在retinanet中的网络和候选框的生成划分很明显,源代码好像不能直接运行,这里我修改了,可以单独运行测试,本章就来学习在数据预处理阶段就对框的生成,以及按照iou排序,这样就极大方面训练。代码层次非常清晰。 这部分的加载属于正常的操作,不同普通的训练集,这里txt文件如下所示 这部分代码的话属于基础的数据加载,关键点在于返回的不再是img,位置,标签,而是已经处理过的位置,标签,中间的数据增强部分在我的博客中有单独讲解,所以我们只需要关注如何将位置和标签处理成我们训练是的位置和标签。 这一步只是生成了9中框的大小,不同特征图的框大小不同。如下图所示p3特征图的情况,这里不是真正的框信息,还需要处理。 在来单独讲解几个比较重要的函数,下面的encode会使用 这里的细节点是iou,跟以前目标检测的不同,这里候选框有一万多,而我们的真实框只有几个,整体计算流程是全部的候选框都与标签比较进行计算之间的iou,全部记录下来,有很多都是0.只有少部分是作为标签的。 这一部分自己看单独输出其中的一个环节,对比理解学习更容易掌握。
摘要
dataset数据加载

先是xyxy坐标点然后是label,如果一张照片很多框,后面继续按照这种格式。'''Load image/labels/boxes from an annotation file. The list file is like: img.jpg xmin ymin xmax ymax label xmin ymin xmax ymax label ... ''' from __future__ import print_function import os import sys import random import torch import torch.utils.data as data import torchvision.transforms as transforms from PIL import Image from encoder import DataEncoder from transform import resize, random_flip, random_crop, center_crop class ListDataset(data.Dataset): def __init__(self, root, list_file, train, transform, input_size): ''' Args: root: (str) ditectory to images. list_file: (str) path to index file. train: (boolean) train or test. transform: ([transforms]) image transforms. input_size: (int) model input size. ''' self.root = root self.train = train self.transform = transform self.input_size = input_size self.fnames = [] self.boxes = [] self.labels = [] self.encoder = DataEncoder() with open(list_file) as f: lines = f.readlines() self.num_samples = len(lines) for line in lines: splited = line.strip().split() self.fnames.append(splited[0]) num_boxes = (len(splited) - 1) // 5 box = [] label = [] for i in range(num_boxes): xmin = splited[1+5*i] ymin = splited[2+5*i] xmax = splited[3+5*i] ymax = splited[4+5*i] c = splited[5+5*i] box.append([float(xmin),float(ymin),float(xmax),float(ymax)]) label.append(int(c)) self.boxes.append(torch.Tensor(box)) self.labels.append(torch.LongTensor(label)) def __getitem__(self, idx): '''Load image. Args: idx: (int) image index. Returns: img: (tensor) image tensor. loc_targets: (tensor) location targets. cls_targets: (tensor) class label targets. ''' # Load image and boxes. fname = self.fnames[idx] img = Image.open(os.path.join(self.root, fname)) if img.mode != 'RGB': img = img.convert('RGB') boxes = self.boxes[idx].clone() labels = self.labels[idx] size = self.input_size # Data augmentation. if self.train: img, boxes = random_flip(img, boxes) img, boxes = random_crop(img, boxes) img, boxes = resize(img, boxes, (size,size)) else: img, boxes = resize(img, boxes, size) img, boxes = center_crop(img, boxes, (size,size)) img = self.transform(img) return img, boxes, labels def collate_fn(self, batch): '''Pad images and encode targets. As for images are of different sizes, we need to pad them to the same size. Args: batch: (list) of