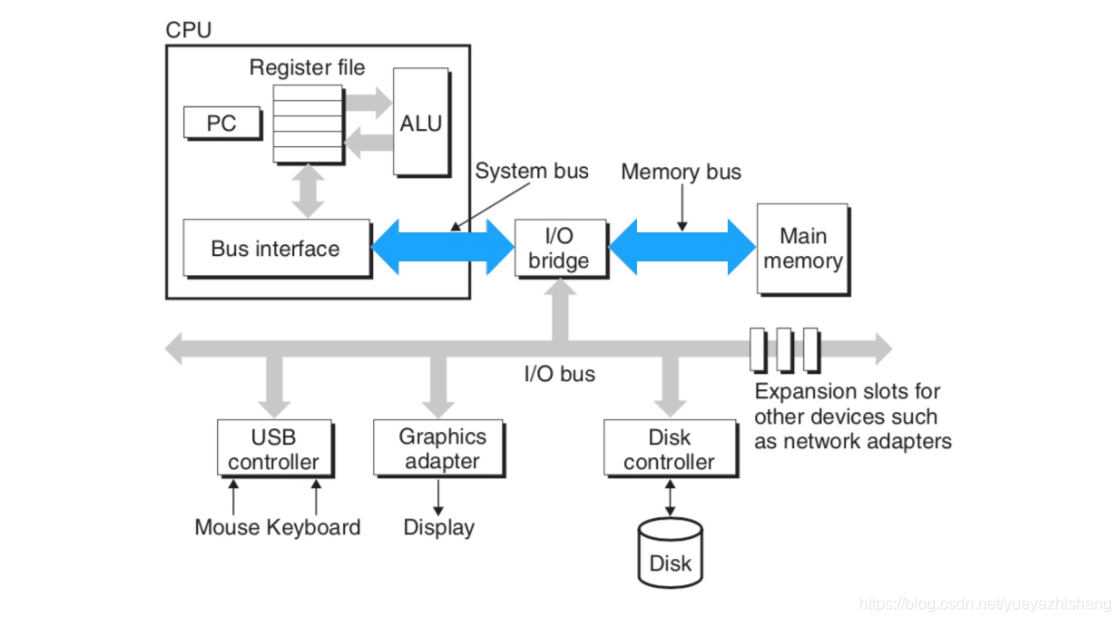
目录 CAS(compare and swap) 比较并替换,比较和替换是线程并发算法时用到的一种技术 CAS是原子操作,保证并发安全,而不是保证并发同步 CAS是CPU的一个指令 CAS是非阻塞的、轻量级的乐观锁 CAS是全称是CompareAndSwap ,是一种在多线程环境下实现同步功能的机制。CAS操作包括三个操作数—内存位置、预期数值和新值。CAS的实现逻辑是将内存位置处的数值与预期数值向比较,若相等则将内存位置处的值替换为新值。若不相等,则不做任何操作【网上很多文章解释为循环,这样是不准确的】。 CPU是通过总线和内存进行的数据传输,在多核心时代下,多个核心通过一条总线和内存以及其他硬件进行通信。如下图: 上图是一个较为简单的计算机结构图,虽然简单,但足以说明问题。在上图中,CPU通过两个蓝色箭头标注的总线与内存进行通信。现在考虑一个问题,CPU的多核心同时对一片内存进程操作,做不加以控制,会导致什么问题? 假设核心1 经32位带宽的总线向内存写入64位的数据,核心1要进行两次写入擦能完成整个操作。若核心1第一次写入32位的数据后,核心2从核心11写入的内存位置读取了64位数据,由于核心1还未完全将64位的数据全部写入到内存中,核心2就开始从内存位置读取数据,那么读取出来的数据必定是换乱的。 不过对于这个问题,实际上不需要担心。自奔腾处理器开始,Intel处理器会保证以原子的方式读写按64位边界对齐的四字(quadword)。 根据上面的说明,Intel处理器可以保证单次访问内存对齐的指令以原子的方式执行。但如果是两次访存指令呢?答案是无法保证的。比如递增指令 inc dword ptr […] ,等价于DEST =DEST +1 ,该指令包含三个操作,读->改->写,涉及两次访问。考虑这样一种情况,在内存指定位置处,存放了一个为1的数值。现在CPU两个核心同时执行该条指令。两个核心交替执行流程如下: 1.核心1从内存指定位置读出数值1,并加载到寄存器中 2.核心2从内存指定位置读取数值1,并加载到寄存器中 3.核心1将寄存器中值递增1 4.核心2将寄存器中值递增1 5.核心1将修改后的值写回内存 6.核心2将修改后的值写回内存 经过上述流程,内存中的最终值是2,而我们期待的是3,这就出现了问题。要处理这个问题就要避免两个或者多个核心同时操作同一片区域内存。如何避免呢?这就要引入本文的主角-lock前缀。 LOCK—Assert LOCK# Signal Prefix 在多处理器环境下,LOCK#信号可以确保处理器独占使用某些共享内存。lock可以被添加在下面的指令前 ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG. 通过在inc指令前添加lock 前缀,即可让该指令具备原子性。多个核心同时执行同一条inc指令时,会以串行的方式进行,也就必满了上面所说的那种情况。 lock 前缀是怎样保证核心独占某片内存区域呢? 在Intel处理器中,与两种方式保证处理器的某一个核心独占某片内存区域。第一种方式是通过锁定总线,让某个核心独占使用总线,但是这样的代价太大,总线被锁定后其他核心就不能访问内存了,可能会导致其他核心短时间内停止工作;第二种方式是锁定缓存,若某处内存数据被缓存在处理器缓存中,处理器会发出的lock#信号不会锁定总线,而是锁定缓存对应的内存区域。其他处理器在这片内存区锁定期间,无法对这片内存区域进行相关操作。相对于锁定总线,锁定缓存的代价明显比较小。 简单而言lock 作用: 如果要访问的内存区域(area of memory)在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性 禁止该指令与之前和之后的读和写指令重排序 把写缓冲区中的所有数据刷新到内存中 有了上面的背景知识,现在我们就可以从容不迫的阅读CAS源码了。以java.util.concurrent.atomic下子类AtomicInteger中的compareAndSet方法进行分析 说明: mpxchg: 即“比较并交换”指令 dword: 全称是 double word,在 x86/x64 体系中,一个word = 2 byte,dword = 4 byte = 32 bit ptr: 全称是 pointer,与前面的 dword 连起来使用,表明访问的内存单元是一个双字单元[edx]: […] 表示一个内存单元,edx 是寄存器,dest 指针值存放在 edx 中。那么 [edx] 表示内存地址为 dest 的内存单元 上面的分析看起来比较多,不过主流程并不复杂。如果不纠结于细节代码,还是比较容易动的。接下来我会分析win平台下Atomic::cmpxchg函数。 上面的代码由 LOCK_IF_MP 预编译标识符和 cmpxchg 函数组成。为了看到更清楚一些,我们将 cmpxchg 函数中的 LOCK_IF_MP 替换为实际内容。如下: 到这里CAS的实现过程就讲完了,CAS的实现离不开处理器的支持。