【1】Spark SQL的DataFrame接口支持多种数据源的操作 【3】当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称定json, parquet, jdbc, orc, libsvm, csv, text来指定数据的格式 除此之外,可以直接运行SQL在文件上 【4】文件保存选项 【5】Parquet文件 【7】Schema合并 配置 2)后台启动 Hive MetaStore服务 3)SparkSQL整合Hive MetaStore 注:使用IDEA本地测试直接把以上配置文件放在resources目录即可 使用IDEA操作hive时添加配置

【一】SparkSQL数据源
一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表,把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询
【2】 Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式 val df = sqlContext.read.load("examples/src/main/resources/users.parquet") df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
可以通过SparkSession提供的read.load方法用于通用加载数据,使用write和save保存数据 val df = spark.read.format("json").load("examples/src/main/resources/people.json") df.write.format("json").save("hdfs://node01:8020/namesAndAges.json") val df= spark.sql("SELECT * FROM parquet.`hdfs://node01:8020/namesAndAges.json`") df.show()
①.SaveMode.ErrorIfExists(default)
“error”(default) 如果文件存在,则报错
②.SaveMode.Append
“append” 追加
③.SaveMode.Overwrite
“overwrite” 覆写
④.SaveMode.Ignore
“ignore” 数据存在,则忽略
Parquet是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录
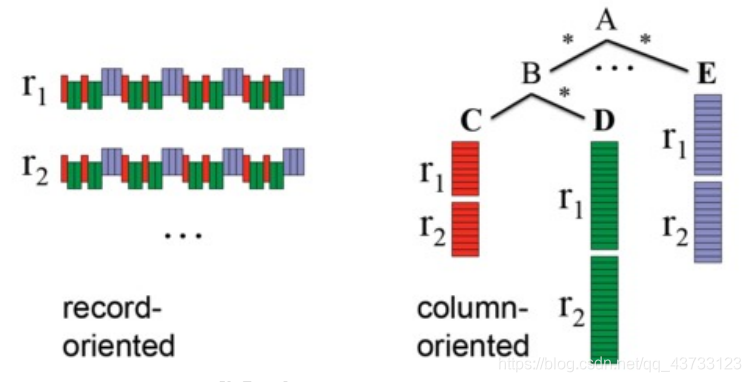
【6】Parquet读写
Parquet格式经常在Hadoop生态圈中被使用,它也支持Spark SQL的全部数据类型。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法import spark.implicits._ val peopleDF = spark.read.json("examples/src/main/resources/people.json") peopleDF.write.parquet("hdfs://node01:8020/people.parquet") val parquetFileDF = spark.read.parquet("hdfs://node01:8020/people.parquet") parquetFileDF.createOrReplaceTempView("parquetFile") val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19") namesDF.map(attributes => "Name: " + attributes(0)).show()
①.当数据源为Parquet文件时,将数据源选项mergeSchema设置为true
②.设置全局SQL选项spark.sql.parquet.mergeSchema为trueimport spark.implicits._ val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double") df1.write.parquet("hdfs://node01:8020/data/test_table/key=1") val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple") df2.write.parquet("hdfs://node01:8020/data/test_table/key=2") val df3 = spark.read.option("mergeSchema","true") .parquet("hdfs://master01:9000/data/test_table") df3.printSchema()
Spark SQL 能够自动推测 JSON数据集的结构,并将它加载为一个DataSet[Row]. 可以通过SparkSession.read.json()去加载一个 DataSet[String]或者一个JSON 文件.注意,这个JSON文件不是一个传统的JSON文件,每一行都得是一个JSON串
示例如下:👇{"name":"Michael"} {"name":"Andy", "age":30} {"name":"Justin", "age":19}
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中注意,需要将相关的数据库驱动放到spark的类路径下
mysql-connector-java-5.1.38.jar【读取数据方式1】 val jdbcDF = spark.read.format("jdbc") .option("url","jdbc:mysql://node01:3306/rdd") .option("dbtable","user") .option("user","root") .option("password","root") .load() jdbcDF.show() --------------------------------------------------------------------------------------------- 【读取数据方式2】 val connectionProperties = new java.util.Properties() connectionProperties.put("user","root") connectionProperties.put("password","root") val jdbcDF2 = spark.read.jdbc("jdbc:mysql://node01:3306/rdd","user",connectionProperties) jdbcDF2.show() --------------------------------------------------------------------------------------------- 【输出数据方式2】 df.write.format("jdbc").mode("overwrite") .option("url","jdbc:mysql://node01:3306/rdd") .option("dbtable","user") .option("user","root") .option("password","root") .save() --------------------------------------------------------------------------------------------- 【输出数据方式2】 df.write.mode("overwrite").jdbc("jdbc:mysql://node01:3306/rdd","user",connectionProperties)
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互。
在Spark目录下执行如下命令启动Spark SQL CLI:
./bin/spark-sql
配置Hive需要替换 conf/ 下的 hive-site.xml【9】Spark on Hive
1)vim hive-site.xml添加如下配置👇 <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://hive所在节点主机名:9083</value> </property> hiveserver2 & 没有配置hive.metastore.uris,开启hiveserver2则会自动在本地启动一个metastore 配置了hive.metastore.uris,则直接开启metastore就可以让SparkSQL连接到了 (重点就是开启metastore,让spark操作元数据) 或 nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log &
Spark 有一个内置的 Hive,元数据使用 Derby 嵌入式数据库保存数据,在Spark根目录下叫做metastore_db,数据存放在Spark根目录下的spark-warehouse目录中
SparkSQL 整合 Hive 的 MetaStore 主要思路就是要通过配置能够访问它, 并且能够使用 HDFS 保存 wareHouse,所以可以直接拷贝 Hadoop 和 Hive 的配置文件到 Spark 的配置目录如下文件添加到Spark的conf目录 hive-site.xml 元数据仓库的位置等信息 core-site.xml 安全相关的配置 hdfs-site.xml HDFS 相关的配置 .enableHiveSupport()//开启hive语法的支持代码示例:
val spark = SparkSession .builder() .appName("Spark Hive Example") .config(new SparkConf()) .enableHiveSupport() .getOrCreate() spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)") spark.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src") spark.sql("SELECT * FROM src").show() spark.sql("SELECT COUNT(*) FROM src").show() spark.close() 【10】SparkSQL输出到MySQL
def main(args: Array[String]): Unit = { /** * 插入数据到MySQL */ val spark: SparkSession = SparkSession.builder() .master("local[*]") .appName("mysql") .config(new SparkConf()) .getOrCreate() val df: DataFrame = spark.read.json("user.json") var prop = new Properties() prop.setProperty("user","root") prop.setProperty("password","root") df.write.mode("overwrite").jdbc("jdbc:mysql://localhost:3306/tmp","user",prop) spark.stop() } 【11】SparkSQL读取MySQL数据
def main(args: Array[String]): Unit = { /** * 从MySQL读取数据 */ val spark: SparkSession = SparkSession.builder() .master("local[*]") .appName("mysql") .config(new SparkConf()) .getOrCreate() var prop = new Properties() prop.setProperty("user","root") prop.setProperty("password","root") val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/tmp","user",prop) df.show() spark.stop() }

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

