本次 我们要爬取的是一个漂亮mm的网站~ 首先 观察这个网站~: 哇,真好看 ,,咳咳 所谓兵马未动,粮草先行: 发现 : 网页以1.2.3.4,5…划分: 发现 : 确实,这个网页第几页第几页很简单,就一个数字1 2:再来观察图片格式
来来来 话不多说,直奔主题
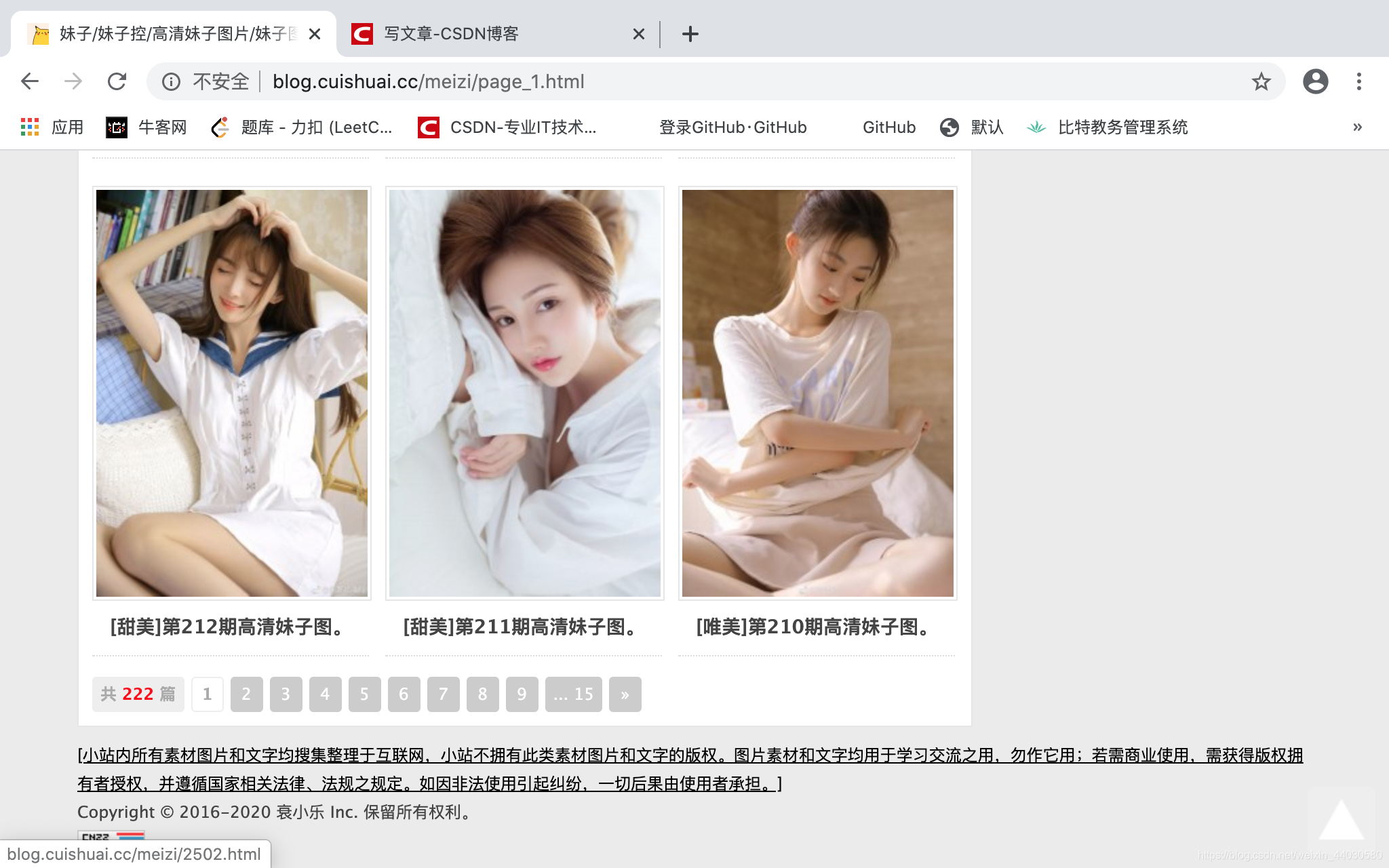
下边的页面有 16页之多。那么我们就先爬个10页的吧第一步: 踩点
1 观察网站url 格式
多观察几页发现: https://blog.cuishuai.cc/meizi/page_1.html https://blog.cuishuai.cc/meizi/page_2.html https://blog.cuishuai.cc/meizi/page_3.html
我们在开看看底层
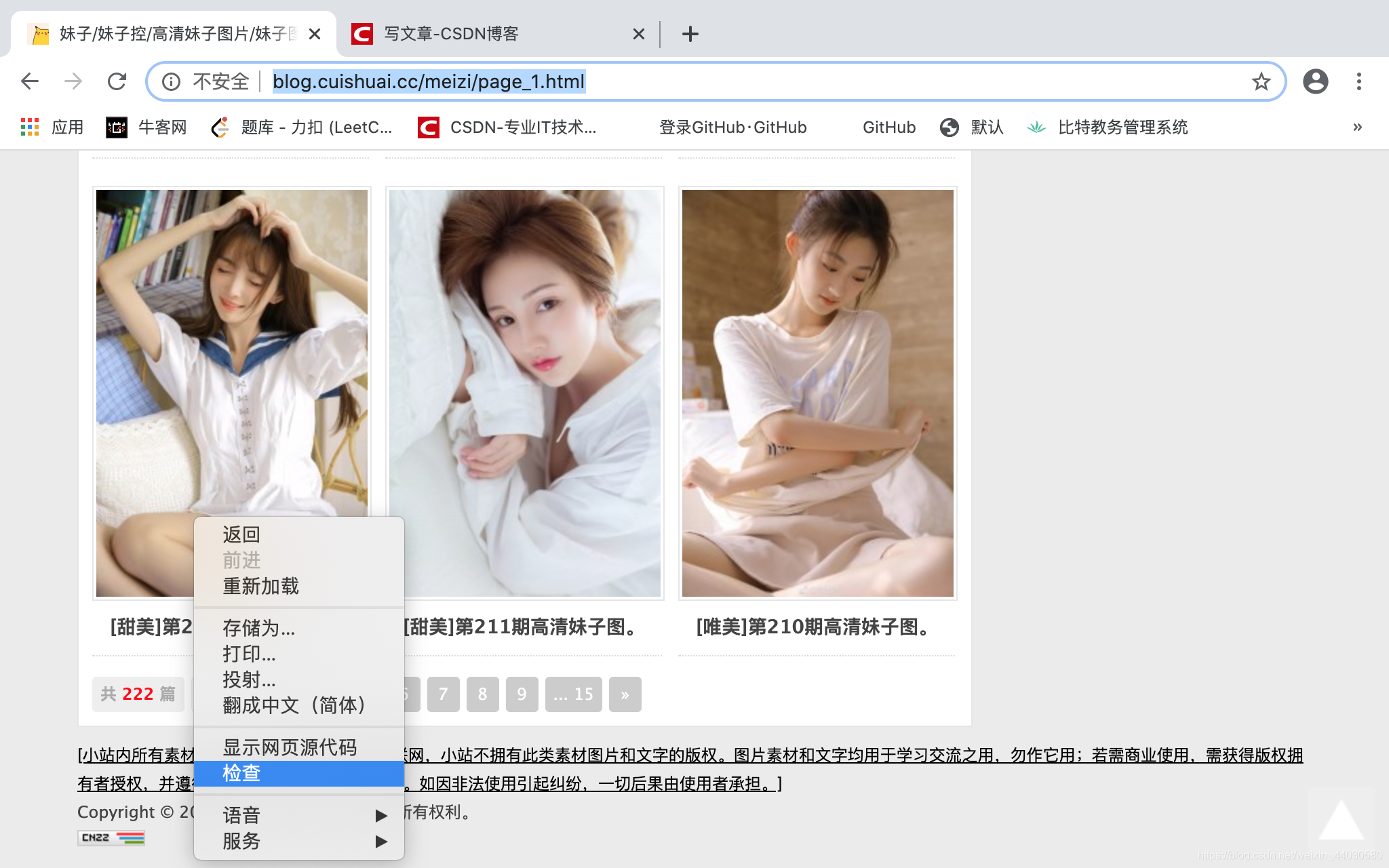
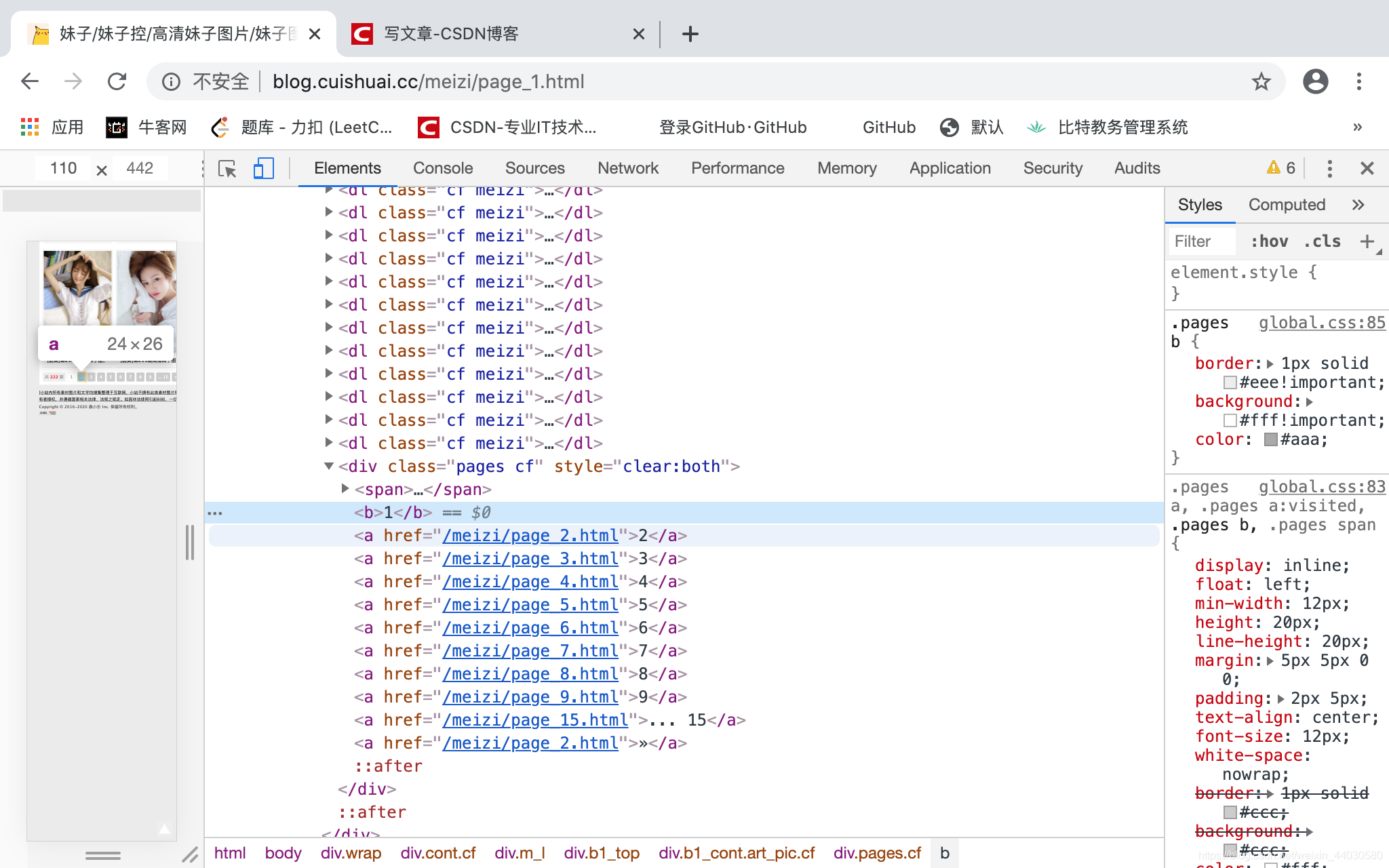
