一,基础环境安装准备 二,安装jdk 3.刷新环境变量 刷新文件 4.修改yarn-env.sh配置文件 5.修改core-site.xml配置文件 6.修改hdfs-site.xml配置文件 7.修改mapred-site.xml配置文件 8.修改yarn-site.xml配置文件 9.格式化hdfs 12.通过浏览器访问hdfs文件系统和yarn 9.启动MySQL 10.登录数据库 12.查看表 13.使用navicate远程连接测试 source /etc/profile cp hive-env.sh.template hive-env.sh 8.测试
1.修改主机名
hostnamectl set-hostname hadoop (Ctrl+D重新连接)
2.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
3.修改hosts文件
vi /etc/hosts192.168.200.2 hadoop
1.新建tgz目录,(将安装包放入创建的tgz目录下)
mkdir /tgz
复制到该目录下:
cp /tgz/jdk-8u45-linux-x64.tar.gz /usr/lib
在该目录下解压jdk:
cd /usr/lib
tar -zxvf jdk-8u45-linux-x64.tar.gz
2.修改环境变量
vi /etc/profileJAVA_HOME=/usr/lib/jdk1.8.0_45 PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar export PATH JAVA_HOME CLASSPATH
source /etc/profile
4.验证是否成功
java
java -version
三,安装Hadoop(安装所需要的安装包都放到tgz目录下)
1.安装Hadoop-2.5.2
cd /tgz
将hadoop复制到该目录下:
cp hadoop-2.5.2.tar.gz /opt/
在该目录下解压
cd /opt/
tar -zxvf hadoop-2.5.2.tar.gz
2.修改配置文件
