本次学习的主要的工具集是 IPLDDBFILE 模块,具体如下: Files Datastores IPLD Run() -> //core/commands/add.go 主要完成了三个工作 文件是通过 数据先进行分块,然后把块组合成一棵树,当然也可以称作 DAG,有想无环图本身就是一棵树,这棵树的叶子节点是数据块,默认是 256k 一个块,么一层默认是 174 个节点,树是自上而下填充的,用最终的树根 ID 来代表这个资源; 关于 这个接口有好几个实现,默认使用的是基于 默认的 通过这个方法签名即可了解二者的关系 不难看出这只是 Dag 的构造器,做了一些配置和初始化,并将 代码位置: 这是我们重点关注的方法,签名如下: 接下来我们深入研究这个方法的功能和实现,先看看方法注视 Layout builds a balanced DAG layout. In a balanced DAG of depth 1, leaf nodes The nodes are filled recursively, so the DAG is built from the bottom up. Leaf 分了两个库存储,其中一个是 leveldb 用来存储关系 数据存储并不复杂,如果我们自己设计应该也是这个方案,不知道有没有讲明白,直接写一个 demo 吧:
重点关注
学习入口
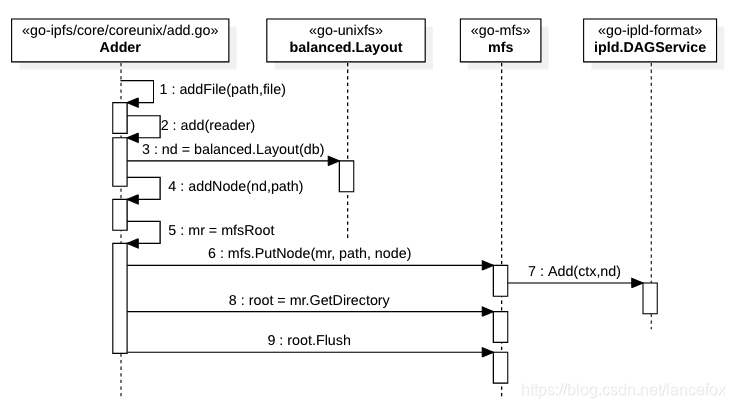
添加文件也就是 ipfs add 的关键调用栈如下:
UnixfsAPI.Add() -> // core/coreapi/unixfs.go
Adder.AddAllAndPin() -> //core/coreunix/add.go
Adder.addFileNode() ->
Adder.addFile() ->
Adder.addNode() ->
Layout 函数拆散并组成一个符合 IPLD 规范的 DAG 对象;mfs 库生成模拟的目录对象来存放于代表文件的 nd 对象的关系;db;DAGService.Add 保存到 db 中的,这个调用发生在 Adder.addNode() 中,文件和目录的关系是单独存储的,通过 root.Flush 函数存储 db,这个调用发生在 Adder.AddAllAndPin 中// 目录入库的代码片段 func (adder *Adder) AddAllAndPin(file files.Node) (ipld.Node, error) { ... // get root mr, err := adder.mfsRoot() ... var root mfs.FSNode rootdir := mr.GetDirectory() root = rootdir err = root.Flush() ... TODO LIST
Layout 的实现原理
chunks
chunker.FromString 返回的 Splitter 接口有如下描述:// A Splitter reads bytes from a Reader and creates "chunks" (byte slices) // that can be used to build DAG nodes. type Splitter interface { Reader() io.Reader NextBytes() ([]byte, error) } size 的实现 sizeSplitterv2//构造函数 func NewSizeSplitter(r io.Reader, size int64) Splitter { return &sizeSplitterv2{ r: r, size: uint32(size), } } // 切分函数 func (ss *sizeSplitterv2) NextBytes() ([]byte, error) { if ss.err != nil { return nil, ss.err } full := pool.Get(int(ss.size)) n, err := io.ReadFull(ss.r, full) switch err { case io.ErrUnexpectedEOF: ss.err = io.EOF small := make([]byte, n) copy(small, full) pool.Put(full) return small, nil case nil: return full, nil default: pool.Put(full) return nil, err } } size 是 256 * 1024 也就是 256k,可以看出我们上传文件的第一步就是将文件切分成 256k 的碎片;DagBuilderParams / DagBuilderHelper
func (dbp *DagBuilderParams) New(spl chunker.Splitter) (*DagBuilderHelper, error) DagBuilderHelper 实例赋给了 db 变量params := ihelper.DagBuilderParams{...} db, err := params.New(chnk) balanced.Layout
github.com/ipfs/go-unixfs// go-unixfs/importer/balanced/builder.go func Layout(db *h.DagBuilderHelper) (ipld.Node, error)
with data are added to a single root until the maximum number of links is
reached. Then, to continue adding more data leaf nodes, a newRoot is created
pointing to the old root (which will now become and intermediary node),
increasing the depth of the DAG to 2. This will increase the maximum number of
data leaf nodes the DAG can have (Maxlinks() ^ depth). The fillNodeRec
function will add more intermediary child nodes to newRoot (which already has
root as child) that in turn will have leaf nodes with data added to them.
