所用数据集链接:所用数据集链接(ex5data1.mat),提取码:c3yy 题目:本次将首先用正则化的线性回归去拟合水库水流量与水位变化的关系。之后会发现,线性拟合并不是对于该问题的良好拟合方法,从而转向多项式回归。在多项式回归中,通过绘制学习曲线判断当前模型状态,并且选择正则化参数。 首先导入相应包: 读取数据: 对于数据进行相应预处理: 输出如下: 下面可视化数据: 输出如下: 下面开始定义代价函数: 下面定义梯度: 下面开始训练模型: 下面可视化结果: 结果如下: 显然线性回归的拟合效果不佳,所以我们需要转向多项式回归。 绘制学习曲线事实上是为了看出当前模型的状态(高偏差或高方差),事实上,上图我们已经很清楚看出该模型处于高偏差状态,所以其实不必要绘图。不过作为练习,还是给出代码: 学习曲线以训练集样本数为横坐标,以误差(非正则化的训练误差或交叉验证集误差)为纵坐标,公式如下: 输出如下: 欠拟合状态增加样本数是徒劳的,一个很有用的方法就是增加特征: 如此大量的特征最好进行归一化: 下面看看特征映射后拟合如何: 结果如下: 下面为防止过拟合给出选择lambda的代码: 结果如下: 评估模型: 输出: 给出完整代码:
Python 3.7
目录
Bias and Variance
Regularized Linear Regression
1.0 Package
import numpy as np # 矩阵处理 import matplotlib.pyplot as plt # 绘图 from scipy.io import loadmat # 读取矩阵文件 import scipy.optimize as opt # 优化函数 1.1 Load data
def load_data(path): data=loadmat(path) x_train=data['X'] y_train=data['y'] x_cv=data['Xval'] y_cv=data['yval'] x_test=data['Xtest'] y_test=data['ytest'] # 矩阵文件中样本分为三组,分别是训练集,交叉验证集和测试集 return data,x_train,y_train,x_cv,y_cv,x_test,y_test data,x_train,y_train,x_cv,y_cv,x_test,y_test=load_data('ex5data1.mat') 1.2 Preprocess data
def preprocess_data(): global x_train # 声明是全局变量 x_train=np.insert(x_train,0,1,axis=1) # 在第一列前插入一列1 global x_cv x_cv=np.insert(x_cv,0,1,axis=1) global x_test x_test=np.insert(x_test,0,1,axis=1) return x_train,x_cv,x_test x_train,x_cv,x_test=preprocess_data() print('x_train:',x_train.shape) print('x_cv:',x_cv.shape) print('x_test:',x_test.shape) print('y_train:',y_train.shape) print('y_cv:',y_cv.shape) print('y_test:',y_test.shape)

1.3 Visualization data
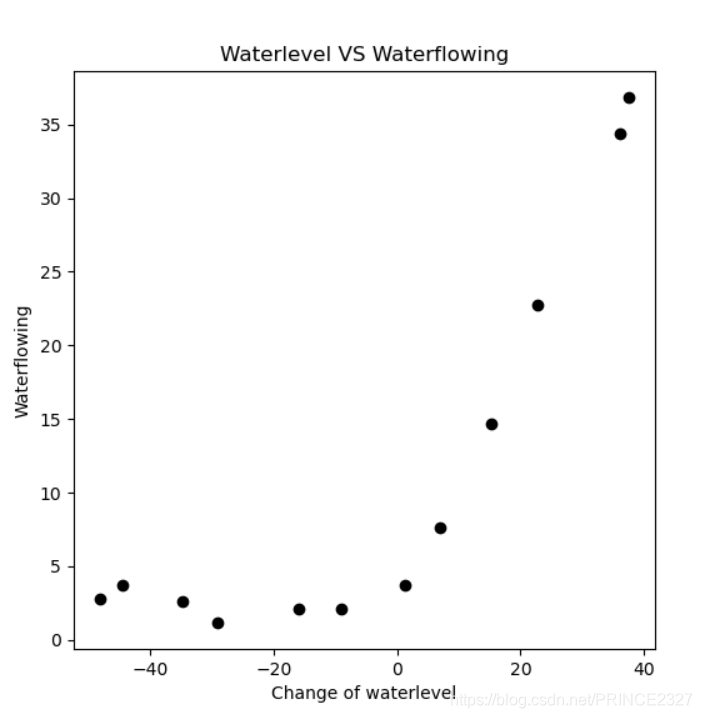
def view_data(): fig,ax=plt.subplots(figsize=(6,6)) # 创建画布与对象 ax.scatter(x_train[:,1:],y_train,c='black') # 指明对象为散点 ax.set_xlabel('Change of waterlevel') ax.set_ylabel('Waterflowing') ax.set_title('Waterlevel VS Waterflowing') # 设置横纵坐标名称及主题 plt.show() view_data()
1.4 Regularized costfunction