上面这么多代码,其实核心代码就是一条带lock前缀的cmpxchg指令,即lock cmpchg dword ptr [edx] ,ecx 注意:CAS 只是保证了操作的原子性,并不保证变量的可见性,因此变量需要加上 volatile 关键字 在JDK1.5之前,Java语言使用synchronized 关键字来保证同步,这会导致有锁的存在,锁机制存在一下问题: 在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题 一个线程持有锁会导致其它所有需要此锁的线程挂起 如果一个优先级高的线程等待一个优先级低的线程释放锁会导致优先级倒置,引起性能风险 volatile是一个不错的机制,可以保证线程间数据可见性,但是volatile 不能保证原执行。因此对于同步最终还是要回到锁机制上来。 独占锁是一种悲观锁,synchronized就是一种独占锁,会导致其他所有需求当前锁的线程挂起,等待持有锁的线程释放锁。而另一个更加有效的锁就是乐观锁。所谓乐观锁,就是每次不加锁而是假定没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。 因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A 自旋就是cas的一个操作周期,如果一个线程特别倒霉,每次获取的值都被其他线程的修改了,那么它就会一直进行自旋比较,直到成功为止,在这个过程中cpu的开销十分的大,所以要尽量避免。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。 ?? 当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作. 自旋锁 (spinlock) 令牌桶限流器(Eureka 中 RateLimiter::refillToken),保证在多线程情况下,不阻塞线程的填充token 和消费token 由于采用这种 CAS 机制是没有对方法进行加锁的,所以,所有的线程都可以进入 increment() 这个方法,假如进入这个方法的线程太多,就会出现一个问题:每次有线程要执行第三个步骤的时候,i 的值老是被修改了,所以线程又到回到第一步继续重头再来。 而这就会导致一个问题:由于线程太密集了,太多人想要修改 i 的值了,进而大部分人都会修改不成功,白白着在那里循环消耗资源。 我们简单的说下它做了下什么优化,它内部维护了一个数组Cell[]和base,Cell里面维护了value,在出现竞争的时候,JDK会根据算法,选择一个Cell,对其中的value进行操作,如果还是出现竞争,会换一个Cell再次尝试,最终把Cell[]里面的value和base相加,得到最终的结果。 因为其中的代码比较复杂,我就选择几个比较重要的问题,带着问题去看源码: Cell[]是何时被初始化的。 如果没有竞争,只会对base进行操作,这是从哪里看出来的。 初始化Cell[]的规则是什么。 Cell[]扩容的时机是什么。 初始化Cell[]和扩容Cell[]是如何保证线程安全性的。 这个比较简单,就是调用compareAndSet方法,判断是否成功: 如果当前没有竞争,返回true。 如果当前有竞争,有线程会返回false。 再回到第一行,整体解释下这个判断:如果cell[]已经被初始化了,或者有竞争,才会进入到第二行代码。如果没有竞争,也没有初始化,就不会进入到第二行代码。 这就回答了第二个问题:如果没有竞争,只会对base进行操作,是从这里看出来的 第二行代码: ||判断,前者判断cs是否【为NULL】,后者判断(cs的长度-1)是否【大于0】。这两个判断,应该都是判断Cell[]是否初始化的。如果没有初始化,会进入第五行代码。 第三行代码: 如果cell进行了初始化,通过【getProbe() & m】算法得到一个数字,判断cs[数字]是否【为NULL】,并且把cs[数字]赋值给了c,如果【为NULL】,会进入第五行代码。 我们需要简单的看下getProbe() 中做了什么: 第四行代码: 对c进行了CAS操作,看是否成功,并且把返回值赋值给uncontended,如果当前没有竞争,就会成功,如果当前有竞争,就会失败,在外面有一个!(),所以CAS失败了,会进入第五行代码。需要注意的是,这里已经是对Cell元素进行操作了。 第五行代码: 这方法内部非常复杂,我们先看下方法的整体: 有三个if: 1.判断cells是否被初始化了,如果被初始化了,进入这个if。 这里面又包含了6个if,真可怕,但是在这里,我们不用全部关注,因为我们的目标是解决上面提出来的问题。 我们还是先整体看下: 第一个判断:根据算法,拿出cs[]中的一个元素,并且赋值给c,然后判断是否【为NULL】,如果【为NULL】,进入这个if。 这就对第一个问题进行了补充,初始化Cell[]的时候,其中一个元素是NULL,这里对这个为NULL的元素进行了初始化,也就是只有用到了这个元素,才去初始化。 第六个判断:判断cellsBusy是否为0,并且加锁,如果成功,进入这个if,对Cell[]进行扩容。 