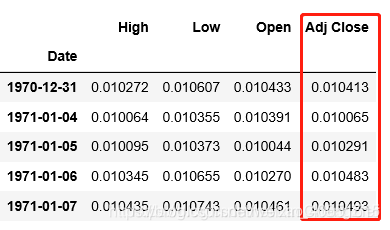
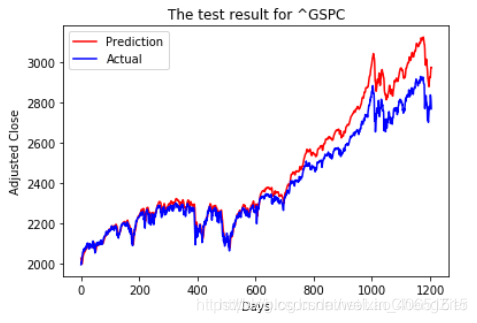
最近有人一直在问我,LSTM到底能不能进行股票预测,那么多人写代码进行预测股票,为何没有具体去应用购买。LSTM方法到底能否进行精准的线性预测。针对LSTM预测问题的解决,我将从股票预测和线性预测问题(例如:PM2.5预测,交通流量预测)的解决去概述目前网上一些代码的思路(这只是个人的一些见解,如有问题请留言指出) 目录 总结目前进行股票预测问题的代码可以发现,针对股票预测一共有两种类型的预测方法(或者说两种不同的预测问题去采用LSTM进行解决)。 一种就是采用开盘价、成交量等相关特征去预测收盘价(也叫多变量时间序列预测),数据和预测结果如图所示: 这是我从网上随意找的数据类型,也是我最初开始学习LSTM股票预测最先接触的方法和数据类型。利用高维度特征进行股票预测当然具有高准确率(从理论上讲),但是该方法仍旧准确误差。目前在解决此类数据集进行收盘价预测的时候,大家往往采用两种方法进行构建输入特征变量和预测标签,为了方便大家理解,我绘制了如下图的形式:(比如用三天的数据去预测第四天的收盘价格) 上述通过动态构建特征的方法就是常说的滑动窗口。即是利用历史数据特征去预测未来的标签输出。当然这种方法只能通过历史数据往前预测一天的输出。构建此类型数据常用的方式代码可以描述为: 另一种就是基于股票的收盘价格进行线性预测未来价格趋势(也叫预测单变量时间序列)。例如,我随意收集了一批数据,其归一化后的样式如图所示,在该图上我画出了如何构建输入特征变量和预测标签。 即是使用一个特征去训练模型,并再次使用该训练好的模型为该未来值做出预测。构造该特征也常采用滑动窗口的方法进行构造,其实现代码如: 上述两种方法进行预测股票只是采用某些历史数据来学习预测未来的某一天或者可以说预测未来 延迟一天的数据。其输入数据在进入LSTM神经网络的结构形式如图: 真正进行预测的输出表示结构应该为这样的: 到此为止,已经描述了我所了解的股票预测两种不同的数据类型所构造的输入形式。从数据输入形式来看,训练的模型确实具有股票价格预测的能力,也就是说训练好的LSTM神经网络确实能够进行线性预测,但是,为何大家在代码实战上预测的精准度如此之高,但是到了现实应用中却不行了呢?我的理解就是股票价格问题包含多种特征因素影响,比如政治因素、市场环境因素等,这些特征很难用向量的形式精准的体现出来,因此导致我们训练的模型不能进行应用。还有一种原因可能是我们基于历史有限特征数据进行训练的模型,会出现过度拟合历史数据的问题,导致应用不准确等各种原因吧。 根据上述对股票预测问题的讨论,我们不难发现LSTM网络模型确实可以进行线性问题的预测。只需要我们采用所谓的滑动窗口方法进行构造输入输出特征即可。 但是,如何进行多点预测,也就是说能够基于给点数据预测未来一段时间的数据值,这就需要我们在输入特征构造和模型输出上做改动。 例如最后的一层的输出可以设置为以下形式:基于多点预测问题(预测未来一段时间数据),我将在具体应用上概述该实现代码。 如果大家对此类预测问题感兴趣,也可以根据我的论述进行复现股票预测。如果我前面的理解有问题或者出现错误,欢迎大家加Q525894654进行批评指正或者讨论交流。如我们所知,股票市场非常动荡,且变化莫测。然而采用深度学习方法进行价格预测肯定具有一定的使用潜力。所以,我们认为算法模型能够(并非总是)正确预测股票价格走势而非具体值(最好是做分类问题)。因此,我猜想基于概率时间序列模型(之前我看过有人提出了概率时间序列模型, probabilistic time-series models)。可能更玄学的方法更能适应股票的预测问题。