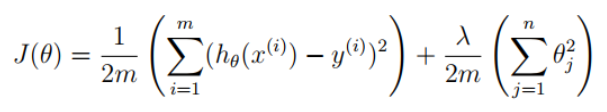
代码如下:def regularized_costfunction(theta,x,y,l): h=x@theta # print(h,h.shape) J=np.power((h-y.flatten()),2) # print(J,J.shape) reg=l*(theta[1:]@theta[1:]) # print(reg,reg.shape) cost=(np.sum(J)+reg)/(2*len(x)) return cost theta=np.zeors(x_train.shape[1]) cost=regularized_costfunction(theta,x_train,y_train,1) print('inital_cost:',cost) #140.95412..... 1.5 Regularized gradient
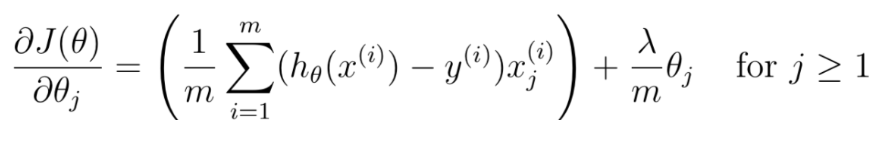
其中:
,注意与逻辑回归的不同之处。def regularized_gradient(theta,x,y,l): gradient=((x@theta-y.flatten())@x)/len(x) # 注意把y展开成一维数组,这是也为x与theta相乘后返回的就是一维数组 reg=l*theta/len(x) reg[0]=0 gradient=gradient+reg return gradient gradient=regularized_gradient(theta,x_train,y_train,0) print(gradient) #[ -11.21758933 -245.65199649] 1.6 Train model
def training(x,y,l): inital_theta=np.ones(x.shape[1]) result=opt.minimize(fun=regularized_costfunction,x0=inital_theta,args=(x,y,l),method='TNC',jac=regularized_gradient) return result.x # 返回的是result中的x,也就是最优优自变量(theta) fin_theta=training(x_train,y_train,0) 1.7 Visualization result
def view_result(x,y,theta): fig,ax=plt.subplots(figsize=(6,6)) ax.scatter(x[:,1:],y,c='r',marker='x') ax.plot(x[:,1],x@theta) ax.set_xlabel('Change of waterlevel') ax.set_ylabel('Waterflowing') ax.set_title('Waterlevel VS Waterflowing') plt.show() view_result(x_train,y_train,fin_theta)
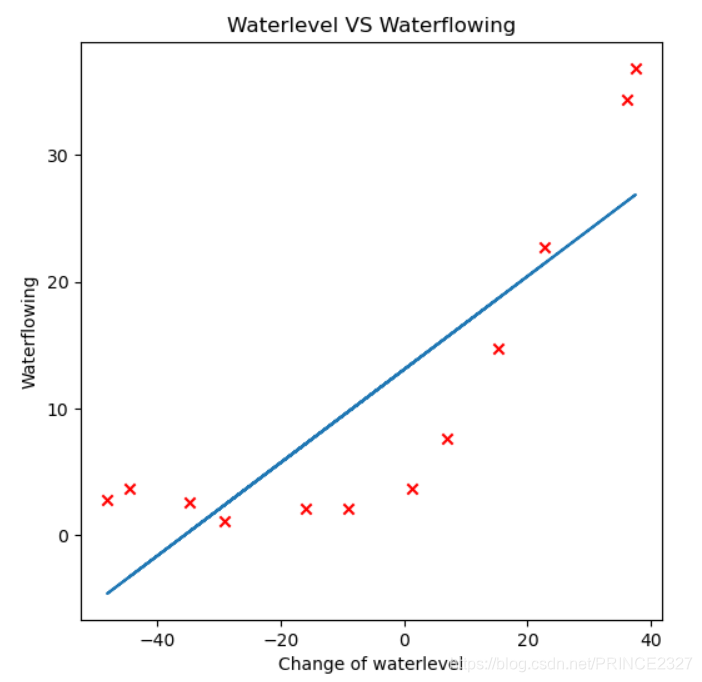
1.8 Evalute model
Learning curve and model select
2.0 Learning curve
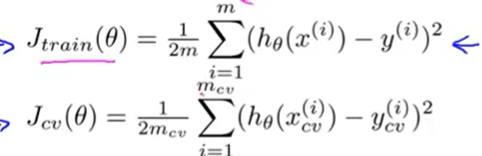
def learning_curve(x_train,y_train,x_cv,y_cv,l): num=range(1,len(x_train)+1) # 使得训练集样本数从1到最大 train_cost=[] cv_cost=[] # 后续存储训练集误差和交叉验证集误差 for i in num: fin_theta=training(x_train[:i],y_train[:i],l) # 针对每次所用的样本数,训练出不同的权重 cost_train=regularized_costfunction(fin_theta,x_train[:i],y_train[:i],0) train_cost.append(cost_train) cost_cv=regularized_costfunction(fin_theta,x_cv,y_cv,0) cv_cost.append(cost_cv) # 