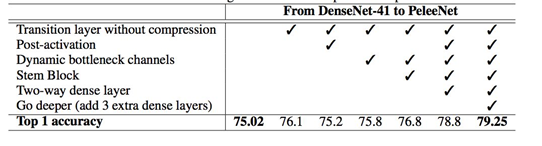
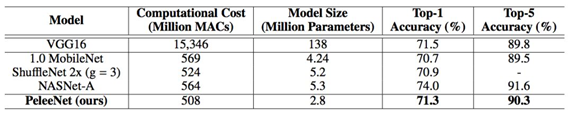
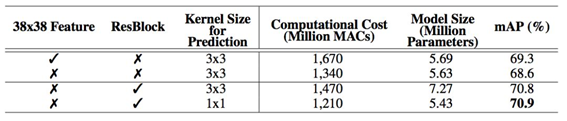
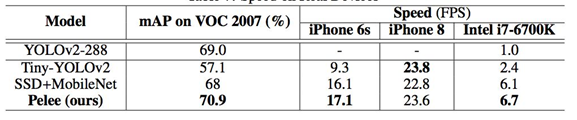
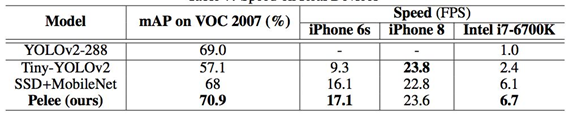
提到轻量级神经网络,大家都会提到MobileNet V1 V2 和 ShuffleNet V1 V2,似乎较少看到大家提到PeleeNet,下面介绍一下检测网络Pelee 在ImageNet数据集上,PeleeNet只有MobileNet模型的66%,并且比MobileNet精度更高。PeleeNet作为backbone实现SSD能够在VOC2007数据集上达到76.4%的mAP。文章总体上参考DenseNet的设计思路,提出了三个核心模块进行改进,有一定参考价值。 PeleeNet实际上是DenseNet的变体,使用的依然是DenseNet的连接方法,核心的设计原则也和DenseNet相仿(特征重用)。 PeleeNet作者还提出了以PeleeNet为基础的轻量级检测网络Pelee,与以VGG为基础网络的SSD相比,为了降低计算量,作者使用19×19大小特征图的层作为SSD的第一层预测层。 预测层大小分别为:19 x 19, 10 x 10, 5 x 5, 3 x 3, 1 x 1 MobileNet 同样未使用38 x 38的特征图作为预测层,但添加了2 x 2的预测层来保持6尺度SSD检测。 在我的应用场景中,Pelee的表现远超出了ShuffleNet V2-SSD的表现,也有可能是调参之前没烧香,继续调试中。 从coco的实验看,其表现效果较好,比ssd-mobilenet网络要好,本作者目前在使用TensorFlow object detect api中的ssd-mobilenetv2网络做移动端目标检测,发现其pb文件大小17.8m,单张图片目标检测前向传播时间约为0.32s好像。也在尝试pelee网络,目前在进行训练。**用于预测的小型卷积核:**残差预测块让我们应用 1×1 的卷积核来预测类别分数和边界框设置成为可能。实验表明:使用 1×1 卷积核的模型的准确率和使用 3×3 的卷积核所达到的准确率几乎相同。研究者在 iOS 上提供了 SSD 算法的实现。他们已经成功地将 SSD 移植到了 iOS 上,并且提供了优化的代码实现。该系统在 iPhone 6s 上以 17.1 FPS 的速度运行,在 iPhone8 上以 23.6 FPS的速度运行。在 iPhone 6s(2015 年发布的手机)上的速度要比在 Intel i7-6700K@4.00GHz CPU 上的官方算法实现还要快 2.6 倍。 表 1:不同的设计选择的效果得到的性能 表 2:在 Stanford Dogs 数据集上的结果。MACs:乘法累加的次数,用于度量融合乘法和加法运算次数 表 3:在 ImageNet ILSVRC 2012 数据集上的结果 表 4:不同设计选择上的性能结果 表 5:在 PASCAL VOC 2007 数据集上的结果。数据:07+12,VOC2007 和 VOC2012 联合训练;07+12+COCO,先在 COOC 数据集上训练 35000 次,然后在 07+12 上继续微调。 表6:实际设备上的速度 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-squrKfrk-1589591803962)(D:ImapBoxpic车辆检测毕设1269652-20180724103432901-1285676795.png)] 表 7: COCO test-dev2015 数据集上的结果 这个轻便的PeLee一上线就备受瞩目,是一种新型的轻型目标检测算法我们来详解一下 1:导入需要的库 细说一下: torch是pytorch的缩写,是一种深度学习框架 理解pytorch的基础主要从以下三个方面 Numpy风格的Tensor操作。pytorch中tensor提供的API参考了Numpy的设计,因此熟悉Numpy的用户基本上可以无缝理解,并创建和操作tensor,同时torch中的数组和Numpy数组对象可以无缝的对接。 2:导入需要的数据 分别导入了: config:PeLee模型参数及其配置 VOC数据集及其配置参数 阈值选取 和cfg参数(模型参数已下载好官网) 我们来看看coco数据集: OCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。 