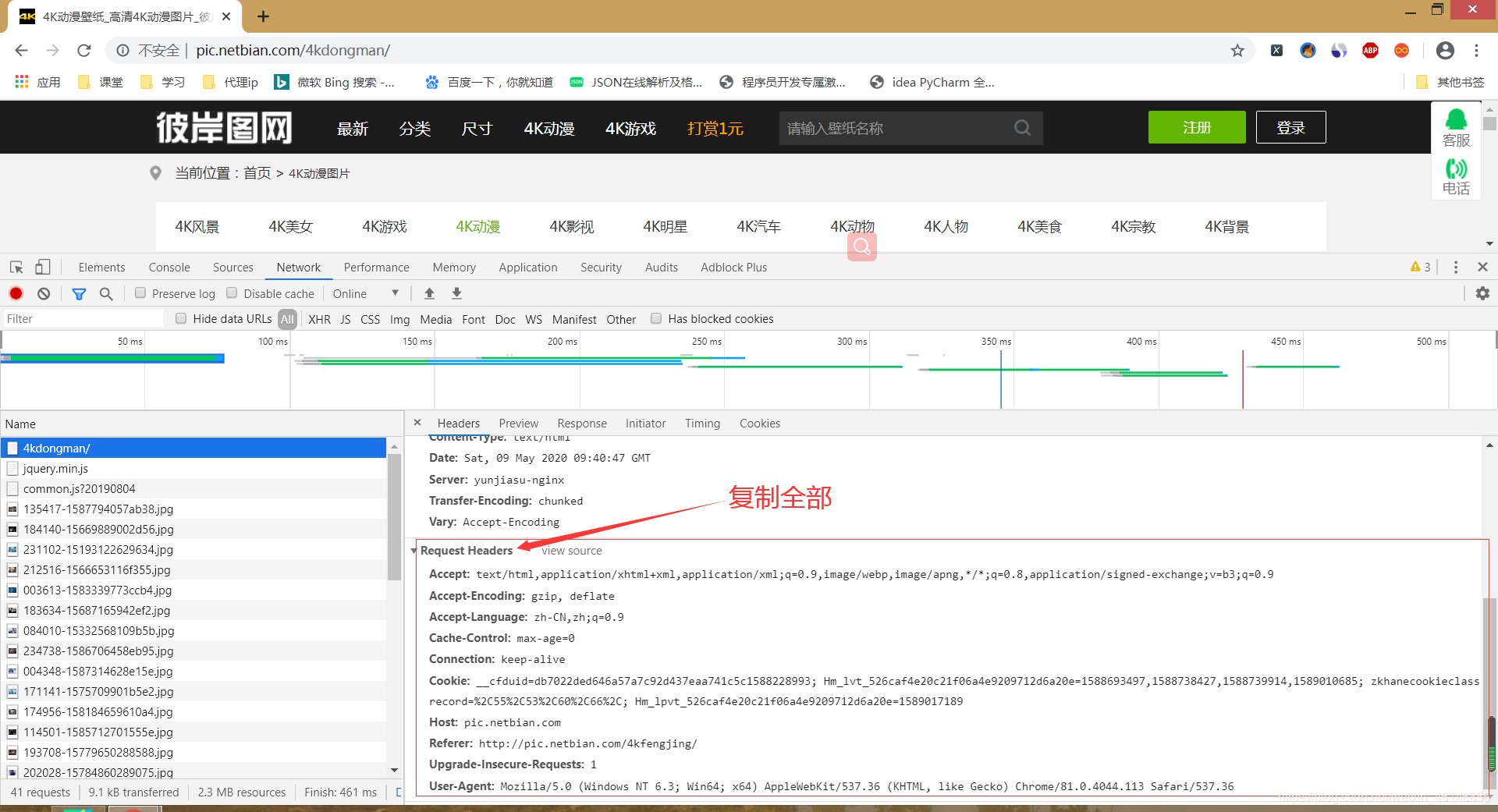
前言:看完此篇文章你可以更加深入的了解多线程的使用,并且最重要的你能够下载你自己想要的超高清4k壁纸 爬取结果: 1. 分析网站 a) 判断网页是动态加载还是静态加载页面。右击查看网页源代码,按Ctrl + f在源代码中搜索网站的详情页地址,从而判断整个网页是静态加载的 a) 我们可以通过字典的方式让用户选择需要爬取的内容,此时choice_ty的值就是我们要爬取类别的url的后部分内容,我们只需要拼接即可获取网页的url了。 b) 批量处理请求头。我们先添加请求头,这里我告诉大家一个在pycharm中批量处理请求头的方法。 首先复制所有的请求头 完整代码如下: 结语:欢乐的学习时光就结束了,有任何问题的可以在下方留言,我看到了一定会回复的。希望你们能够在此篇文章中获取到你们想要的知识,要相信汗水不会欺骗你。 励志话语:做一个决定,并不难,难的是付诸行动,并且坚持到底。
多线程爬取4k美图壁纸

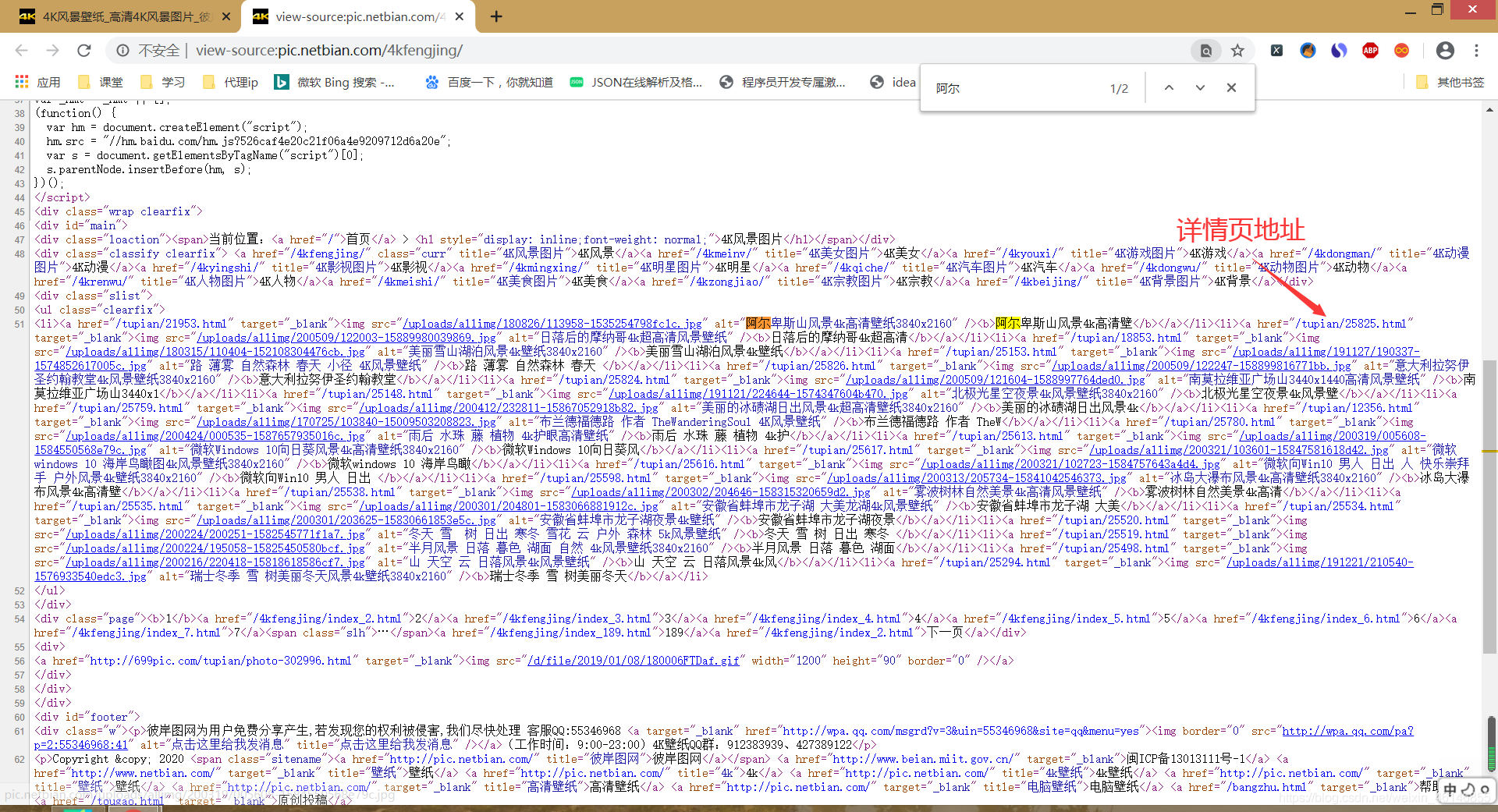
要爬取的url :https://pic.netbian.com/
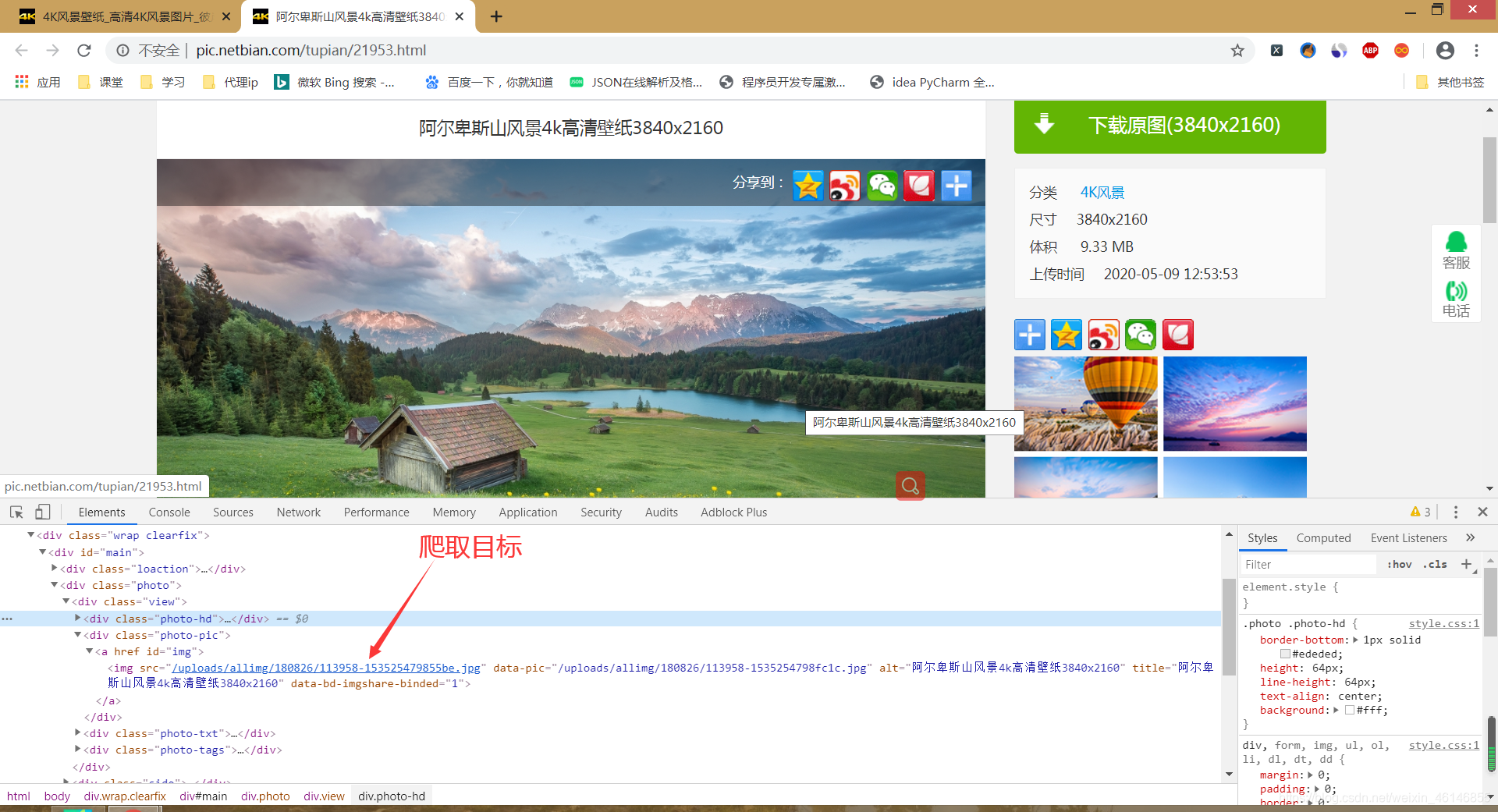
b) 明确爬取的目标。我们要爬取的目标是详情页的图片,因为详情页壁纸的大小比例才是我们想要的,索引页的壁纸比例都太小
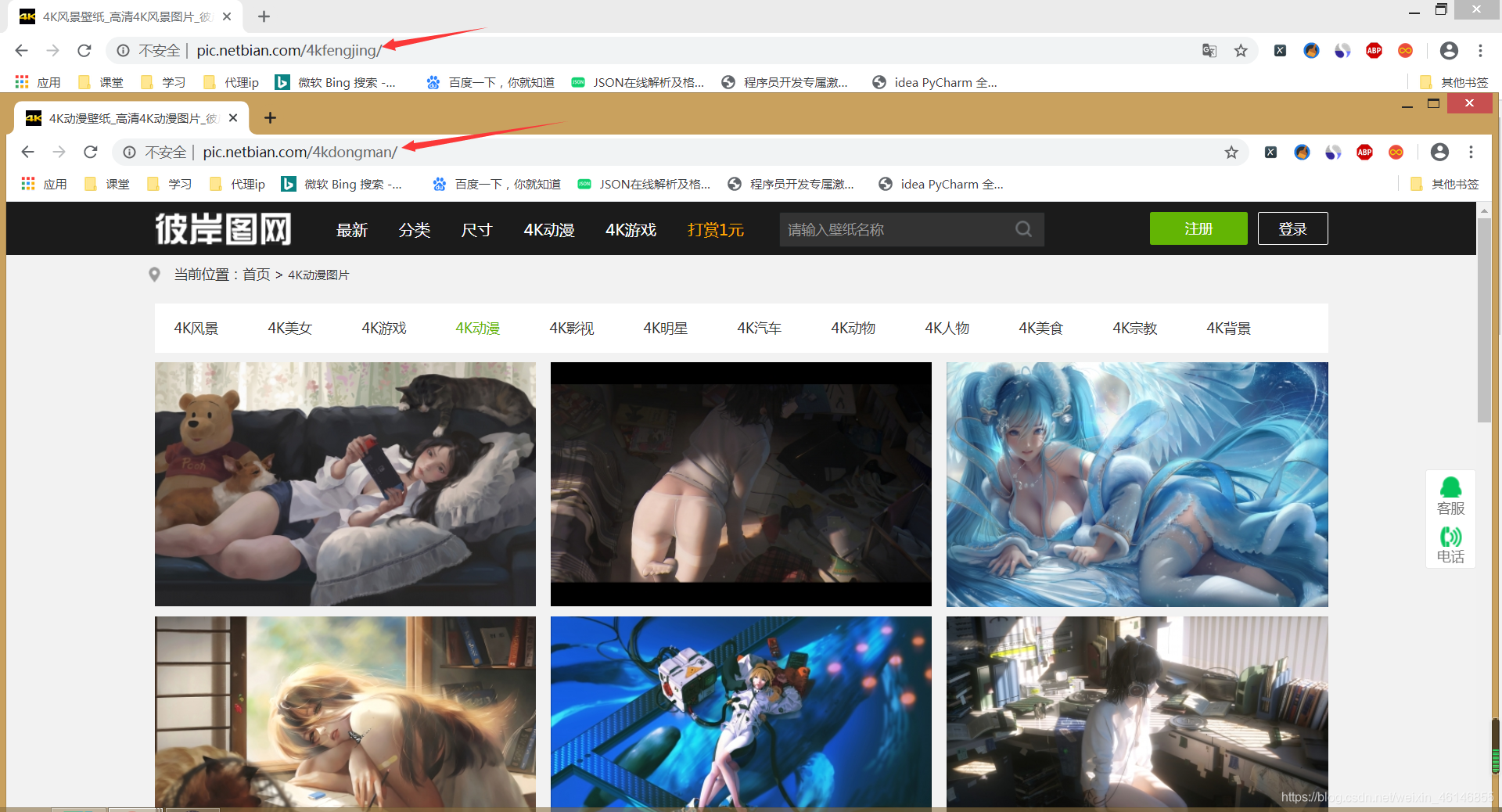
c) 分析类别。通过多次点击4K风景,4K动漫,4K影视我们可以发现url的变化,因为网页的结构都是一样的,所以我们只需要更改url就可以获取每个类别的壁纸了