计算训练集误差和交叉验证集误差,注意交叉验证集误差使用的是全集而非子集 fig,ax=plt.subplots(figsize=(8,8),sharex=True,sharey=True) ax.plot(num,train_cost,label='Training cost') ax.plot(num,cv_cost,label='Cv cost') ax.set_xlabel=('m(Training examples)') ax.set_ylabel=('Error') ax.set_title('Learning Curve') plt.legend() plt.grid(True) # 最好还是把网格打开,不然可能看瞎 plt.show() # 可视化 learning_curve(x_train,y_train,x_cv,y_cv,3)

很明显这种情况随着样本数的增多,训练集误差与交叉验证集误差都趋于较高的位置,所以目前模型处理欠拟合状态。2.1 Polynoimal regression
def polyregression(x,degree): x_poly=x.copy() # 用copy可以保留原数据,直接该有可能会出现难以察觉的错误 for i in range(2,degree+1): x_poly=np.insert(x_poly,x_poly.shape[1],np.power(x_poly[:,1],i),axis=1) # 映射到degree次方 return x_poly 2.2 Feature normalization
def feature_normalize(x,mean,std): x_norm=x.copy() x_norm[:,1:]=(x_norm[:,1:]-mean[1:])/(std[1:]) return x_norm # 归一化函数 degree=6 mean=np.mean(polyregression(x_train,degree),axis=0) std=np.std(polyregression(x_train,degree),axis=0,ddof=1) # 注意期望和方差是特征映射后训练集的期望和方差 x_train_norm=feature_normalize(polyregression(x_train,degree),mean,std) x_cv_norm=feature_normalize(polyregression(x_cv,degree),mean,std) x_test_norm=feature_normalize(polyregression(x_test,degree),mean,std) # 归一化训练集,交叉验证集和测试集 2.3 Visualization result
def plot_curve(mean,std,l): fin_theta=training(x_train_norm,y_train,l) # 使用归一化后的训练集进行训练,得到参数 fig,ax=plt.subplots(figsize=(6,6)) ax.scatter(x_train[:,1],y_train,c='black',marker='x') x=np.linspace(-80,60,100) x_norm=x.reshape(-1,1) x_norm=np.insert(x_norm,0,1,axis=1) x_norm=feature_normalize(polyregression(x_norm,degree),mean,std) ax.plot(x,x_norm@fin_theta,c='red') plt.show() plot_curve(mean,std,1) learning_curve(x_train_norm,y_train,x_cv_norm,y_cv,1)
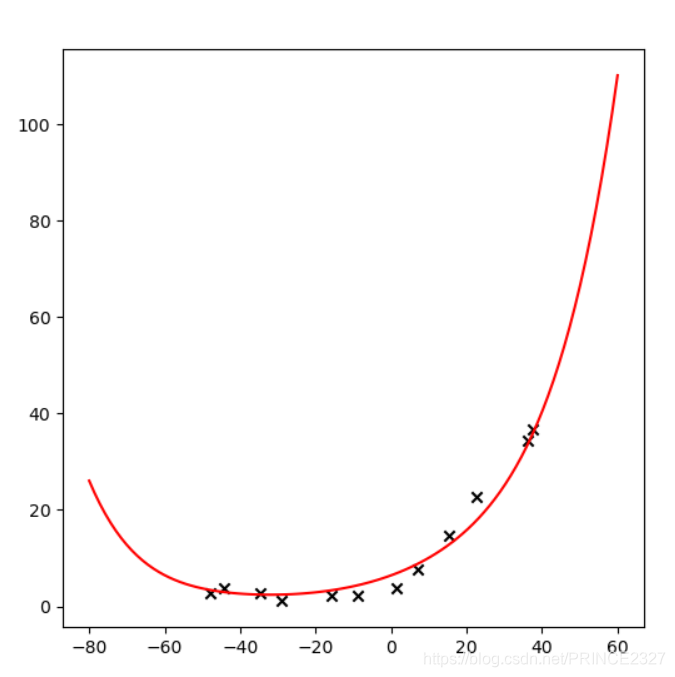
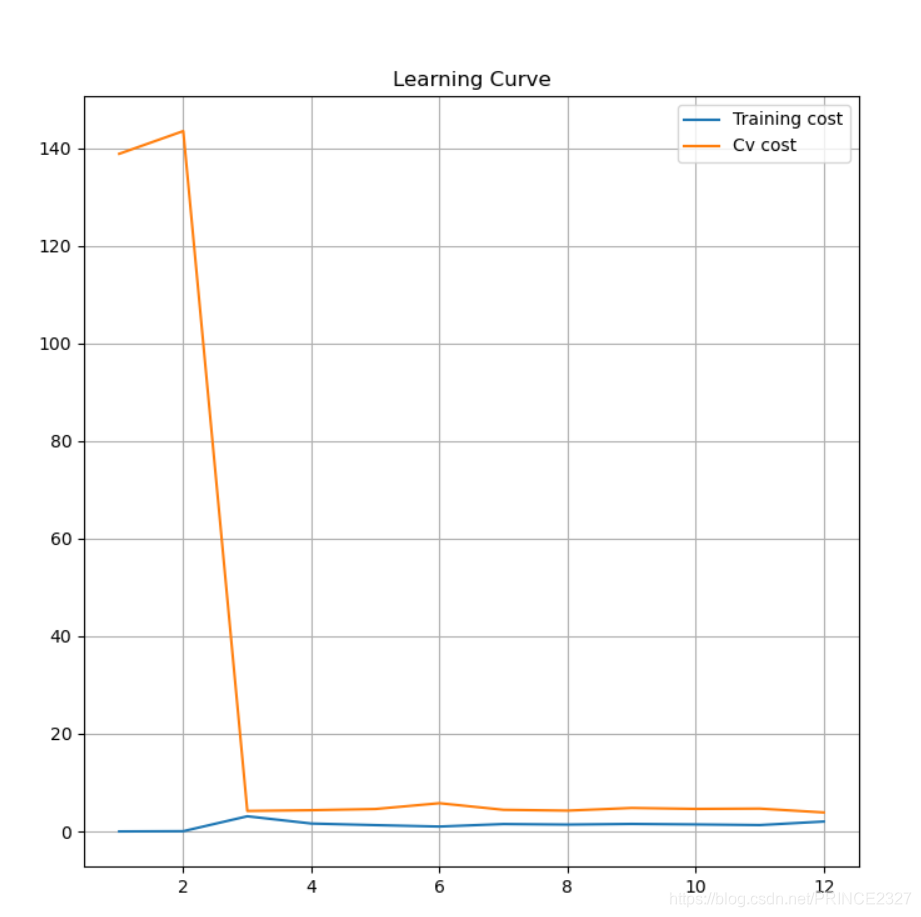
可以看出,lambda设为1时候,训练误差太小,明显过拟合。2.4 Select lambda