这就回答了第五个问题的一半:扩容Cell[]的时候,利用CAS加了锁,所以保证线程的安全性。 那么第四个问题呢?首先你要注意,最外面是一个for (;;)死循环,只有break了,才终止循环。 一开始collide为false,在第三个if中,对cell进行CAS操作,如果成功,就break了,所以我们需要假设它是失败的,进入第四个if,第四个if中会判断Cell[]的长度是否大于CPU核心数, 如果小于核心数,会进入第五个判断,这个时候collide为false,会进入这个if,把collide改为true,代表有冲突,然后跑到advanceProbe方法,生成一个新的THREAD_PROBE,再次循环。如果在第三个if中,CAS还是失败,再次判断Cell[]的长度是否大于核心数,如果小于核心数,会进入第五个判断,这个时候collide为true,所以不会进入第五个if中去了,这样就进入了第六个判断,进行扩容。是不是很复杂。 简单的来说,Cell[]扩容的时机是:当Cell[]的长度小于CPU核心数,并且已经两次Cell CAS失败了。 2.前面两个判断很好理解,主要看第三个判断: cas设置CELLSBUSY为1,可以理解为加了个锁,因为马上就要进行初始化了。 初始化Cell[],可以看到长度为2,根据算法,对其中的一个元素进行初始化,也就是此时Cell[]的长度为2,但是里面有一个元素还是NULL,现在只是对其中一个元素进行了初始化,最终把cellsBusy修改成了0,代表现在“不忙了”。 这就回答了 第一个问题:当出现竞争,且Cell[]还没有被初始化的时候,会初始化Cell[]。 第四个问题:初始化的规则是创建长度为2的数组,但是只会初始化其中一个元素,另外一个元素为NULL。 第五个问题的一半:在对Cell[]进行初始化的时候,是利用CAS加了锁,所以可以保证线程安全。 3.如果上面的都失败了,对base进行CAS操作。 如果大家跟着我一起在看源码,会发现一个可能以前从来也没有见过的注解: 这个注解是干什么的?Contended是用来解决伪共享的。 好了,又引出来一个知识盲区,伪共享为何物。 我们知道CPU和内存之间的关系:当CPU需要一个数据,会先去缓存中找,如果缓存中没有,会去内存找,找到了,就把数据复制到缓存中,下次直接去缓存中取出即可。 但是这种说法,并不完善,在缓存中的数据,是以缓存行的形式存储的,什么意思呢?就是一个缓存行可能不止一个数据。假如一个缓存行的大小是64字节,CPU去内存中取数据,会把临近的64字节的数据都取出来,然后复制到缓存。 这对于单线程,是一种优化。试想一下,如果CPU需要A数据,把临近的BCDE数据都从内存中取出来,并且放入缓存了,CPU如果再需要BCDE数据,就可以直接去缓存中取了。 但在多线程下就有劣势了,因为同一缓存行的数据,同时只能被一个线程读取,这就叫伪共享了。 有没有办法可以解决这问题呢?聪明的开发者想到了一个办法:如果缓存行的大小是64字节,我可以加上一些冗余字段来填充到64字节。 比如我只需要一个long类型的字段,现在我再加上6个long类型的字段作为填充,一个long占8字节,现在是7个long类型的字段,也就是56字节,另外对象头也占8个字节,正好64字节,正好够一个缓存行。 但是这种办法不够优雅,所以在Java8中推出了@jdk.internal.vm.annotation.Contended注解,来解决伪共享的问题。但是如果开发者想用这个注解, 需要添加 JVM 参数,具体参数我在这里就不说了,因为我没有亲测过。 参考文档: https://www.cnblogs.com/nullllun/p/9039049.html https://juejin.im/post/5a73cbbff265da4e807783f5 https://juejin.im/post/5a75db20f265da4e826320a9 https://juejin.im/post/5cd4e7996fb9a0323e3ad6ff https://juejin.im/post/5c7a86d2f265da2d8e7101a1
what is CAS
简介
背景介绍

Causes the processor’s LOCK# signal to be asserted during execution of the accompanying instruction (turns the instruction into an atomic instruction). In a multiprocessor environment, the LOCK# signal ensures that the processor has exclusive use of any shared memory while the signal is asserted.
源码分析
AtomicInteger