2.代码演练 try: ty = input('请输入想要爬取的类型 n-风景-,-美女-,-游戏-,-动漫-,-影视-,-明星-,-汽车-,-动物-,-人物-,-美食-,-宗教-,-背景- n:') ty_dict = {'风景':'fengjing','美女':'meinv','游戏':'youxi','动漫':'dongman','影视':'yingshi','明星':'mingxing', '汽车':'qiche','动物':'dongwu','人物':'renwu','美食':'meishi','宗教':'zongjiao','背景':'beijing'} choice_ty = ty_dict[ty] except KeyError: print('请输入正确的类型')
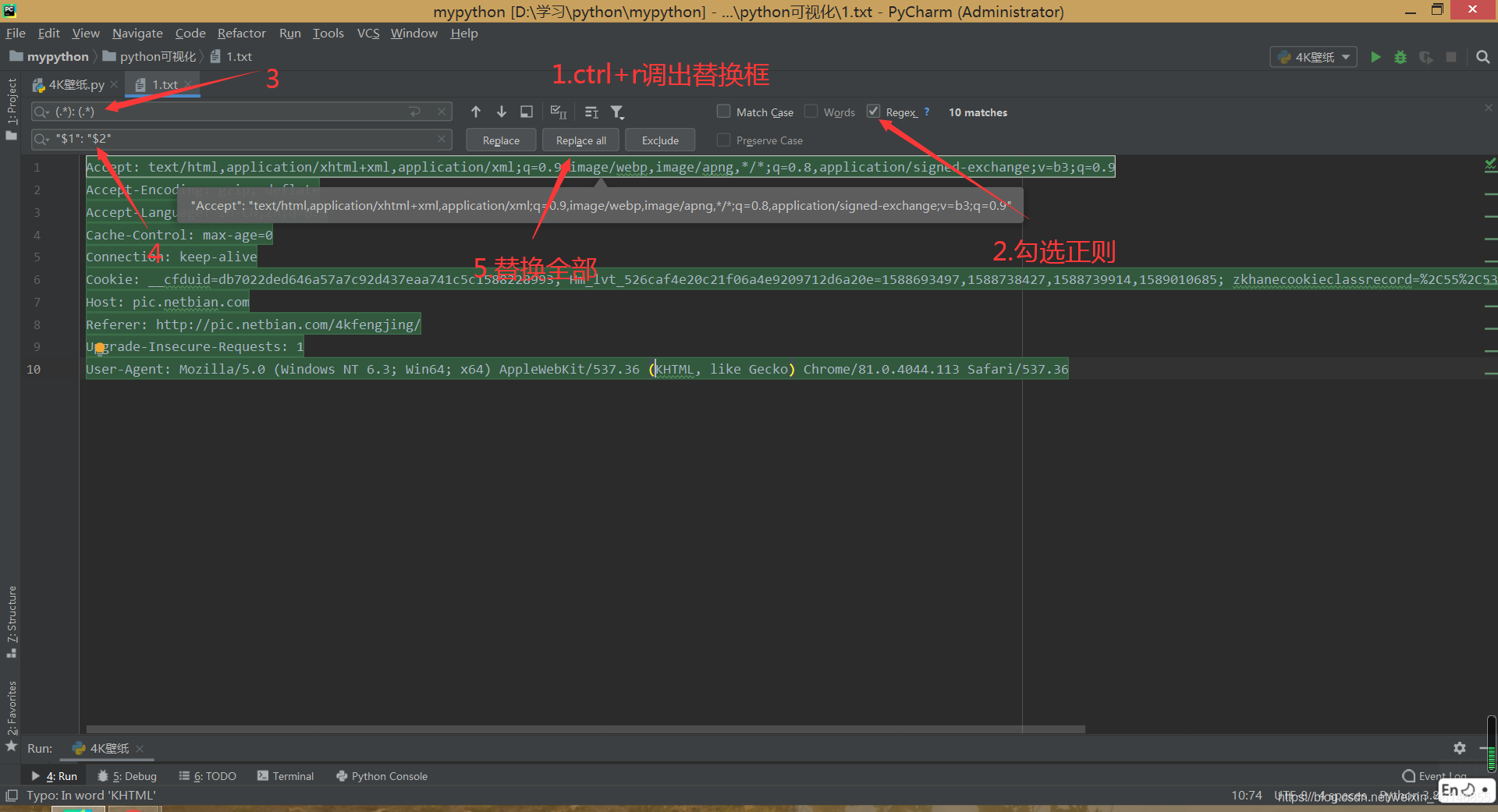
2.在pycharm中建立一个以.txt结尾的文件在上面的搜索框中输入(.): (.),在下面的搜索框中输入”$1″: “$2″即可获得格式化后的请求头
c) 由于在此不好讲解,我会将更细一步的讲解全放在完整代码中。import requests,os from lxml import etree from queue import Queue from threading import Thread class WallPaper4K(object): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36'} # 请求索引页和详情页的请求头 self.url_list = Queue() # 创建url的队列 # 请求下载图片的请求头,你们可以用我教的方法批量处理请求头。 