 208420018 mHeaders = { 'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3' } url = "https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId=208255733&knowledgeId=263215264" mHtml = requests.get(url,headers = mHeaders).content.decode('utf-8') if '人类进入21世纪' in mHtml: print('甩了') else: print('不妥')
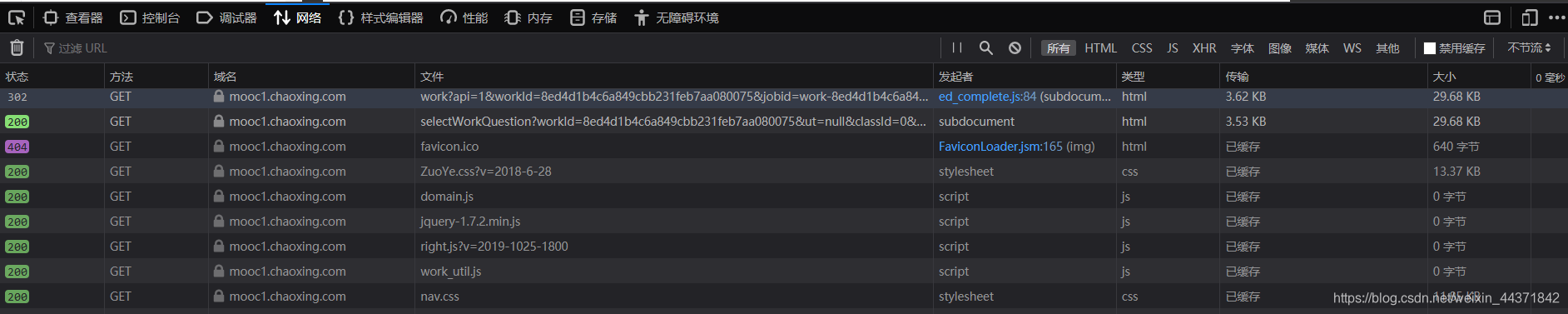
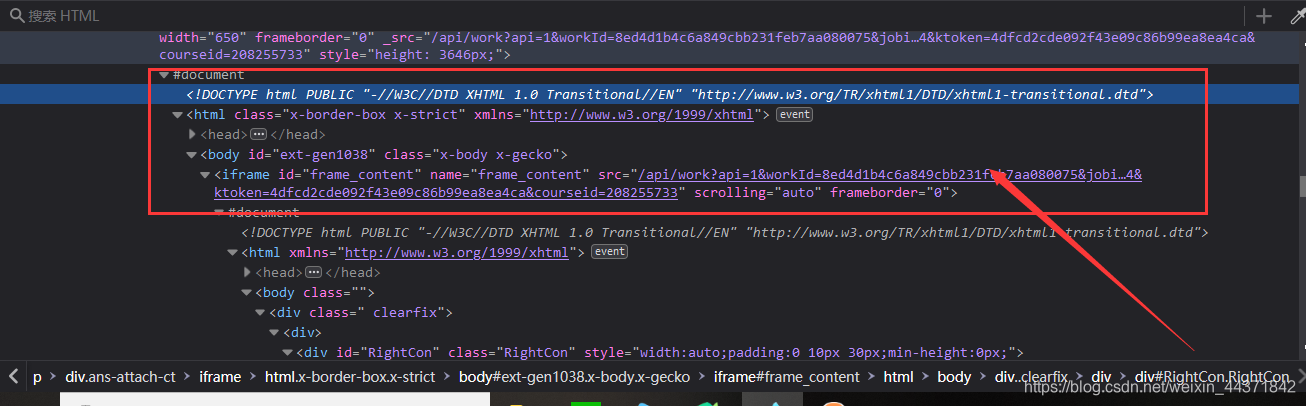