VOC数据集是目标检测经常用的一个数据集,从05年到12年都会举办比赛(比赛有task: Classification 、Detection(将图片中所有的目标用bounding box框出来) 、 Segmentation(将图片中所有的目标分割出来)、Person Layout) VOC2012:对于检测任务,VOC2012的trainval/test包含08-11年的所有对应图片。 trainval有11540张图片共27450个物体。 对于分割任务, VOC2012的trainval包含07-11年的所有对应图片, test只包含08-11。trainval有 2913张图片共6929个物体。 2:构建检测类 3:加载各类模型:比如核心检测需要的cfg参数: 4:初始化模型: 5:检测算法 6:绘制矩形框以及计算数量: 运行主程序: 下面再详细介绍一下PeLee: 已有的在移动设备上执行的深度学习模型例如 MobileNet、 ShuffleNet 等都严重依赖于在深度上可分离的卷积运算,而缺乏有效的实现。在本文中,来自加拿大西安大略大学的研究者提出了称为 PeleeNet 的有效架构,它没有使用传统的卷积来实现。PeleeNet 实现了比目前最先进的 MobileNet 更高的图像分类准确率,并降低了计算成本。研究者进一步开发了实时目标检测系统 Pelee,以更低的成本超越了 YOLOv2 的目标检测性能,并能流畅地在 iPhone6s、iPhone8 上运行。 两路稠密层:受 GoogLeNet (Szegedy et al. (2015)) 的两路稠密层的激发,研究者使用了一个两路密集层来得到不同尺度的感受野。其中一路使用一个 3×3 的较小卷积核,它能够较好地捕捉小尺度的目标。另一路使用两个 3×3 的卷积核来学习大尺度目标的视觉特征。该结构如图 1.a 所示: 右边(a)图代表PeleeNet中设计的基本模块,除了将原本的主干分支的filter减半(主干分支感受野为3×3),还添加了一个新的分支,在新的分支中使用了两个3×3的卷积,这个分支感受野为5×5。这样就提取得到的特征就不只是单一尺度,能够同时兼顾小目标和大目标。 (b)这个模块可以在几乎不增加计算量的情况下提升特征的表达能力。 仔细看看上图展示的结构,先使用strided 3×3卷积进行快速降维,然后用了两分支的结构,一个分支用strided 3×3卷积, 另一个分支使用了一个maxpool。 这一部分和组合池化非常相似,stem block使用了strided 3×3卷积和最大值池化两种的优势引申而来的池化策略(组合池化使用的是最大值池化和均值池化),可以丰富特征层。 瓶颈层通道的动态数量:另一个亮点就是瓶颈层通道数目会随着输入维度的变化而变化,以保证输出通道的数目不会超过输出通道。与原始的 DenseNet 结构相比,实验表明这种方法在节省 28.5% 的计算资源的同时仅仅会对准确率有很小的影响。 没有压缩的转换层:实验表明,DenseNet 提出的压缩因子会损坏特征表达,PeleeNet 在转换层中也维持了与输入通道相同的输出通道数目。 复合函数:为了提升实际的速度,采用后激活的传统智慧(Convolution – Batch Normalization (Ioffe & Szegedy (2015)) – Relu))作为我们的复合函数,而不是 DenseNet 中所用的预激活。对于后激活而言,所有的批正则化层可以在推理阶段与卷积层相结合,这可以很好地加快速度。为了补偿这种变化给准确率带来的不良影响,研究者使用一个浅层的、较宽的网络结构。在最后一个密集块之后还增加了一个 1×1 的卷积层,以得到更强的表征能力。 研究者优化了单样本多边框检测器(Single Shot MultiBox Detector,SSD)的网络结构,以加速并将其与 PeleeNet 相结合。该系统,也就是 Pelee,在 PASCAL VOC (Everingham et al. (2010)) 2007 数据集上达到了 76.4% 的准确率,在 COCO 数据集上达到了 22.4% 的准确率。在准确率、速度和模型大小方面,Pelee 系统都优于 YOLOv2 (Redmon & Farhadi (2016))。为了平衡速度和准确率所做的增强设置如下: 特征图选择:以不同于原始 SSD 的方式构建目标检测网络,原始 SSD 仔细地选择了 5 个尺度的特征图 (19 x 19、10 x 10、5 x 5、3 x 3、1 x 1)。为了减少计算成本,没有使用 38×38 的特征图。 残差预测块:遵循 Lee 等人提出的设计思想(2017),即:使特征沿着特征提取网络传递。对于每一个用于检测的特征图,在实施预测之前构建了一个残差 (He et al. (2016)) 块(ResBlock)。