public class AtomicInteger extends Number implements java.io.Serializable { // setup to use Unsafe.compareAndSwapInt for updates private static final Unsafe unsafe = Unsafe.getUnsafe(); private static final long valueOffset; static { try { // 计算变量 value 在类对象中的偏移 valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } } private volatile int value; public final boolean compareAndSet(int expect, int update) { /* * compareAndSet 实际上只是一个壳子,主要的逻辑封装在 Unsafe 的 * compareAndSwapInt 方法中 */ return unsafe.compareAndSwapInt(this, valueOffset, expect, update); } //该方法功能是Interger类型加1 public final int getAndIncrement() { //主要看这个getAndAddInt方法 return unsafe.getAndAddInt(this, valueOffset, 1); } //var1 是this指针 //var2 是地址偏移量 //var4 是自增的数值,是自增1还是自增N public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { //获取内存值,这是内存值已经是旧的,假设我们称作期望值E var5 = this.getIntVolatile(var1, var2); //compareAndSwapInt方法是重点, //var5是期望值,var5 + var4是要更新的值 //这个操作就是调用CAS的JNI,每个线程将自己内存里的内存值M //与var5期望值E作比较,如果相同将内存值M更新为var5 + var4,否则做自旋操作 } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; } // ...... } public final class Unsafe { // compareAndSwapInt 是 native 类型的方法,继续往下看 public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x); // ...... }unsafe.cpp
// unsafe.cpp /* * 这个看起来好像不像一个函数,不过不用担心,不是重点。UNSAFE_ENTRY 和 UNSAFE_END 都是宏, * 在预编译期间会被替换成真正的代码。下面的 jboolean、jlong 和 jint 等是一些类型定义(typedef): * * jni.h * typedef unsigned char jboolean; * typedef unsigned short jchar; * typedef short jshort; * typedef float jfloat; * typedef double jdouble; * * jni_md.h * typedef int jint; * #ifdef _LP64 // 64-bit * typedef long jlong; * #else * typedef long long jlong; * #endif * typedef signed char jbyte; */ UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) UnsafeWrapper("Unsafe_CompareAndSwapInt"); oop p = JNIHandles::resolve(obj); // 根据偏移量,计算 value 的地址。这里的 offset 就是 AtomaicInteger 中的 valueOffset jint* addr = (jint *) index_oop_from_field_offset_long(p, offset); // 调用 Atomic 中的函数 cmpxchg,该函数声明于 Atomic.hpp 中 return (jint)(Atomic::cmpxchg(x, addr, e)) == e; UNSAFE_END // atomic.cpp unsigned Atomic::cmpxchg(unsigned int exchange_value, volatile unsigned int* dest, unsigned int compare_value) { assert(sizeof(unsigned int) == sizeof(jint), "more work to do"); /* * 根据操作系统类型调用不同平台下的重载函数,这个在预编译期间编译器会决定调用哪个平台下的重载 * 函数。