After that process is completed (the maximum number of links is reached),
fillNodeRec will return and the loop will be repeated: the newRoot created
will become the old root and a new root will be created again to increase the
depth of the DAG. The process is repeated until there is no more data to add
(i.e. the DagBuilderHelper’s Done() function returns true).
nodes are created first using the chunked file data and its size. The size is
then bubbled up to the parent (internal) node, which aggregates all the sizes of
its children and bubbles that combined size up to its parent, and so on up to
the root. This way, a balanced DAG acts like a B-tree when seeking to a byte
offset in the file the graph represents: each internal node uses the file size
of its children as an index when seeking. `Layout` creates a root and hands it off to be filled: +-------------+ | Root 1 | +-------------+ | ( fillNodeRec fills in the ) ( chunks on the root. ) | +------+------+ | | + - - - - + + - - - - + | Chunk 1 | | Chunk 2 | + - - - - + + - - - - + ↓ When the root is full but there's more data... ↓ +-------------+ | Root 1 | +-------------+ | +------+------+ | | +=========+ +=========+ + - - - - + | Chunk 1 | | Chunk 2 | | Chunk 3 | +=========+ +=========+ + - - - - + ↓ ...Layout's job is to create a new root. ↓ +-------------+ | Root 2 | +-------------+ | +-------------+ - - - - - - - - + | | +-------------+ ( fillNodeRec creates the ) | Node 1 | ( branch that connects ) +-------------+ ( "Root 2" to "Chunk 3." ) | | +------+------+ + - - - - -+ | | | +=========+ +=========+ + - - - - + | Chunk 1 | | Chunk 2 | | Chunk 3 | +=========+ +=========+ + - - - - + IPLD Node 数据的存储方案
也就是 ipld.Node 中的 cid 和 links 的映射,
另一个 filedb 库存储的是 cid 和 rawdata 的映射,
将关系和数据分开存储,这样做的目的是为了重用 rawdata,
关系可以任意组合,但是每个 rawdata 就一份;
举个例子假设 rawdata 的 cid = a ,那么 a 这个 cid 可以出现在任意多个 links 集合中,但是 a 对应的 rawdata 就只有一份;//dag/dag.go package dag import ( "github.com/ipfs/go-blockservice" "github.com/ipfs/go-datastore" "github.com/ipfs/go-datastore/mount" flatfs "github.com/ipfs/go-ds-flatfs" leveldb "github.com/ipfs/go-ds-leveldb" blockstore "github.com/ipfs/go-ipfs-blockstore" exchange "github.com/ipfs/go-ipfs-exchange-interface" ipld "github.com/ipfs/go-ipld-format" "github.com/ipfs/go-merkledag" "os" "path" ) type Adag struct { db datastore.Batching bs blockstore.Blockstore bsrv blockservice.BlockService dsrv ipld.DAGService rem exchange.Interface } func NewAdag(homedir string, rem exchange.Interface) *Adag { a := new(Adag) a.rem = rem a.db = mountdb(homedir) a.bs = blockstore.NewBlockstore(a.db) a.bsrv = blockservice.New(a.bs, a.rem) a.dsrv = merkledag.NewDAGService(a.bsrv) return a } func (a *Adag) DAGService() ipld.DAGService { return a.dsrv } func mountdb(homedir string) datastore.Batching { // db 是一个集合,根据前缀来区分使用 fdb 还是 leveldb // key 的前缀对应的 db 实例是在 .ipfs/config 中进行配置的 Datastore 项 fp := path.Join(homedir, "blocks") os.MkdirAll(fp, 0755) fdb, err := flatfs.CreateOrOpen(fp, flatfs.NextToLast(2), true) if err != nil { panic(err) } ldb, err := leveldb.NewDatastore(path.Join(homedir, "datastore"), nil) if err != nil { panic(err) } mnt := []mount.Mount{ { Prefix: datastore.NewKey("/blocks"), Datastore: fdb, //Datastore: measure.New("flatfs.datastore", fdb), }, { Prefix: datastore.NewKey("/"), Datastore: ldb, //Datastore: measure.New("leveldb.datastore", ldb), }, } return mount.New(mnt) } // dag/dag_test.go package dag import ( "context" "fmt" block "github.com/ipfs/go-block-format" "github.com/ipfs/go-ipfs-chunker" dshelp "github.com/ipfs/go-ipfs-ds-help" ipld "github.com/ipfs/go-ipld-format" "github.com/ipfs/go-unixfs/importer/balanced" h "github.com/ipfs/go-unixfs/importer/helpers" "strings" "testing" ) var homedir = "/tmp/helloipfs" func TestBalanceLayout(t *testing.T) { ds := NewAdag(homedir, nil).DAGService() blocksize := 256 * 1024 t.Log(len([]byte(data)) / blocksize) r := strings.NewReader(data) spl := chunk.NewSizeSplitter(r, int64(blocksize)) dbp := h.DagBuilderParams{ Dagserv: ds, Maxlinks: h.DefaultLinksPerBlock, } dd, err := dbp.New(spl) if err != nil { panic(err) } nd, err := balanced.Layout(dd) if err != nil { panic(err) } ds.Add(context.Background(), nd) size, _ := nd.Size() t.Log(nd.String(), blocksize, size, len(nd.Links())) for i, l := range nd.Links() { n, err := ds.Get(context.Background(), l.Cid) fmt.Println(i, "-->", err, n, len(n.Links())) } }
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

