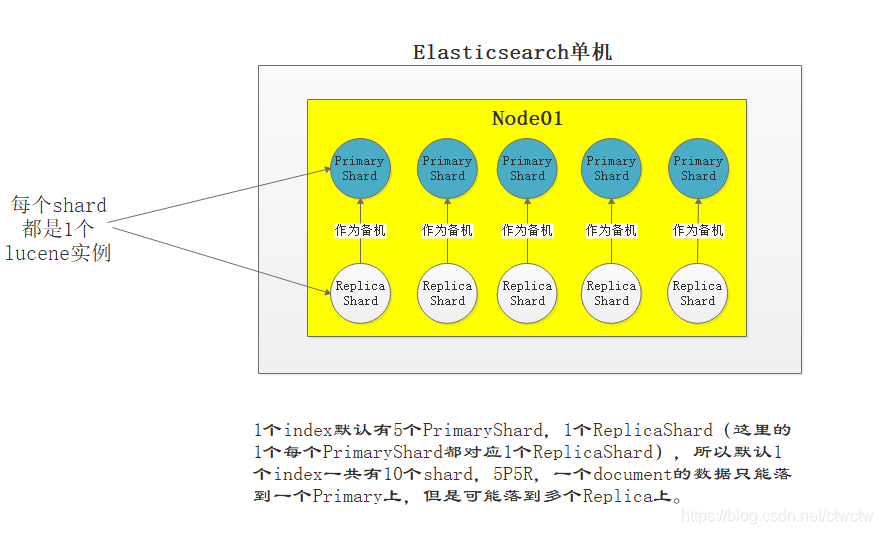
Near Realtime,也称NRT。这里包含两个含义 一个集群包含多个node(节点,至少两个,否则不叫集群),每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的。启动多个es实例就自动构成一个集群。它默认会找9300-9305这端口范围的实例,官方有写: Node:节点。多个Node凑成一个集群,我理解每个Elasticsearch实例就是一个Node。 就是字段,一个document里可包含多个field,看完下面的document就明白了。 文档,ES中的最小数据单元,通常用JSON表示,理解成mysql里的一条数据。 索引,包含一堆有相似结构的文档数据。举个例子:商品索引、用户索引这是两个完全不同的东西,所以建议弄两个index。 可以粗糙理解成mysql的库的概念。有点模糊?看完下面的type就懂了。 每个index下的具体分类。一个index可以有多个type。比如上面index举例的商品索引,下面可以包含家电商品、生鲜商品、生活用品等,可以粗糙理解成mysql表的概念。 Index理解成数据库、type理解成数据表、document理解成数据行。一个index下有多个type,每个type下有多个document。 分为两种:Primary Shard以及Replica Shard。 假设只有1个index,每个index默认5P5R。假设只有一台node,那肯定这10个shard都在这一台node上,假设新增了一台node实例与之前的凑成了集群。那么ES会自动将这个shard平分到两台node上,比如: Primary和Replica不能同时存到同一个node上,否则这个node挂了就单点故障了 ,不叫高可用。
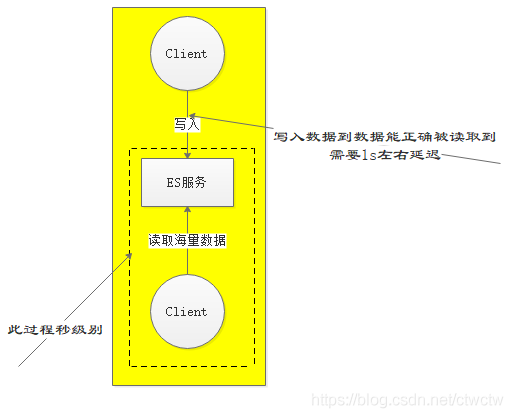
一、近实时
二、天然支持集群
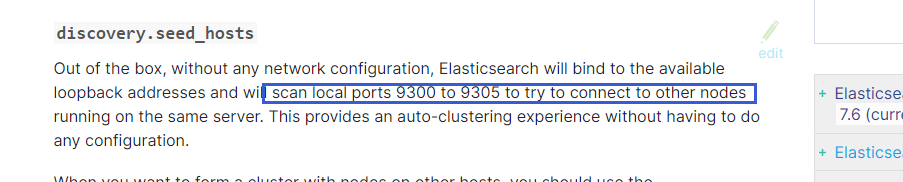
https://www.elastic.co/guide/en/elasticsearch/reference/current/discovery-settings.html三、Node
四、field
五、Document
{ "id": 1, "name": "小米", "price": { "型号1": 999, "型号2": 1999, "型号3": 2999 } } 六、index
七、type
八、小结以及注意
Elasticsearch已经将type这个概念去掉了,也就是只有index和document的概念,相当于index就对应到mysql的库表。
因为type的概念是错误的使用方式,毕竟在RDBMS中,表与表之间的数据是分割存储的,而ES中同一个索引的不同type数据最终是放在一起的,必须保证不同type之间同名field的类型一致,还不算其他乱七八糟的问题。设计上就不合理。九、shard
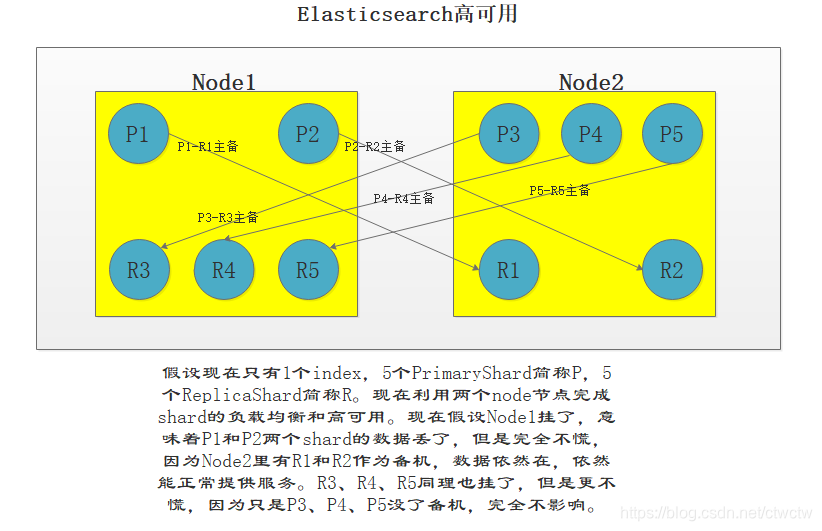
Anode:2个PrimaryShard+3个ReplicaShard(这3个是Bnode中3P的副本,这样可以保证高可用)
Bnode:3个PrimaryShard+2个ReplicaShard(这2个是Anode中2P的副本,这样可以保证高可用)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