ResBlock 的结构如图 2 所示: 用于预测的小型卷积核:残差预测块让我们应用 1×1 的卷积核来预测类别分数和边界框设置成为可能。实验表明:使用 1×1 卷积核的模型的准确率和使用 3×3 的卷积核所达到的准确率几乎相同。然而,1×1 的核将计算成本减少了 21.5%。 研究者在 iOS 上提供了 SSD 算法的实现。他们已经成功地将 SSD 移植到了 iOS 上,并且提供了优化的代码实现。该系统在 iPhone 6s 上以 17.1 FPS 的速度运行,在 iPhone8 上以 23.6 FPS 的速度运行。在 iPhone 6s(2015 年发布的手机)上的速度要比在 Intel i7-6700K@4.00GHz CPU 上的官方算法实现还要快 2.6 倍。 Pelee 使用两路卷积层来得到不同尺寸的感受野。 图 46 左边先通过 1 x 1 卷积,后面接 3 x3 卷积,使其对小物体有更好表现。右边先通过 1 x 1 卷积,两个 3 x 3 卷积代替 5 x 5 卷积,有更小的计算量和参数个数,且对大物体有更好表现。 图 47 网络前几层对于特征的表达十分重要,Pelee 采用了类似于 DSOD 算法的 stem block 结构,经实验可知该结构可以在不增加过多计算量情况下提高特征表达能力。 bottleneck layer 通道数目随着输入维度的变化而变化,以保证输出通道的数目不会超过输出通道。与原始的 DenseNet 结构相比,实验表明这种方法在节省 28.5% 的计算资源的同时仅会对准确率有很小的影响。 实验表明,DenseNet 提出的压缩因子会损坏特征表达,Pelee 在转换层中也维持了与输入通道相同的输出通道数目。 舍弃了以前的 bn-relu-conv 采用了 conv-bn-relu 形式。Bn 层与卷积层融合加快推理速度(融合部分计算),同时后面接了 1 x 1 卷积提高表达能力。 作者将 SSD 与 Pelee 相结合,得到了优于 YOLOV2 的网络结构。使用 Pelee 作为基础网络对 SSD 改进: 1. 舍弃 SSD 的 38 x 38 的 feature map。 2. 采用了 Residual Prediction Block 结构,连接了不同的层。 3. 用 1 x 1 卷积代替 SSD 里的 3 x 3 卷积做最终物体的分类与回归。减少了 21.5%的计算量。 具体网络结构: 图 48:分类网络结构图 图 49 首先图片输入后经过 Stem Block 结构,再通过 stage1、 stage2、stage3、stage4 及后续卷积操作得到相应 feature map,接 resblock 结构后进行分类及位置回归。 图 50 如图: score是一个坐标框的各个类别的概率,取最大的那个(非背景类),大于某个阙值就是正样本 例如第七行(对应着我们的label中的汽车)得分: 0.93653619 0.88733804 0.51076788 0.4675599 0.35944954 0.35482538 大于我们的阈值,所有判断为正! 计算每一个物体对应的车辆这一类别的得分:所以判断出9辆车子: 结合 SSD,在 VOC2007 数据集上达到了 76.4%的 mAP,在 COCO 数据集上达到了 22.4%的 mAP。在 iPhone 6s 上的运行速度是 17.1 FPS,在 iPhone 8 上的运行速度是 23.6 FPS。 图 51 图 52 最后: 码字不易,看到这里的朋友感兴趣,可以一起玩玩,也邀请朋友们一起进群学习深度学习(个人深度学习技术交流群),群里大佬较多,感兴趣的就联系我~可别忘记了关注!!

Pelee:移动端实时检测骨干网络



import os import cv2 import numpy as np import time # from utils.nms_wrapper import nms from configs.CC import Config import argparse from layers.functions import Detect, PriorBox from peleenet import build_net from data import BaseTransform, VOC_CLASSES from utils.core import * import torch
变量自动求导。在一序列计算过程形成的计算图中,参与的变量可以方便的计算自己对目标函数的梯度。这样就可以方便的实现神经网络的后向传播过程。