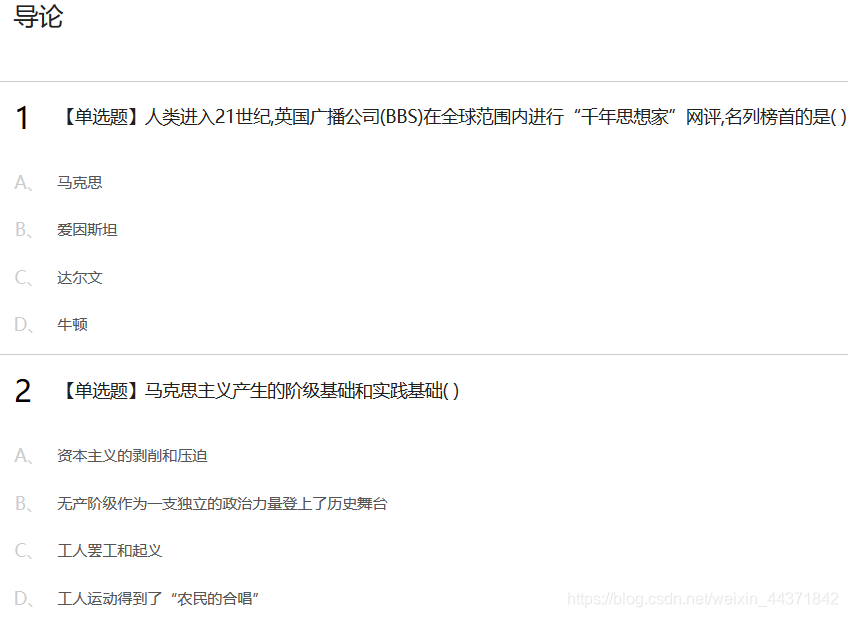
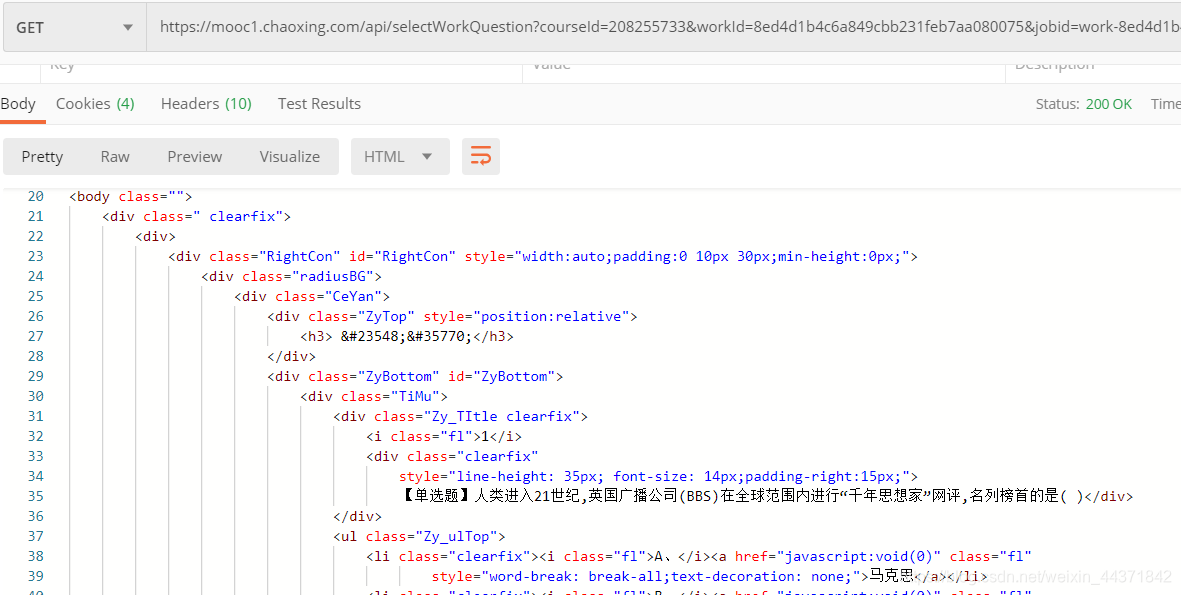
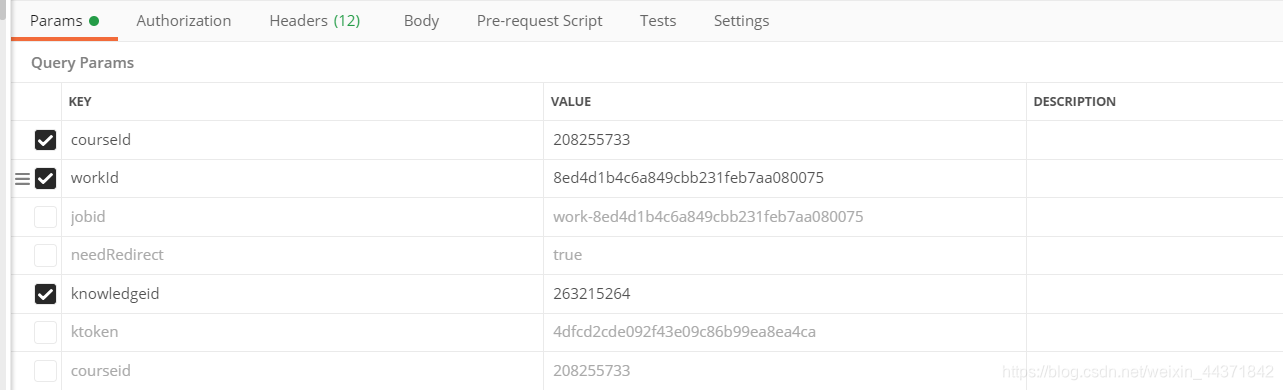
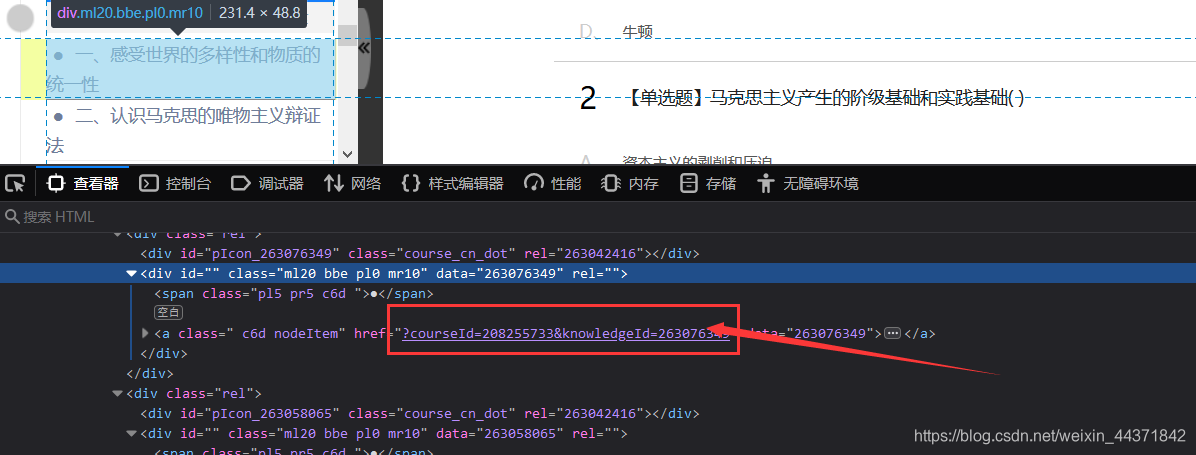


通过试探,总结一下编程思路。
思路有了,上代码!