self.HEADERS = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9", "Cache-Control": "max-age=0", "Connection": "keep-alive", "Cookie": "__cfduid=db7022ded646a57a7c92d437eaa741c5c1588228993; Hm_lvt_526caf4e20c21f06a4e9209712d6a20e=1588339511,1588670116,1588677703,1588684950; zkhanecookieclassrecord=%2C65%2C53%2C66%2C; Hm_lpvt_526caf4e20c21f06a4e9209712d6a20e=1588685839", "Host": "pic.netbian.com", "If-Modified-Since": "Mon, 30 Mar 2020 16:35:52 GMT", "If-None-Match": "'5e821fe8-4a440'", "Referer": "https://pic.netbian.com/tupian/25685.html", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"} # 解析索引页,并获取索引页中详情页的url def parse_index(self): while not self.url_list.empty(): response = requests.get(self.url_list.get(),headers=self.headers).content.decode('gbk') html = etree.HTML(response) # 创建用于使用xpath的对象 details_urls = html.xpath("//ul[@class='clearfix']//li/a/@href") # 使用xpath提取出所有详情页的url for url in details_urls: # 遍历获取每个详情页的url detail_url = 'https://pic.netbian.com/' + url # 因为获取的url不是完整的url,所以这里需要进行拼接 self.par_detail_url(detail_url) # 将拼接后的详情页url传给par_detail_url方法去解析详情页 def par_detail_url(self,url): res = requests.get(url,headers=self.headers).content.decode('gbk') # 向详情页发送请求获取响应 html = etree.HTML(res) img_url = 'https://pic.netbian.com/' + html.xpath("//a[@id='img']/img/@src")[0] # 因为在详情页获取的图片url不是完整的所以需要进行拼接 name = html.xpath("//h1/text()")[0] # 获取图片的名字 self.save_image(img_url,name) # 将拼接后的图片url和图片名称传给save_image方法 def save_image(self,img_url,name): try: # 这里最好加上异常捕获 res = requests.get(img_url,timeout=3).content # 向图片的下载地址发送请求获取响应,并用.content将其转为二进制数据 filename = 'F:/图片/' if not os.path.exists(filename): # 使用os库中的path模块判断电脑中的filename路径的文件夹是否创建,如果没有则创建 os.makedirs(filename) # 打开一个文件并保存数据 with open(filename+'{}.jpg'.format(name),'wb')as f: # 注意图片的后缀为.jpg f.write(res) # 保存的图片得为二进制数据 print('已下载{}'.format(name)) except Exception: print('下载失败{}'.format(name)) def main(self,choice_ty): self.url_list.put('https://pic.netbian.com/4k{}/'.format(choice_ty)) # 因为索引页中的第一页url和其余页数的url不同,所以这里需要单独添加到url的队列中 t_list = [] for i in range(2,200): url_index = 'https://pic.netbian.com/4k{}/index_{}.html'.format(choice_ty,i) # 使用format方法将用户输入的选择和页数拼接成完整的url_index self.url_list.put(url_index) # 将拼接后的url放入到url的队列中 for x in range(10): # 开启10个线程,注意:线程不要过多,否则对方服务器会有压力 t1 = Thread(target=self.parse_index) # 创建线程 t1.start() # 启动线程 t_list.append(t1) # 将线程放入到t_list中 for t in t_list: # 遍历t_list列表并使用join()方法使主线程等待其它线程结束 t.join() if __name__ == '__main__': # 用户输入的过程和从字典中取值过程得加上异常捕获,以免出现keyerror try: ty = input('请输入想要爬取的类型 n-风景-,-美女-,-游戏-,-动漫-,-影视-,-明星-,-汽车-,-动物-,-人物-,-美食-,-宗教-,-背景- n:') # 得到用户的输入 # 创建类别的字典 ty_dict = {'风景':'fengjing','美女':'meinv','游戏':'youxi','动漫':'dongman','影视':'yingshi','明星':'mingxing', '汽车':'qiche','动物':'dongwu','人物':'renwu','美食':'meishi','宗教':'zongjiao','背景':'beijing'} choice_ty = ty_dict[ty] # 根据用户的输入取出字典中所对应的值 spider = WallPaper4K() spider.main(choice_ty) except KeyError: print('输入有误,请重新输入')
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











