之前文章《ElasticSearch系列(一)linux环境ElasticSearch+Kibana(6.8.2)下载安装启动步骤》,我们安装了elasticsearch,并实现了间的增删改查。但是存到ES中的数据,无法直观的看到。本文介绍一款插件head,用来可视化ES中的数据。 下载连接:https://github.com/mobz/elasticsearch-head 我们直接在linux中下载: 后边这个地址就是点击下载时弹出的下载地址。(可能需要先使用命令:yum -y instal wget,安装wget) 下载后,解压就可以了,放置目录根据个人喜好。 head插件是使用js开发的前端项目,依赖nodejs,要使用此插件,必须先安装nodejs。 在linux环境中,使用如下命令检查nodejs和npm是否安装: 如果显示了两者版本号,表示已经安装,否则为没有安装。 在window上是直接下载exe文件,然后双击安装就可以了,但是在linux上不太一样,下面开始下载: 打开nodejs下载页面:https://nodejs.org/zh-cn/download/,选择合适的linux二进制文件, 下载完成后,直接使用如下命令解压: 参数 -C /root 的意思是把解压包copy到root目录下,这个位置根据个人喜好随便。 配置环境变量: 然后node -v会显示版本号,表示node安装成功; 可能会有异常情况: 这是由于linux gcc版本太低导致,需要升级,比如我是centerOs6.5,安装nodejs v12就会有问题,需要升级gcc: gcc下载比较慢,可以直接使用稍微低版本的nodejs解决,比如v10版本。 grunt是基于Node.js的项目构建工具,可以进行打包压缩、测试、执行等等的工作,head插件就是通过grunt启动。 进入head根目录,运行如下命令安装: 在head的配置文件Gruntfile.js中添加host正则匹配项: 进入es安装目录,修改elasticsearch.yml的配置: 重启ES; 方式1 方式2 选择【符合查询】页签,这个相当于使用ES提供Restfule接口进行操作: 比如想删除my-index2索引。 方式1 然后刷新页面,【数据浏览】中已经存在这条数据: ES对于修改的逻辑,是先删除然后添加; 直接指定id,进行查询即可: queryString方式会先对查询关键词进行分词: 本文就先到这里吧。
文章目录
一、下载head插件
wget -c https://codeload.github.com/mobz/elasticsearch-head/zip/master 二、安装nodejs
1.检查nodejs是否已经安装
node -v
npm -v2.下载nodejs
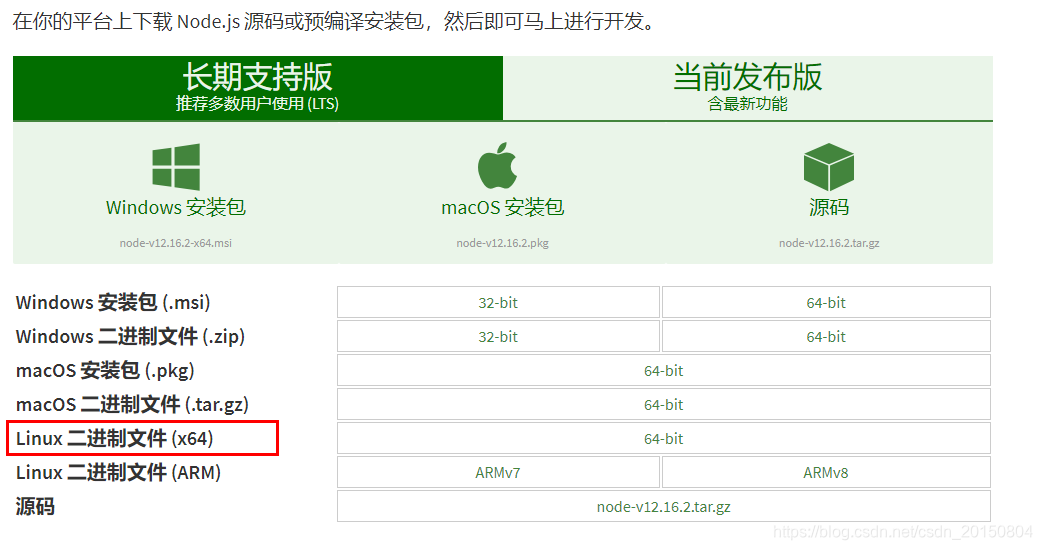
上面是在windows中进官网下载,但我们直接在linux中使用命令下载:wget -c https://nodejs.org/dist/v12.16.2/node-v12.16.2-linux-x64.tar.xz 3.安装nodejs