相关的预编译逻辑如下: * * atomic.inline.hpp: * #include "runtime/atomic.hpp" * * // Linux * #ifdef TARGET_OS_ARCH_linux_x86 * # include "atomic_linux_x86.inline.hpp" * #endif * * // 省略部分代码 * * // Windows * #ifdef TARGET_OS_ARCH_windows_x86 * # include "atomic_windows_x86.inline.hpp" * #endif * * // BSD * #ifdef TARGET_OS_ARCH_bsd_x86 * # include "atomic_bsd_x86.inline.hpp" * #endif * * 接下来分析 atomic_windows_x86.inline.hpp 中的 cmpxchg 函数实现 */ return (unsigned int)Atomic::cmpxchg((jint)exchange_value, (volatile jint*)dest, (jint)compare_value); }
// atomic_windows_x86.inline.hpp #define LOCK_IF_MP(mp) __asm cmp mp, 0 __asm je L0 __asm _emit 0xF0 __asm L0: inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) { // alternative for InterlockedCompareExchange // mp是“os::is_MP()”的返回结果,“os::is_MP()”是一个内联函数,用来判断当前系统是否为多处理器 //如果当前系统是多处理器,该函数返回1。否则,返回0。 int mp = os::is_MP(); __asm { mov edx, dest mov ecx, exchange_value mov eax, compare_value // LOCK_IF_MP(mp)会根据mp的值来决定是否为cmpxchg指令添加lock前缀。如果通过mp判断当前系统是多处理器(即mp值为1),则为cmpxchg指令添加lock前缀。否则,不加lock前缀。 // 这是一种优化手段,认为单处理器的环境没有必要添加lock前缀,只有在多核情况下才会添加lock前缀,因为lock会导致性能下降。cmpxchg是汇编指令,作用是比较并交换操作数。 LOCK_IF_MP(mp) cmpxchg dword ptr [edx], ecx } }
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) { // 判断是否是多核 CPU int mp = os::is_MP(); __asm { // 将参数值放入寄存器中 mov edx, dest // 注意: dest 是指针类型,这里是把内存地址存入 edx 寄存器中 mov ecx, exchange_value mov eax, compare_value // LOCK_IF_MP cmp mp, 0 /* * 如果 mp = 0,表明是线程运行在单核 CPU 环境下。此时 je 会跳转到 L0 标记处, * 也就是越过 _emit 0xF0 指令,直接执行 cmpxchg 指令。也就是不在下面的 cmpxchg 指令 * 前加 lock 前缀。 */ je L0 /* * 0xF0 是 lock 前缀的机器码,这里没有使用 lock,而是直接使用了机器码的形式。至于这样做的 * 原因可以参考知乎的一个回答: * https://www.zhihu.com/question/50878124/answer/123099923 */ _emit 0xF0 L0: /* * 比较并交换。简单解释一下下面这条指令,熟悉汇编的朋友可以略过下面的解释: * cmpxchg: 即“比较并交换”指令 * dword: 全称是 double word,在 x86/x64 体系中,一个 * word = 2 byte,dword = 4 byte = 32 bit * ptr: 全称是 pointer,与前面的 dword 连起来使用,表明访问的内存单元是一个双字单元 * [edx]: [...] 表示一个内存单元,edx 是寄存器,dest 指针值存放在 edx 中。 * 那么 [edx] 表示内存地址为 dest 的内存单元 * * 这一条指令的意思就是,将 eax 寄存器中的值(compare_value)与 [edx] 双字内存单元中的值 * 进行对比,如果相同,则将 ecx 寄存器中的值(exchange_value)存入 [edx] 内存单元中。 */ cmpxchg dword ptr [edx], ecx } }解决什么问题?