def select_lambdas(): train_error=[] cv_error=[] # 存储训练集误差和交叉验证集误差 la=[0,0.001,0.002,0.004,0.008,0.01,0.03,0.1,0.3,0.9,1,3,5,10,20] # 选取一系列lambda作为待选值,可以以每次三倍进行选择 for i in la: fin_theta=training(x_train_norm,y_train,i) # 针对每个lambda进行训练 error_train=regularized_costfunction(fin_theta,x_train_norm,y_train,0) error_cv=regularized_costfunction(fin_theta,x_cv_norm,y_cv,0) # 计算训练集误差和交叉验证集误差 train_error.append(error_train) cv_error.append(error_cv) fig,ax=plt.subplots(figsize=(6,6)) ax.plot(la,train_error,label='Train set') ax.plot(la,cv_error,label='Cross Validation set') plt.legend() ax.set_xlabel('Lambda') ax.set_ylabel('Error') plt.grid(True) plt.show() select_lambdas()
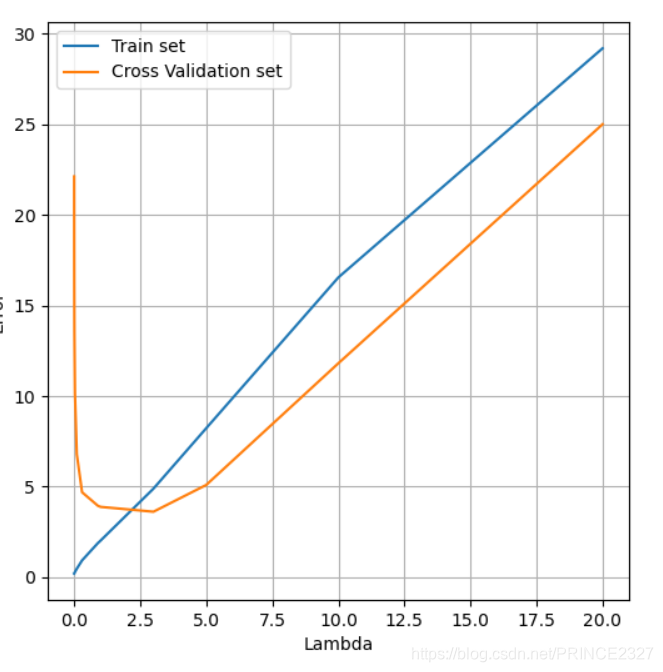
2.5 Evalute model
def evalute_model(): fin_theta=training(x_train_norm,y_train,3) cost=regularized_costfunction(fin_theta,x_test_norm,y_test,0) # 注意评估的误差要采用测试集误差,才可推广到一般情况 print('The finally theta is:{}nThe finally cost is:{}'.format(fin_theta,cost)) evalute_model()

All
import numpy as np import matplotlib.pyplot as plt from scipy.io import loadmat import scipy.optimize as opt def load_data(path): data=loadmat(path) x_train=data['X'] y_train=data['y'] x_cv=data['Xval'] y_cv=data['yval'] x_test=data['Xtest'] y_test=data['ytest'] return data,x_train,y_train,x_cv,y_cv,x_test,y_test data,x_train,y_train,x_cv,y_cv,x_test,y_test=load_data('ex5data1.mat') def preprocess_data(): global x_train x_train=np.insert(x_train,0,1,axis=1) global x_cv x_cv=np.insert(x_cv,0,1,axis=1) global x_test x_test=np.insert(x_test,0,1,axis=1) return x_train,x_cv,x_test x_train,x_cv,x_test=preprocess_data() print('x_train:',x_train.shape) print('x_cv:',x_cv.shape) print('x_test:',x_test.shape) print('y_train:',y_train.shape) print('y_cv:',y_cv.shape) print('y_test:',y_test.shape) def view_data(): fig,ax=plt.subplots(figsize=(6,6)) ax.scatter(x_train[:,1:],y_train,c='black') ax.set_xlabel('Change of