穿汉服的女孩是真的好看,一不小心进入某网址,彻底改变了我的人生价值观,还爬什么其他妹子,就一个字,爬她,爬它,就爬她! 梅开二度,作为爬图小能手的我又来啦,这次带给大家的是精美的汉服,我真的是太喜欢这种传统服饰了,为了一波,所以就爬了某站,你们觉得也喜欢的话,也可以一波! 下面是我之前写的其他站点的爬图程序,感兴趣的可以点击看看: 汉服爬取 这次的网站比较简单,所以爬虫代码也简单了不少。零基础的我觉得也能看懂,实在不行,我放入全部代码,嘿嘿,保证我有的妹子,你们也要有! 网址如下:https://www.aihanfu.com/zixun/tushang-1/ 这是第一页的网址,根据观察,第二页网址也就是 根据图示,我们只需要获得每个子网站的链接,也就是href中网址,然后进入每个网址,寻找图片网址,在下载就行了,思路就是这样。 图就是我上面的那张图,这里可以用soup或者re或者xpath都行的,我比较喜欢用xpath来定位,编写定位函数,获得每个子网站链接,然后返回主函数,这里使用了一个技巧,在for循环中,你们可以看看! 我们点开一个网址链接,如图所示: 可以发现标题在head的节点里面,那这个时候有人肯定会问,要标题干嘛, 图表下载网址在我所指的箭头方向,那些节点打开都是相同的规律。 因为从链接我发现这个网址的图片质量还过得去,如果你们追求高清图片,要4k图,那你们可以点击这篇博客 真4k抓取 里面有讲到怎么抓4k的方法,所有网站都是适用的。 个人感觉这个网站真的很简单,基本没怎么出bug,一次性的写完了。 我抓图绝大部分就是用来作壁纸的,或者满足我自己的需求,其他方向我也不知道能干什么,对于爬虫来说,抓图片或许是最简单的一个片面,但也是最幸福的方向! 抓完了,发现一件特别好看的汉服,打开淘宝一看999,告辞,等等,我没有女朋友啊,我买这个干嘛,但凡有一粒花生米,我也不会来抓汉服送女友了。 求关注,求,求三连,你的支持是我最大的动力哈!

第一步:分析网站
序标1变成了序标2,依次类推,就可以访问全部页数。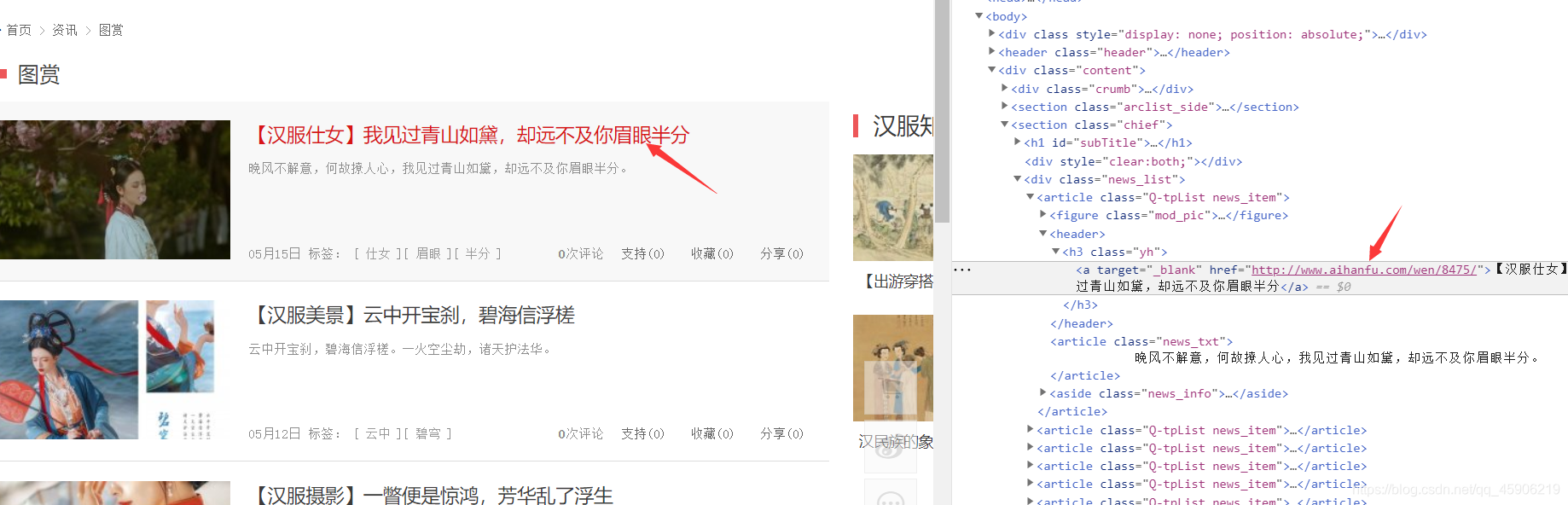
第二步:获得子网站链接:
def get_menu(url, heades): """ 根据每一页的网址 获得每个链接对应的子网址 params: url 网址 """ r = requests.get(url, headers=headers) if r.status_code == 200: r.encoding = r.apparent_encoding html = etree.HTML(r.text) html = etree.tostring(html) html = etree.fromstring(html) # 查找每个子网址对应的链接, 然后返回 children_url = html.xpath('//div[@class="news_list"]//article/figure/a/@href') for _ in children_url: yield _ 第三步:获得标题和图表网址:

这个创建文件夹的时候需要,不然用0,1,2,3表示多俗气。
这里我就不累赘表示了。
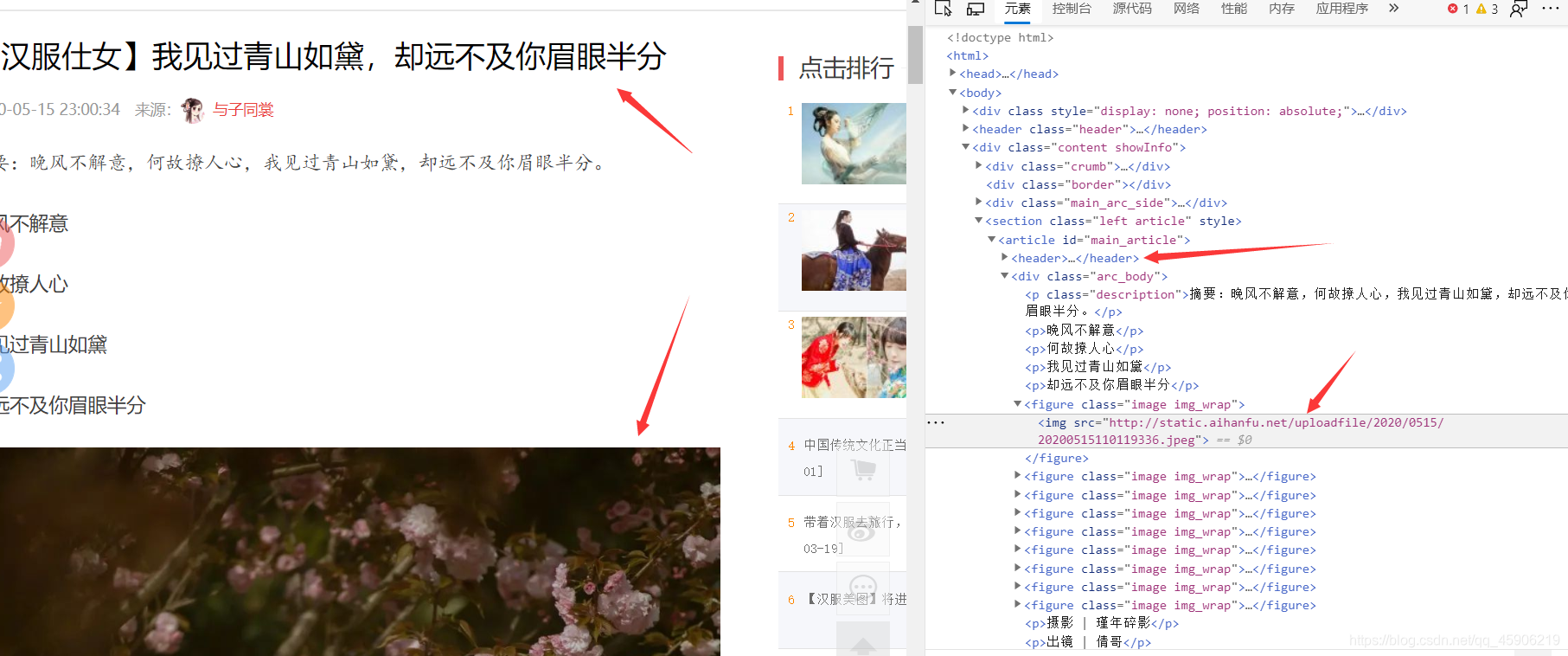
def get_page(url, headers): """ 根据子页链接,获得图片地址,然后打包下载 params: url 子网址 """ r = requests.get(url, headers=headers) if r.status_code == 200: r.encoding = r.apparent_encoding html = etree.HTML(r.text) html = etree.tostring(html) html = etree.fromstring(html) # 获得标题 title = html.xpath(r'//*[@id="main_article"]/header/h1/text()') # 获得图片地址 img = html.xpath(r'//div[@class="arc_body"]//figure/img/@src') # title 预处理 title = ''.join(title) title = re.sub(r'【|】', '', title) print(title) save_img(title, img, headers)
第四步:打包下载图片:
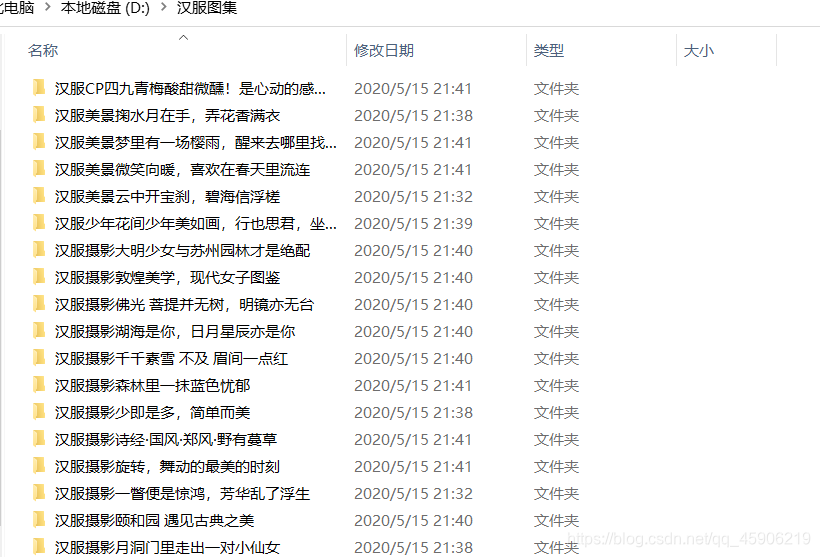
def save_img(title, img, headers): """ 根据标题创建子文件夹 下载所有的img链接,选择更改质量大小 params: title : 标题 params: img : 图片地址 """ if not os.path.exists(title): os.mkdir(title) # 下载 for i, j in enumerate(img): # 遍历该网址列表 r = requests.get(j, headers=headers) if r.status_code == 200: with open(title + '//' + str(i) + '.png', 'wb') as fw: fw.write(r.content) print(title, '中的第', str(i), '张下载完成!')
第五步:编写主函数:
import requests from lxml import etree import os import re if __name__ == '__main__': """ 一页一页查找 params : None """ path = 'D://汉服图集//' if not os.path.exists(path): os.mkdir(path) os.chdir(path) else: os.chdir(path) # url = 'https://www.aihanfu.com/zixun/tushang-1/' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)' ' AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/81.0.4044.129 Safari/537.36'} for _ in range(1, 50): url = 'https://www.aihanfu.com/zixun/tushang-{}/'.format(_) for _ in get_menu(url, headers): get_page(_, headers) # 获得一页
第六步: 欣赏图集:
第七步: 打开淘宝:

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