那么访问不同页面的代码 就非常好写了page_url = 'https://blog.cuishuai.cc/meizi/page_' + str(i) + '.html' 
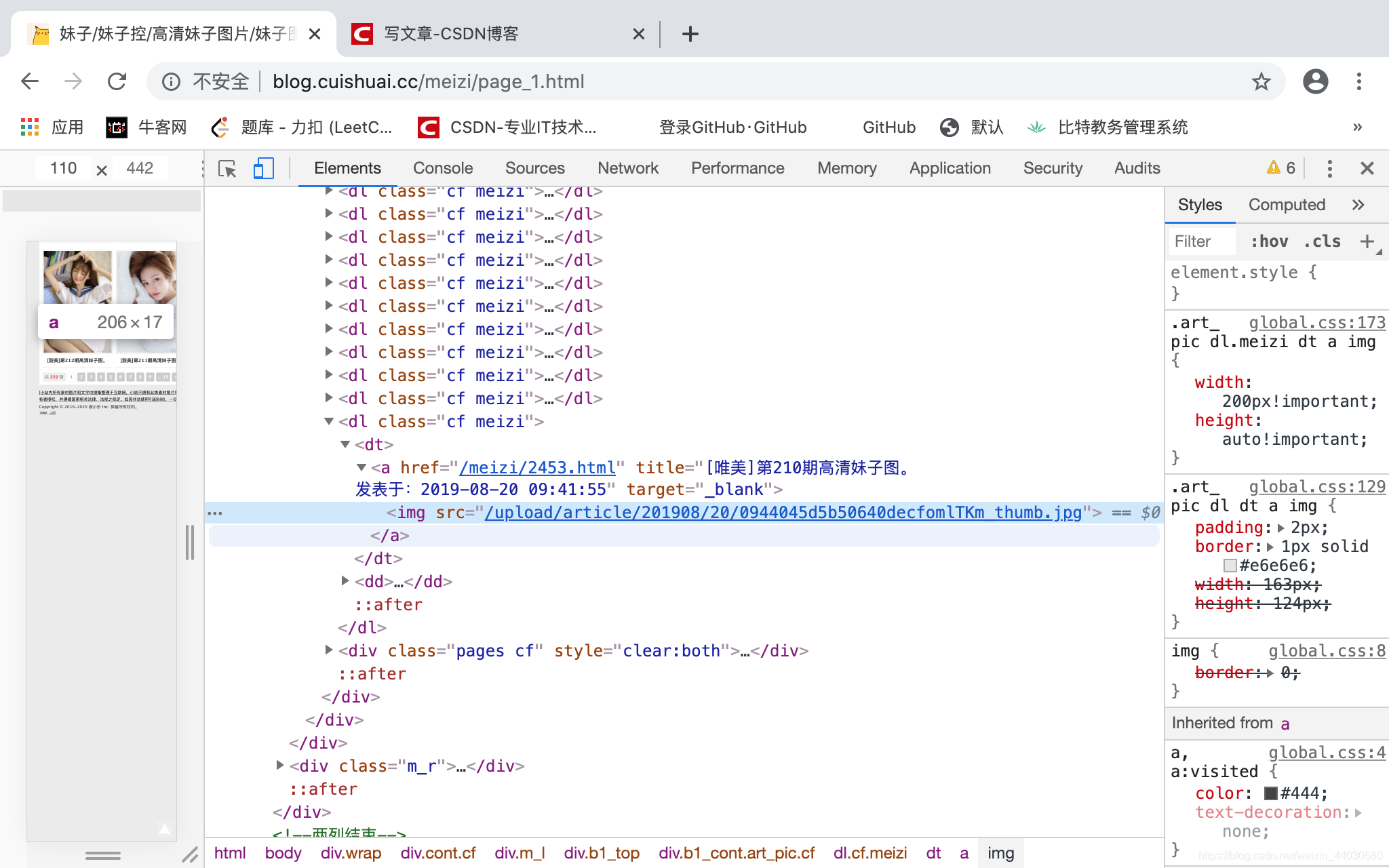
图片以 /img src” 打头 以 .jpg结尾
那也很好识别了看代码
import urllib.request import os #https://blog.cuishuai.cc/meizi/page_4.html def open_url(url): req = urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Mobile Safari/537.36') response = urllib.request.urlopen(req) html = response.read() return html #获取所在页 def get_page(url): html = open_url(url).decode() a = html.find('current-comment-page') + 23 b = html.find(']',a) print(a) print(b) print(html[a:b]) return html[a:b] #/<img src="/upload/article/201807/06/0950225b3ecadeb5a8flqnJnM_thumb.jpg"> #寻找图片 def find_imag(url): html = open_url(url).decode('utf-8') imag_addrs =[] #存放找到图片的地址 a = html.find('img src=') while a != -1: b = html.find('.jpg',a, a+255) if b != -1: imag_addrs.append(html[a+9:b+4]) #找到了 ,保存图片地址 else: b = a + 9 # 从a+9处开始从新找 a = html.find('img src',b) for i in imag_addrs: print(i) return imag_addrs #保存图片 def save_imag(folder,imag_addr): count =0; for each in imag_addr: count += 1 if count > 6:#这里+6 是为了避开无关动图,去掉count你会发网页有6张影响我们的动图--》广告。你可以在页面最上方发现的 filename = each.split('/')[-1] #最后一个/后的就是文件名 print(filename) with open(filename, 'wb') as f: imag = open_url(each) #打开每张图片,获得二进制数据 f.write(imag) #将图片写入文件 #准备下载 def download_mm(folder ='ooxx', pages =10): os.mkdir(folder) os.chdir(folder) url= 'https://blog.cuishuai.cc/meizi/' #page_num = int (get_page(url)) open_url(url) for i in range(pages): #page_num -= i page_url = url + 'page_' + str(i) + '.html'#拼成链接 imag_addr = find_imag(page_url)#打开链接找到图片 save_imag(folder, imag_addr) if __name__ == '__main__': download_mm() 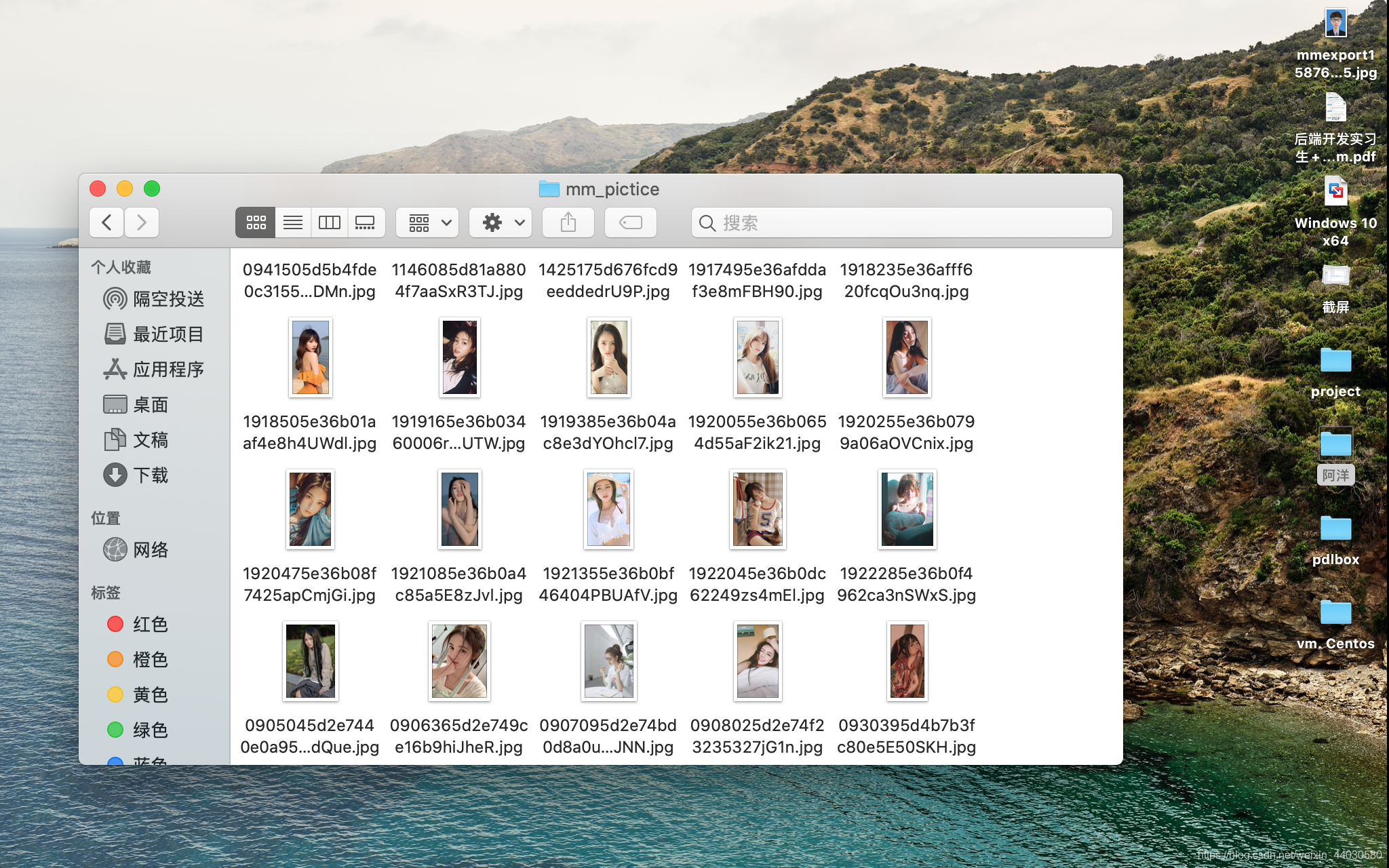
怎么样 ,美好吧~~ 留个赞呗
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











