计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了! Batch Normalization 训练网络的时候要对数据进行归一化 以上做法只考虑了网络的输入,没有考虑网络中每一层的输入 对每一层分布归一化的好处: 在上述的描述中,我一直用的是“类似的分布”而不是“相同的分布”? 最后,算法流程如下图: BN是针对每一个神经元的 测试如何使用? 公式的变化? 讲BN通常结合sigmoid函数,是因为BN很适合sigmoid函数 完
神经网络中的一个层,被称为BN层原理
原因:使输入数据的分布是相同的
分布不相同的话,举个例子:
同样的图像内容,网络对暗一点的和亮一点的图像的理解也就不同了
BN层就是对每一层的分布进行调整
如果只做归一化,数据的分布是相同的,那么数据会大概率落在下图所示的sigmoid函数的不严格的线性区间中(红色虚线)。
神经网络是靠激活函数的非线性能力实现强大的表达能力。
如果激活函数类似于线性的,网络会变成线性的,那么神经网络的深度将失去意义。
原因是,线性的表达我们用一层就足够了呀。
所以我们不能让数据大概率落在红色虚线部分。
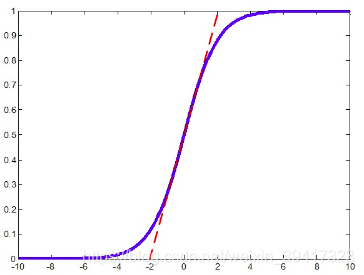
所以,我们对归一化的数据进行一个简单的变换。
使其分布发生微小的变化,不完全落在红色虚线中。
有人觉得,跌跌撞撞又回到了原点?
可以认为,这个变换是对归一化过于粗暴的弥补。

细节
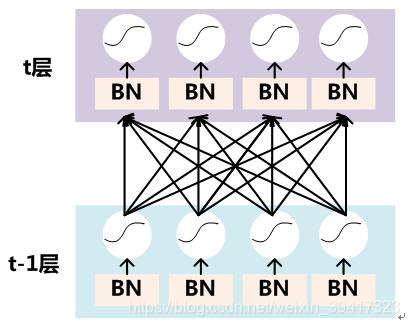
我们看第t层的最左侧神经元
它接收了4个输入,x1,x2,x3,x4
BN是针对这4个数据操作的,和其余神经元接收的数据没有关系
测试的时候常常使用一个样本
一个样本无法计算均值、方差,就不用谈BN了
解决方法:
每个batch,记录均值和方差
所有数据训练完成后,利用记录的均值和方差计算数据总体的均值和方差
新的均值和方差在测试过程中保持不变
公式如下:
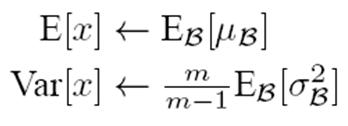
改变分布的变换参数是训练中学习到的,就不用再考虑了
看别的博客可能会看到这个公式
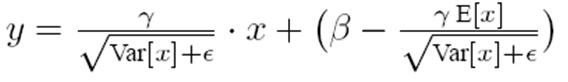
和算法流程中的最终公式不同,其实就是把归一化的过程融合进来了
将算法中的公式3和公式4联立即可拓展
当然也适用于别的激活函数,具体情况具体分析
比如,上述的这一点对于relu激活函数就不适用了
缓解梯度消失。经过BN层的数据会大概率落在sigmoid激活函数导数较大的区域,缓解了梯度消失。
但是分布相似的好处依然适用
看完这篇博客应该可以根据具体的激活函数具体分析了吧?
欢迎讨论 欢迎吐槽
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