vi /etc/profileHADOOP_HOME=/opt/hadoop-2.5.2 PATH=$HADOOP_HOME/bin:$PATH export HADOOP_HOME PATH
source /etc/profile
3.修改hadoop-env.sh配置文件
vi /opt/hadoop-2.5.2/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/lib/jdk1.8.0_45
vi /opt/hadoop-2.5.2/etc/hadoop/yarn-env.shexport JAVA_HOME=/usr/lib/jdk1.8.0_45
vi /opt/hadoop-2.5.2/etc/hadoop/core-site.xml<property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.5.2/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property>
vi /opt/hadoop-2.5.2/etc/hadoop/hdfs-site.xml<property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop-2.5.2/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop-2.5.2/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property>
修改名称
mv /opt/hadoop-2.5.2/etc/hadoop/mapred-site.xml.template /opt/hadoop-2.5.2/etc/hadoop/mapred-site.xml
vi /opt/hadoop-2.5.2/etc/hadoop/mapred-site.xml<property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property>
vi /opt/hadoop-2.5.2/etc/hadoop/yarn-site.xml<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
cd /opt/hadoop-2.5.2
bin/hadoop namenode -format
10.启动集群(过程中输入yes 密码000000)
cd /opt/hadoop-2.5.2/sbin/
./start-all.sh
11.jps查看是否正确[root@hadoop sbin]# jps 18264 NameNode 18376 DataNode 18522 SecondaryNameNode 18954 NodeManager 18671 ResourceManager 19055 Jps
公网IP:50070或者IP:8088
https://192.168.200.2:50070
https://192.168.200.2:8088
如图:
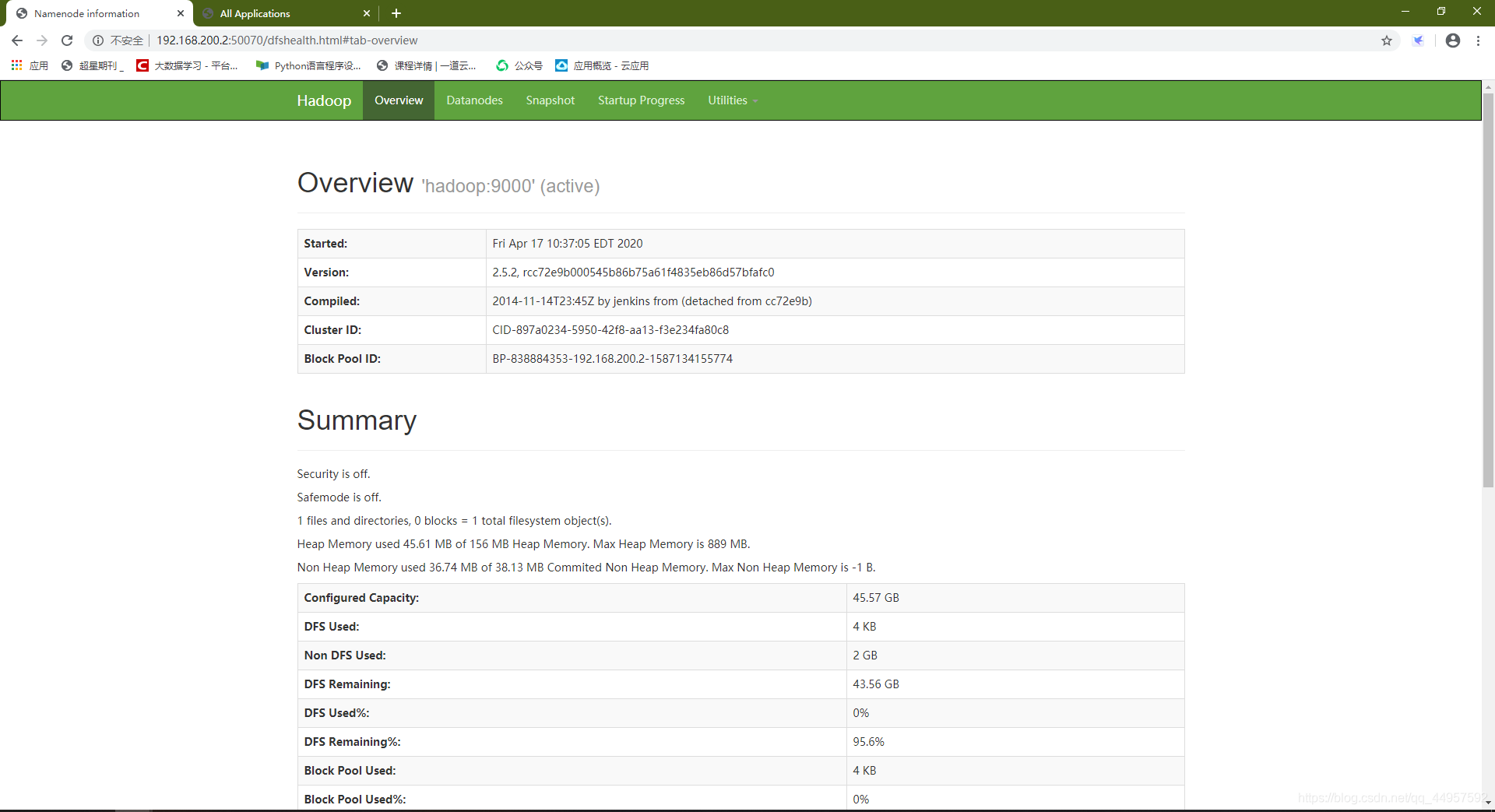
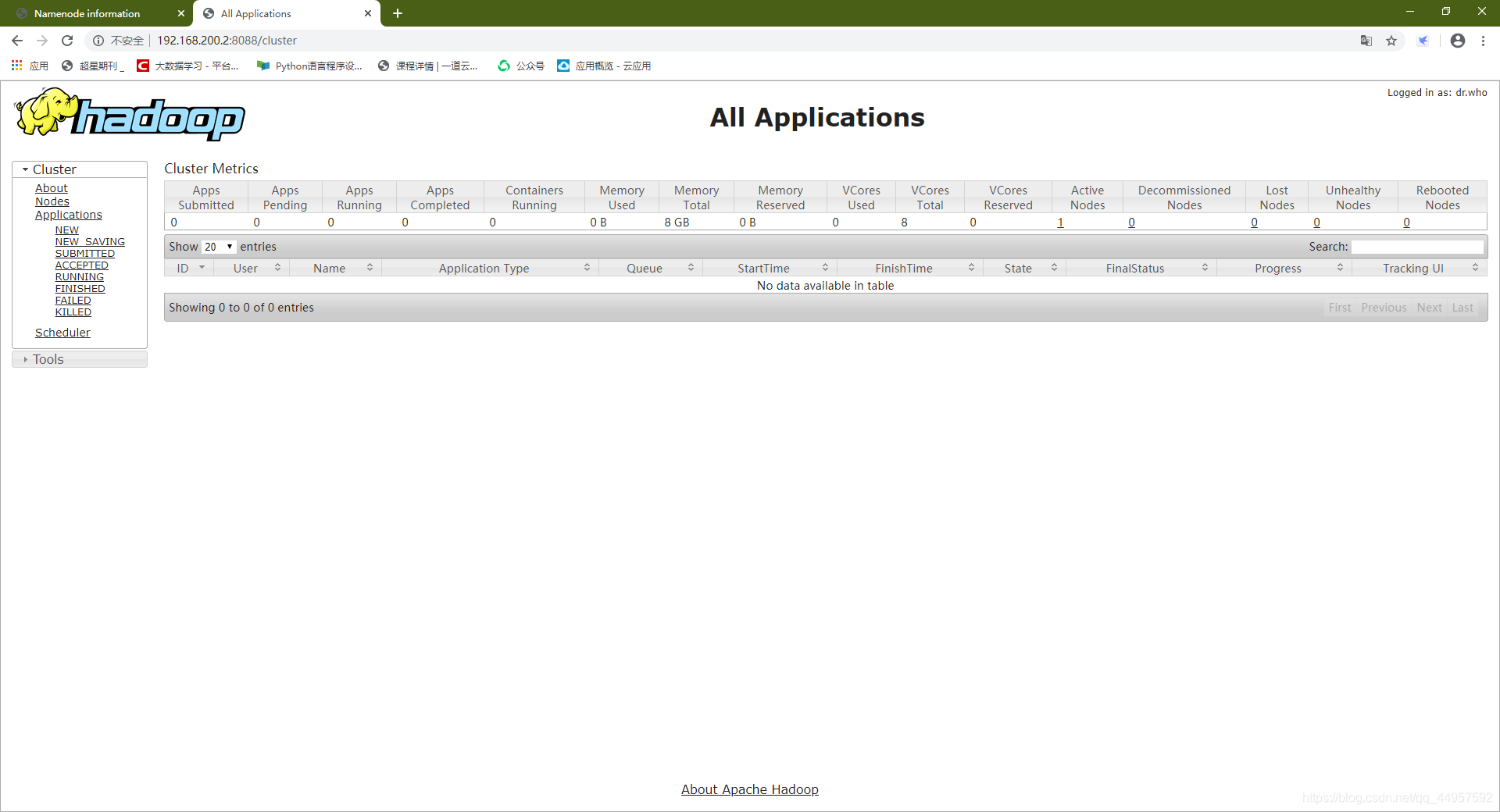
四,安装MySQL
1.将安装包放入tgz目录下,进入目录
cd /tgz/
2.解压缩MySQL到/usr/local目录
tar -zxvf mysql-5.7.29-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
3.进入到usr/local目录并重新命名
cd /usr/local/
mv mysql-5.7.29-linux-glibc2.12-x86_64 /usr/local/mysql
4.创建数据库目录
mkdir /data
mkdir /data/mysql
5.新建mysql用户、组及目录
groupadd mysql
useradd -r -s /sbin/nologin -g mysql mysql -d /usr/local/mysql
6.改变目录属有者
cd /usr/local/mysql/
chown -R mysql .
chgrp -R mysql .