tar -xvf node-v12.16.2-linux-x64.tar.xz -C /root vim /etc/profile ,添加如下内容, export NODE_HOME=/root/node-v12.16.2-linux-x64 export PATH=$PATH:$NODE_HOME/bin export NODE_PATH=$NODE_HOME/lib/node_modules ## 让配置生效 source /etc/profile
node: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.14’ not found (required by node)##下载gcc wget https://gcc.parentingamerica.com/releases/gcc-6.1.0/gcc-6.1.0.tar.bz2 三、配置head
1.安装grunt
npm install -g grunt-cli ##检测是否安装成功,如果执行命令后出现版本号就表明成功 grunt -version 2.修改head配置文件Gruntfile.js
connect: { server: { options: { port: 9100, base: '.', keepalive: true, host: '*' 添加这一项 } } } 3.设置es允许跨域访问:
#设置外网可以访问(这一条设置为真实的ip也行) network.host: 0.0.0.0 # 监听端口(默认) http.port: 9200 # 增加参数,使head插件可以访问es http.cors.enabled: true http.cors.allow-origin: "*" 4.然后在head目录下执行:
##安装npm 服务 npm install ##启动插件 grunt server 或者npm run start 5.访问https://ip:9100 ,进入显示如下:
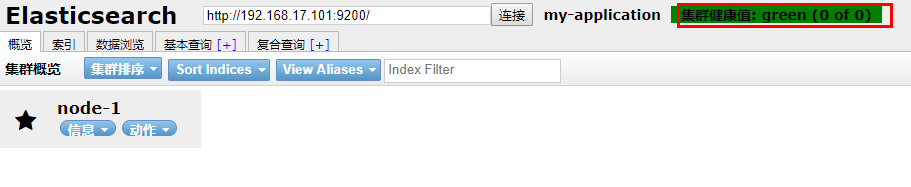
然后输入ES的地址,点击连接。显示绿色即可:
四、head简单使用
1.创建索引
选择索引标签,新建索引:
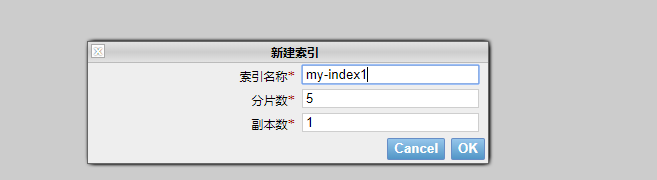
其中,分片是ES内部存储方式,默认为5个分片;副本是每个分片的备份,默认为1;
确定后,概览中如下显示,绿色为主分片,灰色为副本,由于我目前搭建的不是集群,只有一个节点,而副本不能和主分片在同一个节点上,所以副本是无效的。右上角的黄色健康提示,说只有一半的有效的。
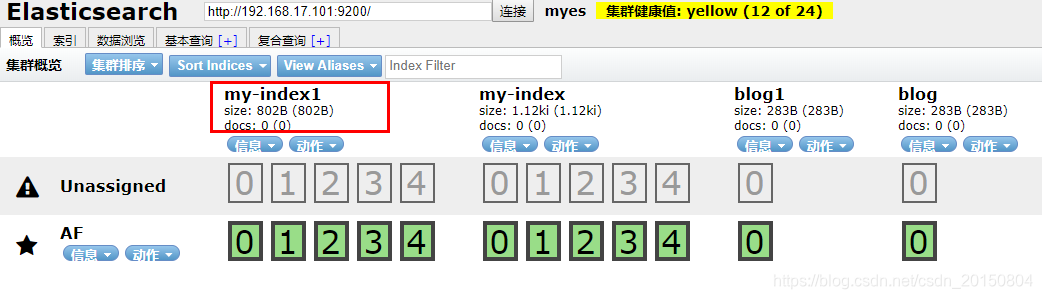
通过方式1创建的索引,只是指定了索引名字,具体的mapping信息没有指定(相当于没有表和字段类型啥的信息),我们可以动过【索引】按钮,查看索引信息,发现mappings是空的:

可以通过下面这种方式创建带有mappings信息的索引。

提交请求后,查看概览:
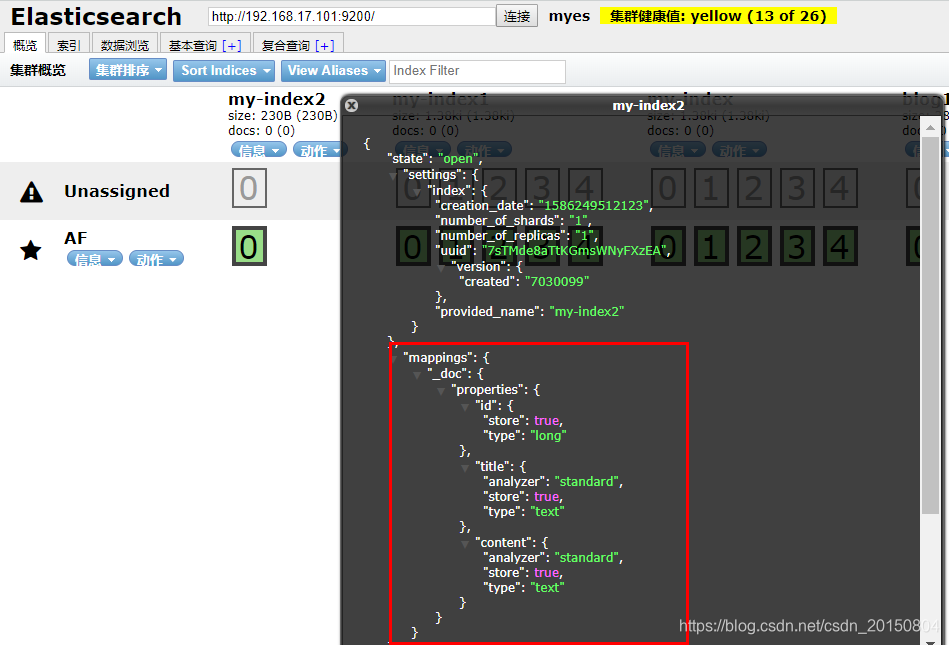
注意:需要注意的是,在我们指定mappings信息的时候,ES7以上版本,不需要指定type,否则会报错,因为es7以上版本默认只有一个type,那就是_doc ;通过上面索引信息也能看出来。2.删除索引
使用head提供的按钮,如下:
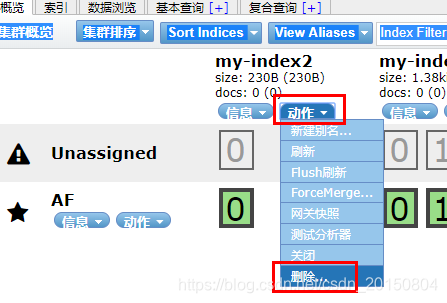
方式2
使用复合查询,也就是使用REST接口进行删除,直接写上索引名字,然后请求类型是DELETE即可:

提交请求之后,刷新页面,会发现索引已经被删除。3.添加文档
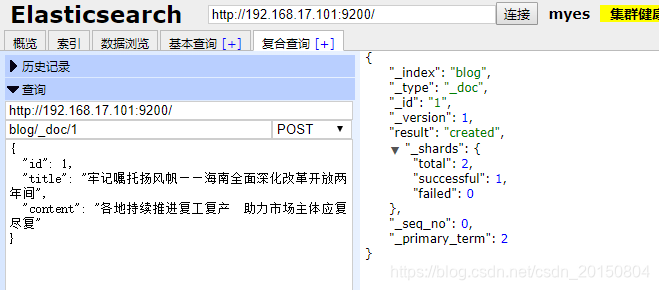
注意:

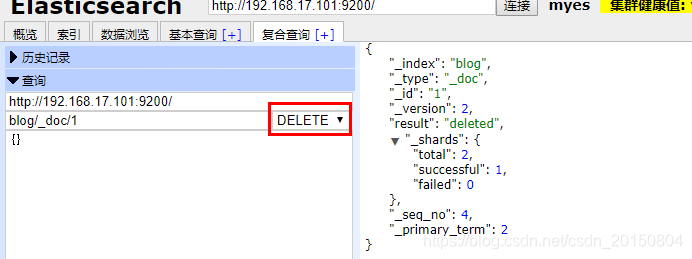
4.删除文档
5.修改文档
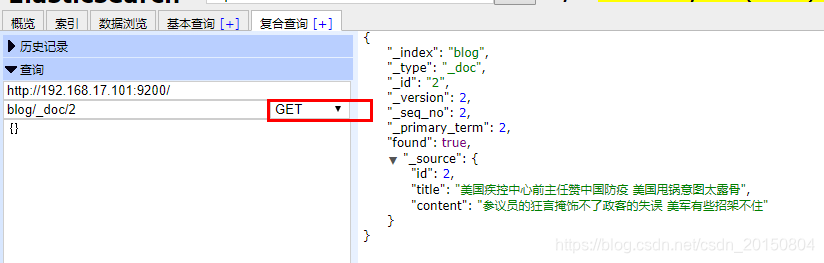
所以修改,就是直接制动相同的id,然后更新内容即可;等同于添加操作。6.根据id查询文档
7.根据关键词进行查询

注意:
8.使用queryString查询

”美国人“,这个词本来不存在,但是es会将这个词分为”美”“国”“人”3个词分别查询,这样就嫩查到结果了。
由于目前es搭建的是单节点,所以只有1个node,后文中,我们会讲述集群搭建。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