神经网络层与损失函数优化等高层封装。网络层的封装存在于torch.nn模块,损失函数由torch.nn.functional模块提供,优化函数由torch.optim模块提供。parser = argparse.ArgumentParser(description='Pelee Testing') parser.add_argument('-c', '--config', default='./configs/Pelee_VOC.py') parser.add_argument('-d', '--dataset', default='VOC', help='VOC or COCO dataset') parser.add_argument('-m', '--trained_model', default='./Pelee_VOC.pth', type=str, help='Trained state_dict file path to open') parser.add_argument('-t', '--thresh', default=0.3, type=float, help='visidutation threshold') parser.add_argument('--show', default=True, help='Whether to display the images') args = parser.parse_args() cfg = Config.fromfile(args.config)
VOC2007:中包含9963张标注过的图片, 由train/val/test三部分组成, 共标注出24,640个物体。 VOC2007的test数据label已经公布, 之后的没有公布(只有图片,没有label)。class Pelee_Det(object): def __init__(self): self.anchor_config = anchors(cfg.model) self.priorbox = PriorBox(self.anchor_config) self.net = build_net('test', cfg.model.input_size, cfg.model) init_net(self.net, cfg, args.trained_model) self.net.eval() self.num_classes = cfg.model.num_classes with torch.no_grad(): self.priors = self.priorbox.forward() # self.net = self.net.cuda() # self.priors = self.priors.cuda() cudnn.benchmark = True self._preprocess = BaseTransform( cfg.model.input_size, cfg.model.rgb_means, (2, 0, 1)) self.detector = Detect(num_classes, cfg.loss.bkg_label, self.anchor_config) def anchors(config): cfg = dict() cfg['feature_maps'] = config.anchor_config.feature_maps cfg['min_dim'] = config.input_size cfg['steps'] = config.anchor_config.steps cfg['min_sizes'], cfg['max_sizes'] = get_min_max_sizes( config.anchor_config.min_ratio, config.anchor_config.max_ratio, config.input_size, len(cfg['feature_maps'])) cfg['aspect_ratios'] = config.anchor_config.aspect_ratios cfg['variance'] = [0.1, 0.2] cfg['clip'] = True return cfg def init_net(net, cfg, resume_net): if cfg.model.init_net and not resume_net: net.init_model(cfg.model.pretained_model) else: print('Loading resume network...') state_dict = torch.load(resume_net, map_location=torch.device('cpu')) from collections import OrderedDict