waterlevel') ax.set_ylabel('Waterflowing') ax.set_title('Waterlevel VS Waterflowing') plt.show() #view_data() def regularized_costfunction(theta,x,y,l): h=x@theta # print(h,h.shape) J=np.power((h-y.flatten()),2) # print(J,J.shape) reg=l*(theta[1:]@theta[1:]) # print(reg,reg.shape) cost=(np.sum(J)+reg)/(2*len(x)) return cost theta=np.zeros(x_train.shape[1]) cost=regularized_costfunction(theta,x_train,y_train,1) print('inital_cost:',cost) def regularized_gradient(theta,x,y,l): gradient=((x@theta-y.flatten())@x)/len(x) reg=l*theta/len(x) reg[0]=0 gradient=gradient+reg return gradient gradient=regularized_gradient(theta,x_train,y_train,1) print(gradient) def training(x,y,l): inital_theta=np.ones(x.shape[1]) result=opt.minimize(fun=regularized_costfunction,x0=inital_theta,args=(x,y,l),method='TNC',jac=regularized_gradient) return result.x fin_theta=training(x_train,y_train,0) def view_result(x,y,theta): fig,ax=plt.subplots(figsize=(6,6)) ax.scatter(x[:,1:],y,c='r',marker='x') ax.plot(x[:,1],x@theta) ax.set_xlabel('Change of waterlevel') ax.set_ylabel('Waterflowing') ax.set_title('Waterlevel VS Waterflowing') plt.show() #view_result(x_train,y_train,fin_theta) def learning_curve(x_train,y_train,x_cv,y_cv,l): num=range(1,len(x_train)+1) train_cost=[] cv_cost=[] for i in num: fin_theta=training(x_train[:i],y_train[:i],l) cost_train=regularized_costfunction(fin_theta,x_train[:i],y_train[:i],0) train_cost.append(cost_train) cost_cv=regularized_costfunction(fin_theta,x_cv,y_cv,0) cv_cost.append(cost_cv) fig,ax=plt.subplots(figsize=(8,8),sharex=True,sharey=True) ax.plot(num,train_cost,label='Training cost') ax.plot(num,cv_cost,label='Cv cost') ax.set_xlabel=('m(Training examples)') ax.set_ylabel=('Error') ax.set_title('Learning Curve') plt.legend() plt.grid(True) plt.show() #learning_curve(x_train,y_train,x_cv,y_cv,3) def polyregression(x,degree): x_poly=x.copy() for i in