images, cls_targets, loc_targets. Returns: padded images, stacked cls_targets, stacked loc_targets. ''' imgs = [x[0] for x in batch] boxes = [x[1] for x in batch] labels = [x[2] for x in batch] h = w = self.input_size num_imgs = len(imgs) inputs = torch.zeros(num_imgs, 3, h, w) loc_targets = [] cls_targets = [] for i in range(num_imgs): inputs[i] = imgs[i] loc_target, cls_target = self.encoder.encode(boxes[i], labels[i], input_size=(w,h)) loc_targets.append(loc_target) cls_targets.append(cls_target) return inputs, torch.stack(loc_targets), torch.stack(cls_targets) def __len__(self): return self.num_samples def test(): import torchvision transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.485,0.456,0.406), (0.229,0.224,0.225)) ]) dataset = ListDataset(root='G:detectionimage', list_file='G:detectionimage/test.txt', train=True, transform=transform, input_size=300) dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0, collate_fn=dataset.collate_fn) for images, loc_targets, cls_targets in dataloader: print(images.size()) print(loc_targets.size()) print(cls_targets.size()) # grid = torchvision.utils.make_grid(images, 1) # torchvision.utils.save_image(grid, 'a.jpg') # break test() 框的生成
class DataEncoder: def __init__(self): self.anchor_areas = [32*32., 64*64., 128*128., 256*256., 512*512.] # p3 -> p7,这里是对应不同特征图大小所生的的基础框 self.aspect_ratios = [1/2., 1/1., 2/1.] #改变高宽比,将一种32*32的变成三种 self.scale_ratios = [1., pow(2,1/3.), pow(2,2/3.)] #在次按照大小比变化三种,一种9中框。 self.anchor_wh = self._get_anchor_wh() def _get_anchor_wh(self): '''Compute anchor width and height for each feature map. Returns: anchor_wh: (tensor) anchor wh, sized [#fm, #anchors_per_cell, 2]. ''' anchor_wh = [] for s in self.anchor_areas: for ar in self.aspect_ratios: # w/h = ar #生成三种不同的高宽比 h = math.sqrt(s/ar) w = ar * h for sr in self.scale_ratios: # scale 三种大小不同比 anchor_h = h*sr anchor_w = w*sr anchor_wh.append([anchor_w, anchor_h]) num_fms = len(self.anchor_areas) return torch.Tensor(anchor_wh).view(num_fms, -1, 2) #到此,就先将框的高和宽确定下来,真正的框还没有使用
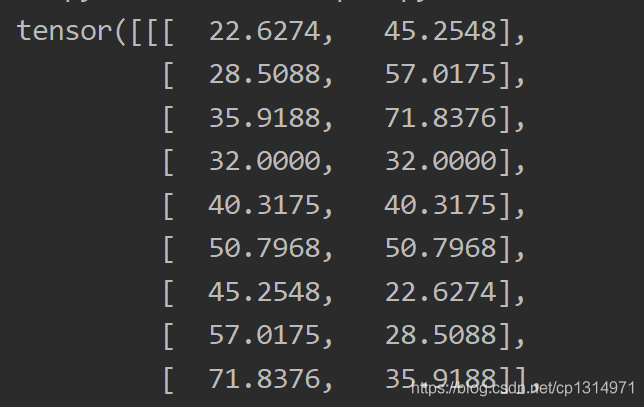
下面才是真正框的生成,有坐标点,有高和框,比如p3是生成38 38的特征图(我以输入300为例)目标检测FPN的核心点就是如何在多种特征图下输出的结果依旧对应原始的照片,38 38大小跟原始输入的照片完全不同,是如何进行预测?,其实在3838的特征图坐标点中使用的依旧是300 300的相对位置,举个简单的理解,在300 300的大小上均匀的选取38 38个核心点,在核心点的周围预测9中不同高和宽的框,所以坐标点计算的核心是先将300/38,知道每个点的距离,多有的点就可以均匀排列在300 300的特征图上
具体代码 def _get_anchor_boxes(self, input_size): '''Compute anchor boxes for each feature map. Args: input_size: (tensor) model input size of (w,h). Returns: boxes: (list) anchor boxes for each feature map. Each of size [#anchors,4], where #anchors = fmw * fmh * #anchors_per_cell ''' num_fms = len(self.anchor_areas) a = [(38, 38), (19, 19), (10, 10), (5, 5), (3, 3)] #这里对应源码修改了,我现在是确定为300的输入,为什么修改,因为源码不对 boxes = [] input_size=300.0 #这里必须是float类型 for i in range(num_fms): fm_size = a[i] grid_size = input_size / fm_size[0] #计算每个点需要相隔的距离 fm_w, fm_h = a[i] xy = meshgrid(fm_w, fm_h) + 0.5 # [fm_h*fm_w, 2] 这个是计算所有的下标位置 xy = (xy * grid_size).view(fm_h, fm_w, 1, 2).expand(fm_h, fm_w, 9, 2) #经过这一步就将所有的点排列在300*300大小的位置,xy * grid_size 下标乘距离,那么所有的下标就可以对应上300*300的特征图大小位置 #在最后我会将这部分代码单独输出的部分方面实验代码,可以自己输出一下就能理解。