这两天想到一个问题, raft算法的成员共识性问题。我之前的理解是: Raft有共识性问题。 当未实现所有日志提交的Follower,之后被选举为新的leader之后, 源于raft日志的leader覆盖规则, 将导致数据丢失。 ↑↑上面这个想法是错误的↑↑, 关于 选举流程参考网站:https://thesecretlivesofdata.com/raft/ 由于是多线程操作, 时序图与流程图皆不好画, 请参阅文字: 如上选举算法设计, 合理的确保下如下表格中的case, 能快速选上leader、且非过半宕机时,集群可用: 此处讲解的一致性, 分为两点: 正常运行态, Raft的写满足强一致性/线性一致性。 但是针对这个算法, 也有优化, 例如对比 本节讲的是集群某些机器宕机, 数据也没有来得及同步的情况下, 集群如何保证的数据一致性。 极端情况,新Leader上位,集群状态却如下图: 毕竟 那类似这种情况, 如上操作确保了只有持有最新日志的节点才能成为 这部分功能没有实现, 具体可参阅 https://blog.csdn.net/luoyhang003/article/details/61915666
前言
Raft算法为主从结构, 其分布式一致性来源于集群的写全委托给Leader, Leader进程自身保证顺序与一致性, 并发起投票要求Follower追加写, 一旦过半赞成写请求(同时附加写的动作), 则该写完成。
.
需要注意的是, 集群的写是线性一致性/强一致性的, 同时基于Follower转发的集群的读也是现行一致性/强一致性的。并非ZAB的顺序一致性。Raft算法的安全性保证(阻止不包含最新Term和日志编号的Follower成为Leader、复制旧Leader数据)达成共识,确保了成员数据的一致性(相应的,ZAB使用主从相互拷贝的形式,达成集群共识)。
Raft, 我对其做了一个Java版的实现, 地址在: https://github.com/srctar/raft。 欢迎阅读。
目前实现了 raft 协议的下述功能:
Raft算法选举
本文的部分图片以及理论基础参考: https://blog.csdn.net/luoyhang003/article/details/61915666
如下Gif:
选举主要注意两点:
Raft为集群状态定义为: ELECTION(选举态), PROCESSING(运行态)
.
每个Raft节点有三个状态:FOLLOWER、LEADER、CANDIDATE(选举者)
a. 独立线程可以位于FOLLOWER, 也可以位于刚启动的集群节点,还可以位于宕机、网络中断的节点。
b. LEADER节点无该独立线程(它负责给别的节点发心跳)。
c. –
a.此操作非常重要,用以防止选票分散,进而导致长期超时
b.休眠中的线程可以接受投票。
c. –
a. 节点处于集群选举中ELECTION,且未给任何节点投票,节点默认接受投票申请。
b. –LEADER。 关闭心跳线程, 同时给其它节点发送心跳。
a. 节点处于运行态 PROCESSING, 且自身是LEADER,显然,一定有个老leader网断了,然后又网好了。 只要对方的Term大于自己, 那自己立马转化为FOLLOWER。
b. –FOLLOWER, 同时重设心跳线程。
a. 注意, 节点处于选举态 ELECTION, 需要心跳发送者的Term高于自己,否则返回拒绝(APPEND_ENTRIES_DENY)
b. 节点处于运行态 PROCESSING, 需要匹配心跳者是否是集群LEADER。是则重置心跳线程, 否则直接拒绝。
c. –
Case
担忧点
解决方案
正常启动选Leader
选不上
重选/启动时参与选举有线程休眠时间150~300ms, 此时接受投票一定赞同,确保选举
不过半的
Follower宕机/失联可用性
可用,
Leader不宕机,不影响选举, 不过半宕机,不影响数据投票
过半Follower宕机
可用性
Leader不宕机,还能接受数据, 过半宕机,影响数据投票, 集群不可用
不过半宕机, 包含
Leader可用性
可用, 心跳超时再选举, 通常一轮就能选出新
Leader,集群正常服务
不过半宕机, 包含
Leader可用性
不可用, 选不出
Leader
Leader失联集群状态
其他机器依旧能选上新
Leader, 期序Term累加,旧Leader恢复之后接受心跳转为Follower
Leader宕机集群状态
其他机器依旧能选上新
Leader, 重启之后接受心跳转为FollowerRaft算法数据一致性
正常运行态的强一致性
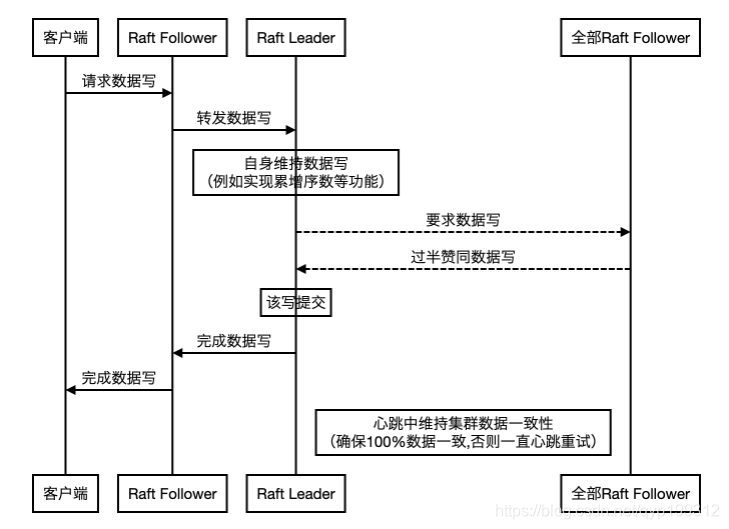
但是读也能满足到线性一致性。
Raft协议定义, 读由Follower转发给Leader, 因此能够保证最新commited读, 这种Case下,也无须关心过半不赞同的回滚策略。数据不提交即可。Follower和Leader的commitIndex, 一致的话由Follower读, 也是线性一致的。Raft集群的数据共识(集群恢复时)
↓↓↓↓↓↓↓↓注意下面例子,Raft是解决了的, 实际并不存在↓↓↓↓↓↓↓↓
如上图,相对于新的leader:
Raft的同步逻辑,过半提交则为提交, 之后Leader一直重试保证数据一致。
像b, 网络不佳,就是没同步上;
像d, 它就是上一个leader,自身提交前,还没来得及集群同步,网断了;Raft集群的数据共识是怎么达成的呢? 如下方案:
Term外, 还匹配日志版本, 大于等于自身日志版本的投票才会被授予。以此确保多数赞成的数据是最新的。Leader上已提交(过半赞成)的日志,因为已提交, 则至少当前被复制条目以及之前的日志都是可以被提交的。Leader, 且它将会尝试复制老旧Leader的日志数据。
此项操作通过排序和重发布确保数据的有序性, 但是会一定程度的增加系统复杂度。Raft算法的其他集群变更、日志压缩功能
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










