RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。 (1)读取一个HDFS文件并将其中内容映射成一个个元组 (2)统计每一种key对应的个数 (3)查看“wordAndOne”的Lineage (4)查看“wordAndCount”的Lineage (5)查看“wordAndOne”的依赖类型 (6)查看“wordAndCount”的依赖类型 注意:RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。 两种依赖关系类型 RDD和它依赖的父RDD的关系有两种不同的类型,即 窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用, 宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle, 面试题 子RDD的一个分区依赖多个父RDD是宽依赖还是窄依赖? 不能确定,也就是宽窄依赖的划分依据是父RDD的一个分区是否被子RDD的多个分区所依赖,是,就是宽依赖,或者从shuffle的角度去判断,有shuffle就是宽依赖 1.对于窄依赖 Spark可以并行计算 2.对于宽依赖 是划分Stage的依据 DAG(Directed Acyclic Graph有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是RDD执行的流程) 开始:通过SparkContext创建的RDD 注意: 一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action 如何划分DAG的Stage 对于窄依赖,partition的转换处理在stage中完成计算,不划分(将窄依赖尽量放在在同一个stage中,可以实现流水线计算) 对于宽依赖,由于有shuffle的存在,只能在父RDD处理完成后,才能开始接下来的计算,也就是说需要要划分stage(出现宽依赖即拆分) 小结 具体的划分算法请参见AMP实验室发表的论文
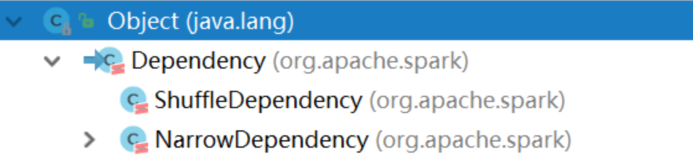
Lineage
scala> val wordAndOne = sc.textFile("/fruit.tsv").flatMap(_.split("t")).map((_,1)) wordAndOne: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[22] at map at <console>:24 scala> val wordAndCount = wordAndOne.reduceByKey(_+_) wordAndCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[23] at reduceByKey at <console>:26 scala> wordAndOne.toDebugString res5: String = (2) MapPartitionsRDD[22] at map at <console>:24 [] | MapPartitionsRDD[21] at flatMap at <console>:24 [] | /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 [] | /fruit.tsv HadoopRDD[19] at textFile at <console>:24 [] scala> wordAndCount.toDebugString res6: String = (2) ShuffledRDD[23] at reduceByKey at <console>:26 [] +-(2) MapPartitionsRDD[22] at map at <console>:24 [] | MapPartitionsRDD[21] at flatMap at <console>:24 [] | /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 [] | /fruit.tsv HadoopRDD[19] at textFile at <console>:24 [] scala> wordAndOne.dependencies res7: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@5d5db92b) scala> wordAndCount.dependencies res8: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@63f3e6a8) 宽窄依赖
窄依赖我们形象的比喻为独生子女宽依赖我们形象的比喻为超生
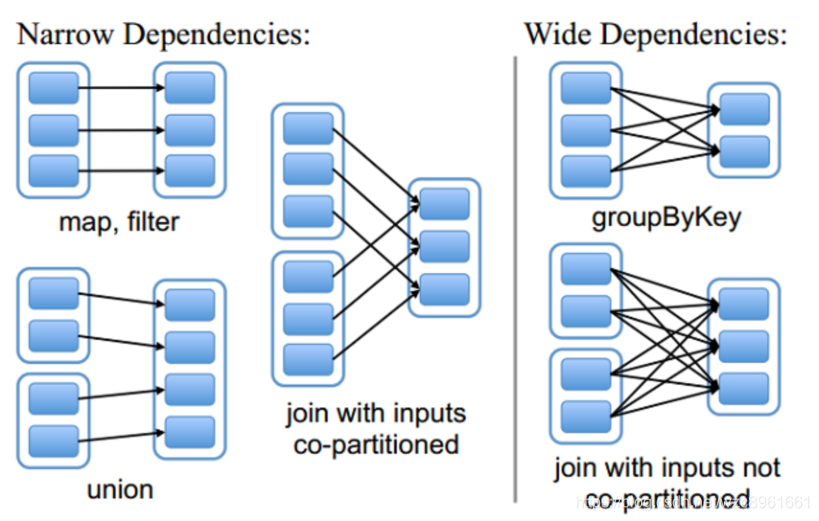
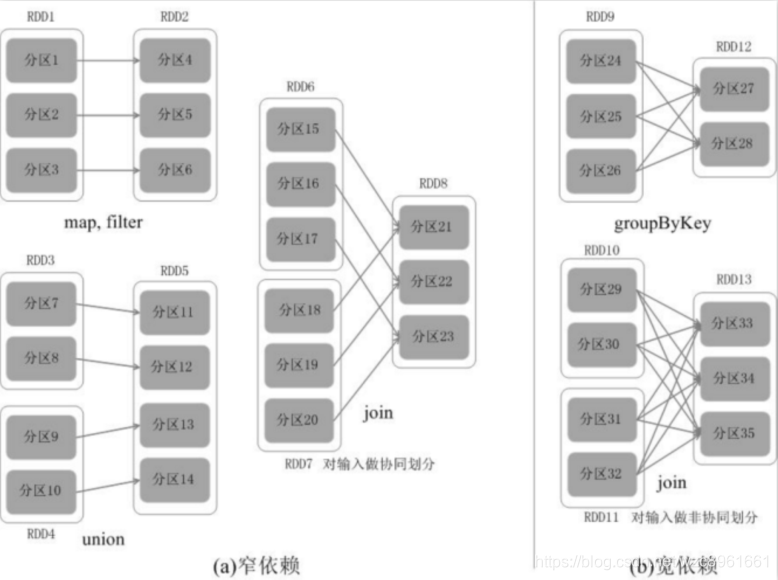
如何区分宽窄依赖
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)为什么要设计宽窄依赖
如果有一个分区数据丢失,只需要从父RDD的对应1个分区重新计算即可,不需要重新计算整个任务,提高容错。DAG(有向无环图)
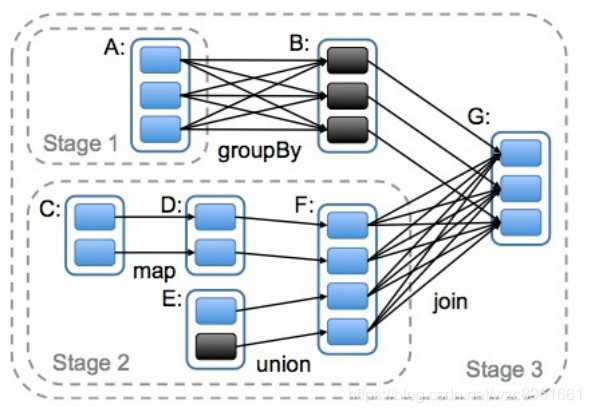
DAG是什么
原始的RDD通过一系列的转换操作就形成了DAG有向无环图,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)DAG的边界
结束:触发Action,一旦触发Action就形成了一个完整的DAG
一个DAG中会有不同的阶段/stage,划分阶段/stage的依据就是宽依赖
一个阶段/stage中可以有多个Task,一个分区对应一个TaskDAG划分Stage
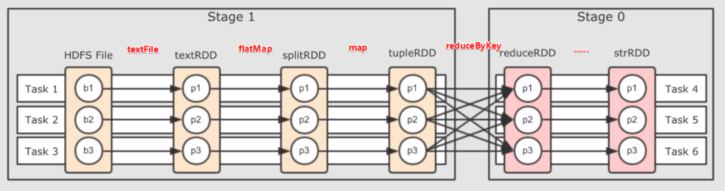
为什么要划分Stage??(并行计算)
一个复杂的业务逻辑如果有shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle进行划分(也就是按照宽依赖就行划分),就可以将一个DAG划分成多个Stage/阶段,在同一个Stage中,会有多个算子操作,可以形成一个pipeline流水线,流水线内的多个平行的分区可以并行执行
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
https://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