expand就是扩展成9种,因为有9中高和宽 xy = xy.float() wh = self.anchor_wh[i].view(1, 1, 9, 2).expand(fm_h, fm_w, 9, 2) #同理 wh = wh.float() box = torch.cat([xy, wh], dim=3) # [x,y,w,h] boxes.append(box.view(-1, 4)) return torch.cat(boxes, 0) def meshgrid(x, y, row_major=True): '''Return meshgrid in range x & y. Args: x: (int) first dim range. y: (int) second dim range. row_major: (bool) row major or column major. Returns: (tensor) meshgrid, sized [x*y,2] Example: >> meshgrid(3,2) 这里的理解讲解很明白,就是输出所有下标 0 0 1 0 2 0 0 1 1 1 2 1 [torch.FloatTensor of size 6x2] >> meshgrid(3,2,row_major=False) 0 0 0 1 0 2 1 0 1 1 1 2 [torch.FloatTensor of size 6x2] ''' a = torch.arange(0,x) b = torch.arange(0,y) xx = a.repeat(y).view(-1,1) yy = b.view(-1,1).repeat(1,x).view(-1,1) return torch.cat([xx,yy],1) if row_major else torch.cat([yy,xx],1) def change_box_order(boxes, order):#用来xyxy变成xywh,方便计算iou,或者变回去 '''Change box order between (xmin,ymin,xmax,ymax) and (xcenter,ycenter,width,height). Args: boxes: (tensor) bounding boxes, sized [N,4]. order: (str) either 'xyxy2xywh' or 'xywh2xyxy'. Returns: (tensor) converted bounding boxes, sized [N,4]. ''' assert order in ['xyxy2xywh','xywh2xyxy'] a = boxes[:,:2] b = boxes[:,2:] if order == 'xyxy2xywh': return torch.cat([(a+b)/2,b-a+1], 1) return torch.cat([a-b/2,a+b/2], 1) def box_iou(box1, box2, order='xyxy'): '''Compute the intersection over union of two set of boxes. The default box order is (xmin, ymin, xmax, ymax). Args: box1: (tensor) bounding boxes, sized [N,4]. box2: (tensor) bounding boxes, sized [M,4]. order: (str) box order, either 'xyxy' or 'xywh'. Return: (tensor) iou, sized [N,M]. Reference: https://github.com/chainer/chainercv/blob/master/chainercv/utils/bbox/bbox_iou.py ''' if order == 'xywh': box1 = change_box_order(box1, 'xywh2xyxy') box2 = change_box_order(box2, 'xywh2xyxy') N = box1.size(0) M = box2.size(0) lt = torch.max(box1[:,None,:2], box2[:,:2]) # [N,M,2] rb = torch.min(box1[:,None,2:], box2[:,2:]) # [N,M,2] #这里的作用就将全部框的位置计算,计算1w多个框与真实框的iou,计算过程就是将全部的一万多个框都与一个真实框计算,坐标点全部记录下来,一次计算全部。 wh = (rb-lt+1).clamp(min=0) # [N,M,2] #计算出高和宽 inter = wh[:,:,0] * wh[:,:,1] # [N,M] #相交区域面积 area1 = (box1[:,2]-box1[:,0]+1) * (box1[:,3]-box1[:,1]+1) # [N,] area2 = (box2[:,2]-box2[:,0]+1) * (box2[:,3]-box2[:,1]+1) # [M,] iou = inter / (area1[:,None] + area2 - inter) return iou 生成训练标签