存在哪些缺陷?
1.ABA问题(链表会丢数据)
2.长时间自旋非常消耗CPU资源
3.只能保证一个共享变量的原子操作
应用场景
public class RateLimiter { private final long rateToMsConversion; private final AtomicInteger consumedTokens = new AtomicInteger(); private final AtomicLong lastRefillTime = new AtomicLong(0); @Deprecated public RateLimiter() { this(TimeUnit.SECONDS); } public RateLimiter(TimeUnit averageRateUnit) { switch (averageRateUnit) { case SECONDS: rateToMsConversion = 1000; break; case MINUTES: rateToMsConversion = 60 * 1000; break; default: throw new IllegalArgumentException("TimeUnit of " + averageRateUnit + " is not supported"); } } //提供给外界获取 token 的方法 public boolean acquire(int burstSize, long averageRate) { return acquire(burstSize, averageRate, System.currentTimeMillis()); } public boolean acquire(int burstSize, long averageRate, long currentTimeMillis) { if (burstSize <= 0 || averageRate <= 0) { // Instead of throwing exception, we just let all the traffic go return true; } //添加token refillToken(burstSize, averageRate, currentTimeMillis); //消费token return consumeToken(burstSize); } private void refillToken(int burstSize, long averageRate, long currentTimeMillis) { long refillTime = lastRefillTime.get(); long timeDelta = currentTimeMillis - refillTime; //根据频率计算需要增加多少 token long newTokens = timeDelta * averageRate / rateToMsConversion; if (newTokens > 0) { long newRefillTime = refillTime == 0 ? currentTimeMillis : refillTime + newTokens * rateToMsConversion / averageRate; // CAS 保证有且仅有一个线程进入填充 if (lastRefillTime.compareAndSet(refillTime, newRefillTime)) { while (true) { int currentLevel = consumedTokens.get(); int adjustedLevel = Math.min(currentLevel, burstSize); // In case burstSize decreased int newLevel = (int) Math.max(0, adjustedLevel - newTokens); // while true 直到更新成功为止 if (consumedTokens.compareAndSet(currentLevel, newLevel)) { return; } } } } } private boolean consumeToken(int burstSize) { while (true) { int currentLevel = consumedTokens.get(); if (currentLevel >= burstSize) { return false; } // while true 直到没有token 或者 获取到为止 if (consumedTokens.compareAndSet(currentLevel, currentLevel + 1)) { return true; } } } public void reset() { consumedTokens.set(0); lastRefillTime.set(0); } } Java 8 incrementAndGet 优化

public void add(long x) { Cell[] cs; long b, v; int m; Cell c; if ((cs = cells) != null || !casBase(b = base, b + x)) {//第一行 boolean uncontended = true; if (cs == null || (m = cs.length - 1) < 0 ||//第二行 (c = cs[getProbe() & m]) == null ||//第三行 !(uncontended = c.cas(v = c.value, v + x)))//第四行 longAccumulate(x, null, uncontended);//第五行 } }
static final int getProbe() { return (int) THREAD_PROBE.get(Thread.currentThread()); } private static final VarHandle THREAD_PROBE;

if (cellsBusy == 0) { // 如果cellsBusy==0,代表现在“不忙”,进入这个if Cell r = new Cell(x); //创建一个Cell if (cellsBusy == 0 && casCellsBusy()) {//再次判断cellsBusy ==0,加锁,这样只有一个线程可以进入这个if //把创建出来Cell元素加入到Cell[] try { Cell[] rs; int m, j; if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) { rs[j] = r; break done; } } finally { cellsBusy = 0;//代表现在“不忙” } continue; // Slot is now non-empty } } collide = false;
try { if (cells == cs) // Expand table unless stale cells = Arrays.copyOf(cs, n << 1); } finally { cellsBusy = 0; } collide = false; continue;
final boolean casCellsBusy() { return CELLSBUSY.compareAndSet(this, 0, 1); }
try { // Initialize table if (cells == cs) { Cell[] rs = new Cell[2]; rs[h & 1] = new Cell(x); cells = rs; break done; } } finally { cellsBusy = 0; }
伪共享
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


