在Java语言规范中对volatile的定义如下:Java编程语言中允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排他锁来确保单独获取这个变量。Java还提提供了volatile关键字,在某些情况下比锁更加方便。 从内存语义的角度来说,volatile的写-读与锁的释放-获取有相同的内存效果。 可见性是指当一条线程修改了某个volatile变量的值,新值对于其它线程来说是可以立即知道的。在 Java 中 volatile、synchronized 和 final 可以实现可见性。普通变量无法做到这点。可见性详细描述为: volatile 变量的内存可见性是基于内存屏障(Memory Barrier)实现。 在 volatile 修饰的共享变量进行写操作的时候会多出 lock 前缀的指令。lock 前缀的指令在多核处理器下会引发两件事情: 通过 hsdis 和 jitwatch 工具可以得到编译后的汇编代码,可以发现其内部 的lock指令,这里就不演示了。 happens-before 规则中有一条是 volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。 根据 happens-before 规则,上面过程会建立 3 类 happens-before 关系。 重排序分为编译器重排序和处理器重排序。为了实现volatile内存语义,JMM会分别限制这两种类型的重排序类型。Java编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。指令重排序时不能把后面的指令重排序到内存屏障之前的位置。 从表我们可以看出: 为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎是不可能的,为此,JMM 采取了保守的策略。volatile 写是在前面和后面分别插入内存屏障,而 volatile 读操作是在后面插入两个内存屏障。 下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图,如图所示: 上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。如下代码: 针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化: 由于volatile对所有线程立即可见,对volatile的写操作会立即反应到其它线程,因此基于volatile的变量的运算在并发下是安全的吗?这是错误的,原因是volatile所谓的其它线程立即知道,是其它线程在使用的时候会读内存然后load到自己工作内存,如果这时候其它线程进行了修改,本线程的volatile变量状态会被置为无效,会重新读取,但如果本线程的变量已经被读入执行栈帧,那么是不会重新读取的;那么两个线程都把本地工作内存内容写入主存的时候就会发生覆盖问题,导致并发错误。 线程从主内存读取最新的 race的值到执行引擎。 有可能某一时刻 2 个线程在步骤 1 读取到的值都是 100,执行完步骤 2 得到的值都是 101,最后刷新了 2 次 101 保存到主内存。 关于更多字节码指令的知识,可以看这篇文章:Java的JVM字节码指令集详解。 案例: 最终i的值可能不是10000 如果深入到内存的基本交互操作(关于内存的基本交互操作,可以看这篇文章:Java内存模型与happens-before原则详解),那么volatile与这些操作具有如下特殊规则: 由于不能保证复合操作的原子性,在不符合以下两条规则的运算场景中,我们仍然要通过加锁来保证原子性: volatile具体的应用总结起来,就是:“一次写入,到处读取”,某一线程负责更新变量,其他线程只读取变量(不更新变量),并根据变量的新值执行相应逻辑。 参考 如果有什么不懂或者需要交流,可以留言。另外希望、、关注,我将不间断更新各种Java学习博客!
volatile关键字可以说是java虚拟机中提供的最轻量级的同步机制,但它并不是锁。因此,在使用时,只有真正明白它的特性、原理才能正确的使用volatile。0 与volatile实现相关的CPU术语
术语
英文单词
术语描述
内存屏障
memory barriers
是一组处理器指令,用于实现对内存操作的顺序限制
缓冲行
cache line
缓存中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期
原子操作
atomic operation
不可中断的一个或一系列操作
缓存行填充
cache line fill
当处理器识别到从内存中读取操作数时可缓存的,处理器读取真哥哥缓存行到适当的缓存(L1,L2,L3或所有)
缓存命中
cache hit
如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存读取
写命中
write hit
当处理器将操作数写回到一个内存缓存的区域时,它首先回检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是内存,这个操作称为写命中
写缺失
write miss the cache
一个有效的缓存行被写入到不存在的内存区域
1 volatile 的特性
2 volatile 的内存语义
volatile 写的内存语义
当写一个 volatile 变量时,JMM 会把该线程对应的本地内存中的共享变量刷新到主内存。
volatile 读的内存语义
当读一个 volatile 变量时,JMM 会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
总结:
线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息。
线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。3 可见性的实现
3 有序性的实现
3.1 volatile变量的happens-before 关系