chown -R mysql /data/mysql
7.配置参数(记住临时密码)
bin/mysqld –initialize –user=mysql –basedir=/usr/local/mysql –datadir=/data/mysql
bin/mysql_ssl_rsa_setup –datadir=/data/mysql
8.修改系统配置文件
cd /usr/local/mysql/support-files
cp mysql.server /etc/init.d/mysql
vi /etc/init.d/mysqlbasedir=/usr/local/mysql datadir=/data/mysql
service mysql start如果报错 [root@hadoop support-files]# vi /etc/my.cnf [mysqld] datadir=/data/mysql #socket=/var/lib/mysql/mysql.sock # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in https://fedoraproject.org/wiki/Systemd [mysqld_safe] #log-error=/var/log/mariadb/mariadb.log #pid-file=/var/run/mariadb/mariadb.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
mysql -hlocalhost -uroot -p
如果出现:-bash: mysql: command not found
执行: ln -s /usr/local/mysql/bin/mysql /usr/bin //没有出现就不用执行
输入生成的临时密码。
11.修改密码并赋给用户远程权限Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> set password=password('000000'); Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> grant all privileges on *.* to 'root'@'%' identified by '000000'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql> mysql> use mysql; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select host,user from user; +-----------+---------------+ | host | user | +-----------+---------------+ | % | root | | localhost | mysql.session | | localhost | mysql.sys | | localhost | root | +-----------+---------------+ 4 rows in set (0.00 sec) mysql>
五,安装hive
1.进入安装包目录,解压到/opt目录,将解压包重命名
cd /tgz/
tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /opt/
cd /opt/
mv apache-hive-1.2.2-bin hive
2.配置hive环境变量
vi /etc/profileexport HIVE_HOME=/opt/hive export PATH=$PATH:$HIVE_HOME/bin
3.进入到hive的配置文件目录
cd /opt/hive/conf/
4.修改相关配置文件
vi hive-site.xml (新建文件)<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.200.2:3306/hive?&createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>000000</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration>
vi hive-env.shHADOOP_HOME=/opt/hadoop-2.5.2 export HIVE_CONF_DIR=/opt/hive/conf
cd /tgz
tar -zxvf mysql-connector-java-5.1.46.tar.gz
cp mysql-connector-java-5.1.46/mysql-connector-java-5.1.46.jar /opt/hive/lib/
6.初始化数据库
cd /opt/hadoop-2.5.2/share/hadoop/yarn/lib/
rm -rf jline-0.9.94.jar
cp /opt/hive/lib/jline-2.12.jar /opt/hadoop-2.5.2/share/hadoop/yarn/lib/
schematool -initSchema -dbType mysql
7.启动hive[root@hadoop lib]# hive Logging initialized using configuration in jar:file:/opt/hive/lib/hive-common-1.2.2.jar!/hive-log4j.properties hive> [root@hadoop lib]# hive Logging initialized using configuration in jar:file:/opt/hive/lib/hive-common-1.2.2.jar!/hive-log4j.properties hive> show databases; OK default Time taken: 0.65 seconds, Fetched: 1 row(s) hive> CREATE TABLE IF NOT EXISTS test (id INT,name STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY " " LINES TERMINATED BY "n"; OK Time taken: 0.218 seconds hive> insert into test values(1,'a1'); Query ID = root_20200417120717_e68aeeb4-f762-483a-8b44-11bfe05351db Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1587134257983_0001, Tracking URL = https://hadoop:8088/proxy/application_1587134257983_0001/ Kill Command = /opt/hadoop-2.5.2/bin/hadoop job -kill job_1587134257983_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2020-04-17 12:07:24,219 Stage-1 map = 0%, reduce = 0% 2020-04-17 12:07:29,498 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.14 sec MapReduce Total cumulative CPU time: 2 seconds 140 msec Ended Job = job_1587134257983_0001 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to: hdfs://hadoop:9000/user/hive/warehouse/test/.hive-staging_hive_2020-04-17_12-07-17_995_7617816905121575467-1/-ext-10000 Loading data to table default.test Table default.test stats: [numFiles=1, numRows=1, totalSize=5, rawDataSize=4] MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 2.14 sec HDFS Read: 3554 HDFS Write: 73 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 140 msec OK Time taken: 12.938 seconds hive> select * from test; OK 1 a1 Time taken: 0.078 seconds, Fetched: 1 row(s) hive>
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