new_state_dict = OrderedDict() for k, v in state_dict.items(): head = k[:7] if head == 'module.': name = k[7:] else: name = k new_state_dict[name] = v net.load_state_dict(new_state_dict, strict=False) def detect(self, image): loop_start = time.time() w, h = image.shape[1], image.shape[0] img = self._preprocess(image).unsqueeze(0) # if cfg.test_cfg.cuda: # img = img.cuda() scale = torch.Tensor([w, h, w, h]) out = self.net(img) boxes, scores = self.detector.forward(out, self.priors) boxes = (boxes[0] * scale).cpu().numpy() scores = scores[0].cpu().numpy() allboxes = [] count = 0 for j in range(1, num_classes): inds = np.where(scores[:, j] > cfg.test_cfg.score_threshold)[0] if len(inds) == 0: continue c_bboxes = boxes[inds] c_scores = scores[inds, j] c_dets = np.hstack((c_bboxes, c_scores[:, np.newaxis])).astype( np.float32, copy=False) soft_nms = cfg.test_cfg.soft_nms keep = nms(c_dets, cfg.test_cfg.iou, force_cpu=soft_nms) keep = keep[:cfg.test_cfg.keep_per_class] c_dets = c_dets[keep, :] allboxes.extend([_.tolist() + [j] for _ in c_dets]) loop_time = time.time() - loop_start allboxes = np.array(allboxes) boxes = allboxes[:, :4] scores = allboxes[:, 4] cls_inds = allboxes[:, 5] infos, im2show, num= draw_detection(image, boxes, scores, cls_inds, -1, 0.15) # todo threshold need to be modify return infos, im2show, num def draw_detection(im, bboxes, scores, cls_inds, fps, thr=0.2): global num imgcv = np.copy(im) h, w, _ = imgcv.shape infos = [] for i, box in enumerate(bboxes): if scores[i] < thr: continue cls_indx = int(cls_inds[i]) # print(cls_indx) if cls_indx == 7 or cls_indx == 6: num += 1 box = [int(_) for _ in box] thick = int((h + w) / 300) cv2.rectangle(imgcv, (box[0], box[1]), (box[2], box[3]), colors[cls_indx], thick) mess = '%s' % (labels[cls_indx]) infos.append(ch_labels[cls_indx]+' '+str(scores[i])) cv2.putText(imgcv, mess, (box[0], box[1] - 7), 0, 1e-3 * h, colors[cls_indx], thick // 3) if fps >= 0: cv2.putText(imgcv, '%.2f' % fps + ' fps', (w - 160, h - 15), 0, 2e-3 * h, (255, 255, 255), thick // 2) return infos, imgcv,num if __name__ == '__main__': det = Pelee_Det() im = cv2.imread('./test_imgs/demo.png') # todo threshold = 0.8 im = cv2.imread('./test_imgs/demo1.png') # todo threshold = 0 im = cv2.imread('./test_imgs/c.jpg') # todo threshold = 0.15 # im = cv2.imread('./test_imgs/a.png') # todo threshold = 0.4 # im = cv2.imread('./test_imgs/k.png') # todo threshold = 0.01 # im = cv2.imread('./test_imgs/h.jpg') # todo threshold = 0.07 # im = cv2.imread('./test_imgs/b.jpg') # todo threshold = 0.15 # im = cv2.imread('./test_imgs/f.jpg') # todo threshold = 0.15 _, im, num = det.detect(im) print('there are', str(num), 'cars') num = str(num) + 'cars' cv2.putText(im, num, (50, 150), cv2.FONT_HERSHEY_COMPLEX, 2, (0, 255, 0), 4) cv2.imshow(num, im) cv2.waitKey(0) cv2.destroyAllWindows() 
在具有严格的内存和计算预算的条件下运行高质量的 CNN 模型变得越来越吸引人。近年来人们已经提出了很多创新的网络,例如 MobileNets (Howard et al.(2017))、ShuffleNet (Zhang et al.(2017)),以及 ShuffleNet (Zhang et al.(2017))。然而,这些架构严重依赖于在深度上可分离的卷积运算 (Szegedy 等 (2015)),而这些卷积运算缺乏高效的实现。同时,将高效模型和快速目标检测结合起来的研究也很少 (Huang 等 (2016b))。本研究尝试探索可以用于图像分类和目标检测任务的高效 CNN 结构。本文的主要贡献如下:
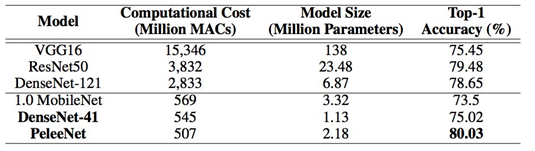
研究者提出了 DenseNet (Huang et al. (2016a)) 的一个变体,它被称作 PeleeNet,专门用于移动设备。PeleeNet 遵循 DenseNet 的创新连接模式和一些关键设计原则。它也被设计来满足严格的内存和计算预算。在 Stanford Dogs (Khosla et al. (2011)) 数据集上的实验结果表明:PeleeNet 的准确率要比 DenseNet 的原始结构高 5.05%,比 MobileNet (Howard et al. (2017)) 高 6.53%。PeleeNet 在 ImageNet ILSVRC 2012 (Deng et al. (2009)) 上也有极具竞争力的结果。PeleeNet 的 top-1 准确率要比 MobileNet 高 0.6%。需要指出的是,PeleeNet 的模型大小是 MobileNet 的 66%。PeleeNet 的一些关键特点如下:
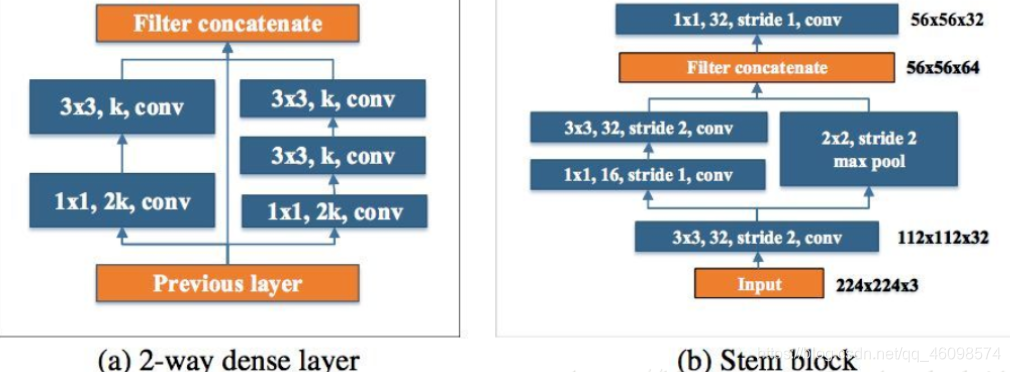
图 1: 两路密集层和 stem 块的结构

图 2:残差预测块
核心思想
Two-Way Dense Layer
Stem Block
动态调整 bottleneck layer 通道数
过渡层不压缩
Bn 层与卷积融合,起到加速的作用
计算出该图片中各个物体的得分(score):


算法效果
PeLee作为新型的目标检测轻量级网络。 他没有使用SSD中3838的feature map做预测。对1919的feature map使用两种不同大小的默认框,其余4种分别对应1个默认框。这样保持了最后还是输出6种scale的feature map。
十分便捷与迅速!准确率也较高,实时情况下非常棒~。
 上海第二工业大学 18智能A1 周小夏(CV调包侠)
上海第二工业大学 18智能A1 周小夏(CV调包侠)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