def encode(self, boxes, labels, input_size): '''Encode target bounding boxes and class labels. We obey the Faster RCNN box coder: tx = (x - anchor_x) / anchor_w ty = (y - anchor_y) / anchor_h tw = log(w / anchor_w) th = log(h / anchor_h) Args: boxes: (tensor) bounding boxes of (xmin,ymin,xmax,ymax), sized [#obj, 4]. labels: (tensor) object class labels, sized [#obj,]. input_size: (int/tuple) model input size of (w,h). Returns: loc_targets: (tensor) encoded bounding boxes, sized [#anchors,4]. cls_targets: (tensor) encoded class labels, sized [#anchors,]. ''' input_size = torch.Tensor([input_size,input_size]) if isinstance(input_size, int) else torch.Tensor(input_size) anchor_boxes = self._get_anchor_boxes(input_size) #产生全部框 boxes = change_box_order(boxes, 'xyxy2xywh') #xyxy转化成xywh形式 ious = box_iou(anchor_boxes, boxes, order='xywh') #候选框和真实框的iou max_ious, max_ids = ious.max(1) boxes = boxes[max_ids] #排序 loc_xy = (boxes[:,:2]-anchor_boxes[:,:2]) / anchor_boxes[:,2:] #论文中这种训练更加准确,所以这种训练产生误差小。 loc_wh = torch.log(boxes[:,2:]/anchor_boxes[:,2:]) loc_targets = torch.cat([loc_xy,loc_wh], 1) #在此合并在一起 cls_targets = 1 + labels[max_ids] #考虑背景 cls_targets[max_ious<0.5] = 0 #将iou小的设置为0,为了后面的过滤,减少参数量 ignore = (max_ious>0.4) & (max_ious<0.5) # ignore ious between [0.4,0.5] cls_targets[ignore] = -1 # for now just mark ignored to -1 #在次过滤 return loc_targets, cls_targets #到这里,就生成方便训练的格式了 测试代码
import torch import numpy as np import random import csv import math def meshgrid(x, y, row_major=True): a = torch.arange(0,x) b = torch.arange(0,y) xx = a.repeat(y).view(-1,1) yy = b.view(-1,1).repeat(1,x).view(-1,1) return torch.cat([xx,yy],1) if row_major else torch.cat([yy,xx],1) class DataEncoder: def __init__(self): self.anchor_areas = [32*32., 64*64., 128*128., 256*256., 512*512.] # p3 -> p7 self.aspect_ratios = [1/2., 1/1., 2/1.] self.scale_ratios = [1., pow(2,1/3.), pow(2,2/3.)] self.anchor_wh = self._get_anchor_wh() def _get_anchor_wh(self): '''Compute anchor width and height for each feature map. Returns: anchor_wh: (tensor) anchor wh, sized [#fm, #anchors_per_cell, 2]. ''' anchor_wh = [] for s in self.anchor_areas: for ar in self.aspect_ratios: # w/h = ar h = math.sqrt(s/ar) w = ar * h for sr in self.scale_ratios: # scale anchor_h = h*sr anchor_w = w*sr anchor_wh.append([anchor_w, anchor_h]) num_fms = len(self.anchor_areas) return torch.Tensor(anchor_wh).view(num_fms, -1, 2) def _get_anchor_boxes(self, input_size): '''Compute anchor boxes for each feature map. Args: input_size: (tensor) model input size of (w,h). Returns: boxes: (list) anchor boxes for each feature map. Each of size [#anchors,4], where #anchors = fmw * fmh * #anchors_per_cell ''' num_fms = len(self.anchor_areas) a = [(38,38),(19,19),(10,10),(5,5),(3,3)] boxes = [] for i in range(1): fm_size = a[i] grid_size = input_size / fm_size[0] fm_w, fm_h = a[i] xy = meshgrid(fm_w, fm_h) + 0.5 # [fm_h*fm_w, 2] xy = (xy * grid_size).view(fm_h, fm_w, 1, 2).expand(fm_h, fm_w, 9, 2) xy = xy.float() wh = anchor_wh[i].view(1, 1, 9, 2).expand(fm_h, fm_w, 9, 2) wh = wh.float() box = torch.cat([xy, wh], dim=3) # [x,y,w,h] boxes.append(box.view(-1, 4)) return torch.cat(boxes, 0) a = DataEncoder() anchor_wh = a.anchor_wh print(anchor_wh) anchor_areas = [32 * 32., 64 * 64., 128 * 128., 256 * 256., 512 * 512.] # p3 -> p7 aspect_ratios = [1 / 2., 1 / 1., 2 / 1.] scale_ratios = [1., pow(2, 1 / 3.), pow(2, 2 / 3.)] input_size = 300.0 a = [(38,38),(19,19),(10,10),(5,5),(3,3)] fm_sizes=[38,19,10,5,3] boxes = [] for i in range(5): fm_size = a[i] grid_size = input_size / fm_size[0] fm_w, fm_h = a[i] xy = meshgrid(fm_w, fm_h) + 0.5 # [fm_h*fm_w, 2] xy = (xy * grid_size).view(fm_h, fm_w, 1, 2).expand(fm_h, fm_w, 9, 2) print(xy) xy = xy.int() wh = anchor_wh[i].view(1, 1, 9, 2).expand(fm_h, fm_w, 9, 2) wh = wh.int() box = torch.cat([xy, wh], dim=3) # [x,y,w,h] boxes.append(box.view(-1, 4)) anchor_boxes=torch.cat(boxes, 0) print(anchor_boxes.shape) # boxes = change_box_order(boxes, 'xyxy2xywh') a = anchor_boxes[:, :2] b = anchor_boxes[:, 2:] nn=torch.cat([a-b/2,a+b/2], 1) boxes=torch.tensor([[167,63,280,202],[100,100,200,200]]) box1 = anchor_boxes.float() box2=boxes.float() anchor_boxes=anchor_boxes.float() # bottom right lt = torch.max(box1[:,None,:2], box2[:,:2]) # [N,M,2] rb = torch.min(box1[:,None,2:], box2[:,2:]) # [N,M,2] wh = (rb - lt + 1).clamp(min=0) # [N,M,2] inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] area1 = (box1[:, 2] - box1[:, 0] + 1) * (box1[:, 3] - box1[:, 1] + 1) # [N,] area2 = (box2[:, 2] - box2[:, 0] + 1) * (box2[:, 3] - box2[:, 1] + 1) # [M,] iou = inter / (area1[:, None] + area2 - inter) max_ious, max_ids = iou.max(1) boxes = boxes[max_ids].float() loc_xy = (boxes[:, :2] - anchor_boxes[:, :2]) / anchor_boxes[:, 2:] loc_wh = torch.log(boxes[:, 2:] / anchor_boxes[:, 2:]).float() loc_targets = torch.cat([loc_xy, loc_wh], 1) labels = torch.tensor([0,3]) cls_targets = 1 + labels[max_ids] cls_targets[max_ious < 0.5] = 0 ignore = (max_ious>0.4) & (max_ious<0.5) cls_targets[ignore] = -1 数据集生成测试
def test(): import torchvision transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.485,0.456,0.406), (0.229,0.224,0.225)) ]) dataset = ListDataset(root='G:detectionimage', list_file='G:detectionimage/test.txt', train=True, transform=transform, input_size=300) dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0, collate_fn=dataset.collate_fn) for images, loc_targets, cls_targets in dataloader: print(images.size()) print(loc_targets.size()) print(cls_targets.size()) # grid = torchvision.utils.make_grid(images, 1) # torchvision.utils.save_image(grid, 'a.jpg') # break test() 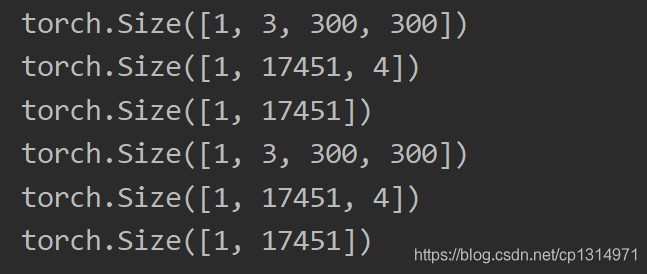
学到这里就掌握目标检测的核心的部分。在去学习其他网络就会清晰很多,代码风格也容易学习,下一章讲解整个的训练过程需要的知识。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