//假设线程A执行writer方法,线程B执行reader方法 class VolatileExample { int a = 0; volatile boolean flag = false; public void writer() { a = 1; // 1 线程A修改共享变量 flag = true; // 2 线程A写volatile变量 } public void reader() { if (flag) { // 3 线程B读同一个volatile变量 int i = a; // 4 线程B读共享变量 …… } } }
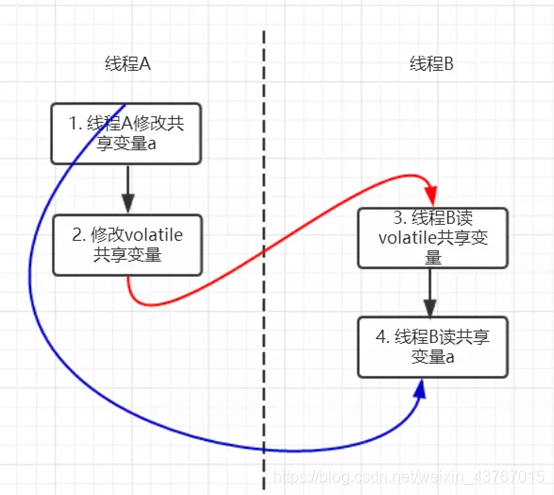
因为以上规则,当线程 A 将 volatile 变量 flag 更改为 true 后,线程 B 能够迅速感知。3.2 volatile 禁止重排序
3.2.1 volatile 重排序规则表
JMM 针对编译器制定 volatile 重排序规则表:
第一个操作
第二个操作:普通读写
第二个操作:volatile读
第二个操作:volatile写
普通读写
可以重排
可以重排
不可以重排
volatile读
不可以重排
不可以重排
不可以重排
volatile写
可以重排
不可以重排
不可以重排
3.2.2 编译器的实现
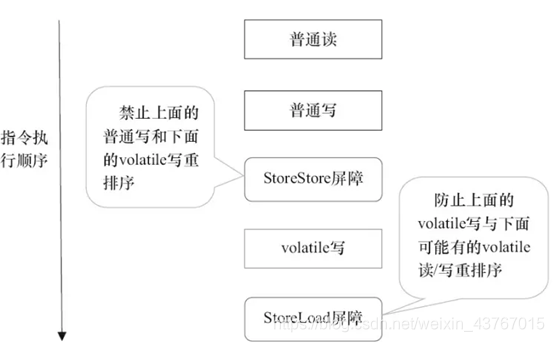
图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是,volatile写后面的StoreLoad屏障。**此屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。**因为编译器常常无法准确判断在一个volatile写的后面是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile读的前面插入一个StoreLoad屏障。
从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图,如图所示:
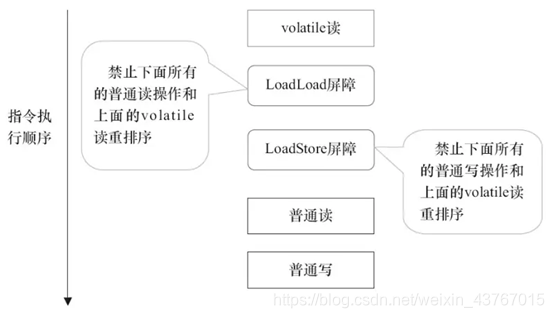
图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。3.2.3 屏障优化
class VolatileBarrierExample { int a; volatile int v1 = 1; volatile int v2 = 2; void readAndWrite() { int i = v1; // 第一个volatile读 int j = v2; // 第二个volatile读 a = i + j; // 普通写 v1 = i + 1; // 第一个volatile写 v2 = j * 2; // 第二个 volatile写 } … // 其他方法 }

注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障。4 不能保证复合操作的原子性
虽然volatile其要求对变量的(read、load、use)、(assign、store、write)必须是连续出现,即以组的形式出现,但是这两组操作还是分开的。比如说,两个线程同时完成了第一组操作(read、load、use),但是还没进行第二组操作(assign、store、write),此时是没错的,然后两个线程开始第二组操作,这样最终其中一个线程的操作会被覆盖掉,导致数据的不准确。
案例: 定义static volatile int race = 0,2 个线程同时执行 race ++ 操作,每个线程都执行 500 次,最终结果可能会小于 1000。原因是每个线程执行 race ++ 需要以下 3 个步骤:
执行引擎把 race值加 1
线程工作内存把 race值保存到主内存
因为 happens-before 中的 volatile 变量规则只规定了 对一个变量的写操作 happens-before 后面对这个变量的读操作。所以中间的过程(从 Load 到 Store)是不安全的。中间如果其他的 CPU 修改了值将会丢失。例如执行到步骤 2 时,线程B 对变量 i 进行了修改,但是线程 A 是不会感知的。只有线程 A 在下一次读取时,由于可见性才会感知到被线程 B 修改后的新值。
使用javap -v反编译race++来查看更详细的步骤:

上面的字节码指令虽然很底层,但是并不意味着这条指令就是原子性的,字节码指令在转换为汇编语言之后会被分解为更多的本地机器码,那样分析会更加精确,但此处用字节码分析就够了。
上面的指令中,将“race++”分解成了4条指令:
从上面的字节码分析可知,由于volatile变量只能保证可见性、有序性,在不符合以下两条规则的运算场景中,仍然需要通过加锁保证原子性:
public class VolatileTest1 { public static volatile int i = 0; public static class VO implements Runnable { @Override public void run() { for (int j = 0; j < 1000; j++) { i++; } } } public static void main(String[] args) throws InterruptedException { for (int i1 = 0; i1 < 10; i1++) { Thread thread = new Thread(new VO()); thread.start(); } //保证前面的10条线程都执行完 while (Thread.activeCount() > 2) { Thread.yield(); } System.out.println(i); } } 5 volatile与内存基本交互操作
假定 T 表示一个线程,V 和 W 分别表示两个 volatile 型变量,那么在进行 read、load、use、assign、store 和 write 操作时需要满足如下规则:
6 volatile的使用建议
例如:
《Java虚拟机规范》
《Java并发编程之美》
《Java并发编程的艺术》
《实战Java高并发程序设计》
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


