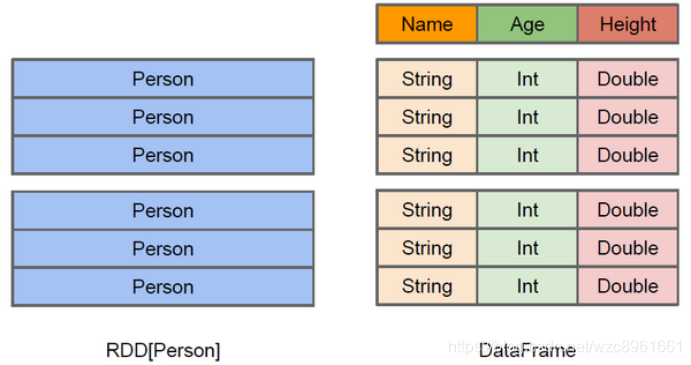
官网 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象: 我们已经学习了Hive,它是 优点 缺点 SparkSQL可以理解成是将SQL解析成’RDD’ + 优化再执行 两种数据抽象 上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,DataFrame也是懒执行的。性能上比RDD要高,主要原因: 如下示例: 1) 2)与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。 3)与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查。 4)调用Dataset的方法先会生成逻辑计划,然后被spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行! 结构图解 RDD[Person] DataFrame DataSet[Person]
目录
Spark SQL官方介绍
什么是Spark SQL
DataFrame和DataSet,并且作为分布式SQL查询引擎的作用。将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduc的程序的复杂性 ,由于MapReduce这种计算模型执行效率比较慢。所有Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!Spark SQL的特点
1、易整合

2、统一的数据访问方式

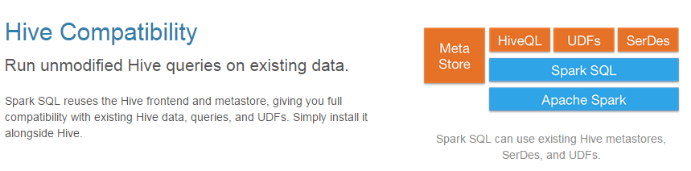
3、兼容Hive
4、标准的数据连接

Spark SQL的优缺点
Hive和Spark SQL
Hive是将SQL转为MapReduce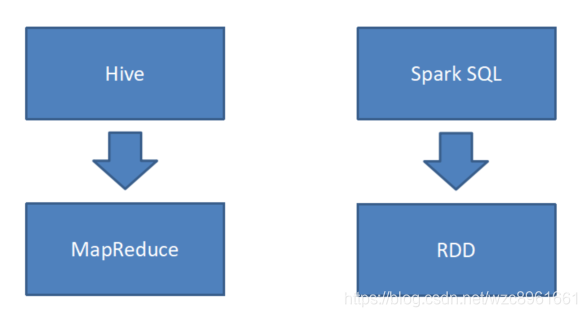
Spark SQL数据抽象
什么是 DataFrame
DataFrame是一种以RDD为基础的带有Schema元信息的分布式数据集,类似于传统数据库的二维表格。
除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
优化的执行计划:查询计划通过Spark catalyst optimiser进行优化。

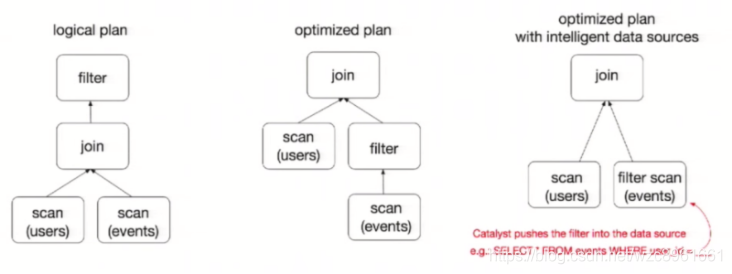
为了说明查询优化,图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。什么是 DataSet
DataSet是保存了更多的描述信息,类型信息的分布式数据集。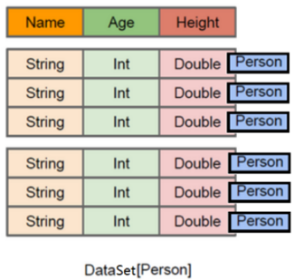
DataSet包含了DataFrame的功能,
Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
DataFrame其实就是Dateset[Row]。

RDD、DataFrame、DataSet的区别

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