股票预测问题:
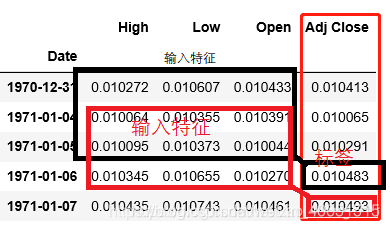
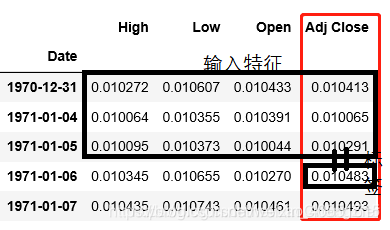

def multivariate_data(dataset, target, start_index, end_index, history_size,target_size, step, single_step=False): data = [] labels = [] start_index = start_index + history_size if end_index is None: end_index = len(dataset) - target_size for i in range(start_index, end_index): indices = range(i-history_size, i, step) data.append(dataset[indices]) if single_step: labels.append(target[i+target_size]) else: labels.append(target[i:i+target_size]) return np.array(data), np.array(labels)
def univariate_data(dataset, start_index, end_index, history_size, target_size): data = [] labels = [] start_index = start_index + history_size if end_index is None: end_index = len(dataset) - target_size for i in range(start_index, end_index): indices = range(i-history_size, i) data.append(np.reshape(dataset[indices], (history_size, 1))) labels.append(dataset[i+target_size]) return np.array(data), np.array(labels)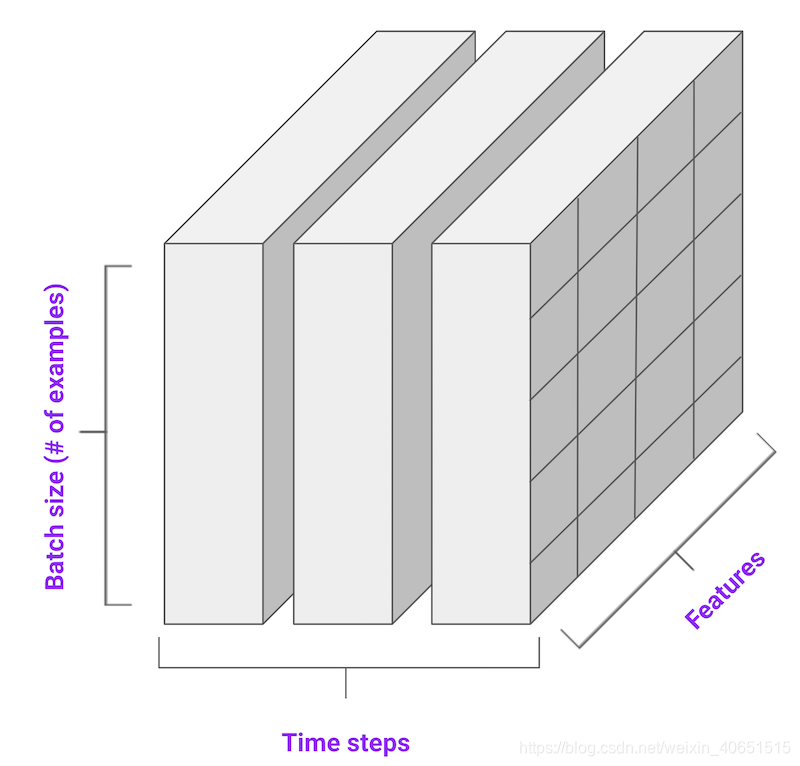
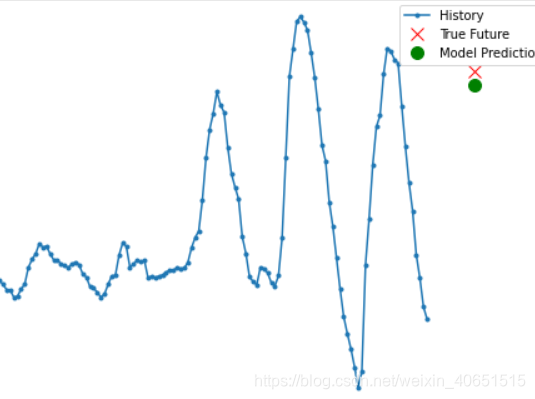
线性预测问题:
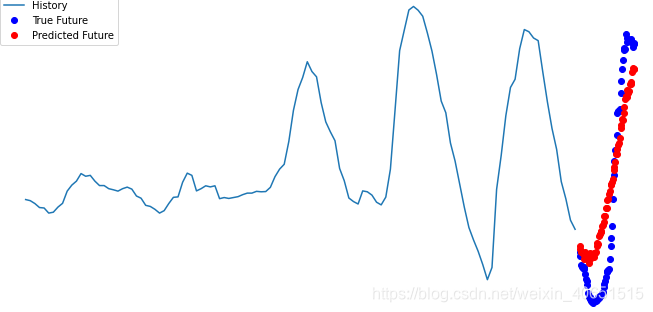
multi_step_model.add(tf.keras.layers.Dense(72))总结:
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