def getHtml(): #得到页面 mUrl = url.replace('{{courseId}}',courseId) response = requests.get(mUrl,headers=mHeaders) response.encoding = 'utf-8' mHtml = html.unescape(response.text) #Html反转义 #response.encoding = 'utf-8' print(mHtml) return mHtml
def getCourseUrlList(zhtml): #得到可以用的每一个课时的Url divList = [] re_rule = 'courseId=' + courseId + '&knowledgeId=(.*?)">' # for i in re.findall(re_rule,html): # divList.append(i) divList = re.findall(re_rule,zhtml) urlList = [] for i in divList: mUrl = 'https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId='+courseId+'&knowledgeId='+i print(mUrl) try: response = requests.get(mUrl,headers=mHeaders,timeout=1) if response.status_code == 200: if courseId in response.text: urlList.append(mUrl) print('访问成功') else: print('非课程网页') except Exception as e: print('访问失败') return urlList
def getZuoYeUrl(urlList): #得到测验的Url tUrlList = [] for i in urlList: response = requests.get(i,headers=mHeaders).content.decode('utf-8') res = re.findall('workid":"(.*?)",', response) if len(res): for i in res: tUrl = "https://mooc1.chaoxing.com/api/selectWorkQuestion?workId="+i+"&ut=null&classId=0&courseId="+courseId tUrlList.append(tUrl) return tUrlList
def writeDocx(urlList): #从测验Url中读取题目并写入Word文档 for url in urlList: mHtml = requests.get(url, headers=mHeaders).content.decode("utf-8") file = docx.Document() h3 = re.findall('<h3>(.*?)</h3>', mHtml) Title = "" for i in h3: Title = html.unescape(i) file.add_heading(Title) text = html.unescape(mHtml) mHtml = etree.HTML(text) # 将html转换为xml timuList = mHtml.xpath('//div[@class="TiMu"]') # 找到每一个题目及其所有选项 for i in timuList: time.sleep(0.05) mStr = etree.tostring(i).decode('utf-8') # 将xml树结点读出并转换为utf-8格式 res = html.unescape(mStr) # 解码xml tType = re.findall('(【.*?】)', res) tRType = [] for a in tType: p_rule = '<.*?>' tRType.append(re.sub(p_rule,'',str(a))) #删除所有的html标签 tGan = re.findall('】<?p?>?(.*?)</p>', res) if not len(tGan): tGan = re.findall('<div class="Zy_TItle_p">(.*?)</div>', res) if not len(tGan): tGan = re.findall('】(.*?)</div>',res) tRGan = [] for a in tGan: p_rule = '<.*?>' tRGan.append(re.sub(p_rule,'',str(a))) file.add_paragraph(tRType + tRGan) ''' for j in tType: print(j) file.add_paragraph(j) for j in tGan: print(j) file.add_paragraph(j) ''' XuanXiang = etree.HTML(res) tAny = XuanXiang.xpath('//li[@class="clearfix"]') for j in tAny: tStr = etree.tostring(j).decode('utf-8') tRes = html.unescape(tStr) tXuan = re.findall('<i class="fl">(.*?)</i>.*?none;"><?p?>?(.*?)<?/?p?>?</a></li>', tRes) tRXuan = [] for a in tXuan: tRRXuan = "" for b in a: p_rule = '<.*?>' tRRXuan = tRRXuan + re.sub(p_rule, '', str(b)) tRXuan.append(tRRXuan) for k in tRXuan: file.add_paragraph(k) file.save("D:\"+Title+".docx") print(Title+'爬取完成') time.sleep(0.3)
# coding=utf-8 from lxml import etree import docx import requests import re import html import time url = "https://mooc1.chaoxing.com/course/{{courseId}}.html" mHeaders = { 'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3' }
if __name__ == "__main__": courseId = "208255733" #通过改变courseId可以实现爬取不同的课程,也可以课程号自加循环爬取,但课程量太大,就不一一编写。 zHtml = getHtml() canUseUrl = getCourseUrlList(zHtml) zuoYeUrl = getZuoYeUrl(canUseUrl) writeDocx(zuoYeUrl) 后记
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 3073
3073