range(2,degree+1): x_poly=np.insert(x_poly,x_poly.shape[1],np.power(x_poly[:,1],i),axis=1) return x_poly def feature_normalize(x,mean,std): x_norm=x.copy() x_norm[:,1:]=(x_norm[:,1:]-mean[1:])/(std[1:]) return x_norm degree=6 mean=np.mean(polyregression(x_train,degree),axis=0) std=np.std(polyregression(x_train,degree),axis=0,ddof=1) x_train_norm=feature_normalize(polyregression(x_train,degree),mean,std) x_cv_norm=feature_normalize(polyregression(x_cv,degree),mean,std) x_test_norm=feature_normalize(polyregression(x_test,degree),mean,std) print(x_train) def plot_curve(mean,std,l): fin_theta=training(x_train_norm,y_train,l) fig,ax=plt.subplots(figsize=(6,6)) ax.scatter(x_train[:,1],y_train,c='black',marker='x') x=np.linspace(-80,60,100) x_norm=x.reshape(-1,1) x_norm=np.insert(x_norm,0,1,axis=1) x_norm=feature_normalize(polyregression(x_norm,degree),mean,std) ax.plot(x,x_norm@fin_theta,c='red') plt.show() #plot_curve(mean,std,1) #learning_curve(x_train_norm,y_train,x_cv_norm,y_cv,1) def select_lambdas(): train_error=[] cv_error=[] la=[0,0.001,0.002,0.004,0.008,0.01,0.03,0.1,0.3,0.9,1,3,5,10,20] for i in la: fin_theta=training(x_train_norm,y_train,i) error_train=regularized_costfunction(fin_theta,x_train_norm,y_train,0) error_cv=regularized_costfunction(fin_theta,x_cv_norm,y_cv,0) train_error.append(error_train) cv_error.append(error_cv) fig,ax=plt.subplots(figsize=(6,6)) ax.plot(la,train_error,label='Train set') ax.plot(la,cv_error,label='Cross Validation set') plt.legend() ax.set_xlabel('Lambda') ax.set_ylabel('Error') plt.grid(True) plt.show() #select_lambdas() def evalute_model(): fin_theta=training(x_train_norm,y_train,3) cost=regularized_costfunction(fin_theta,x_test_norm,y_test,0) print('The finally theta is:{}nThe finally cost is:{}'.format(fin_theta,cost)) evalute_model()
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










