首先我们知道,创建RDD的方式主要有以下三种: 大致有以下几种 所以,在我们编写程序的时候,如果不做任何修改,默认的并行度,即分区数就根据上述条件进行创建 既然有默认的,那我们也是可以自行根据需求进行修改的,比如我们在使用 我们通过源码可以发现其实makrRDD有两个重载方法,如下👇 现在说一下 获取切片的源码如下👇 两者的区别就在下图,集群的后端调度器实现类是
(博主根据自己的理解进行阐述的,如果有什么错误还请指出或私信)
我又来啦…今天我来整理一下Spark并行度的概念
makeRDD、parallelize、textFile【1】我们首先讲一下在
local 模式下



首先呢,不同的 local,默认并行度是不一样的
local:默认使用1个core模拟运行所有任务,所以并行度就是1
local[n]:默认使用n个core模拟运行所有任务,所以并行度就是n
local[*]:默认使用当前环境所有core模拟运行所有任务,所以并行度就是当前环境的所有core数量makeRDD、parallelize、textFile等方法的时候,可以自行设定并行度,不过textFile这个方法有点特殊,所以我们先说一下makeRDD、parallelizemakeRDD、parallelize

我们主要阐述一下实质是调用parallelize的makeRDD方法
我们可以发现该makeRDD方法的第二个参数便是并行度设置,我们可以传入第二个参数进行自定义设置,设置的多少并行度就会变成多少,如果不传入该参数,该参数也有默认值,如下👇
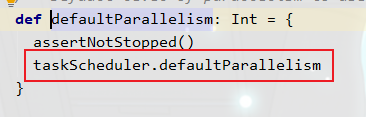




从这里我们可以发现,如果我们没有设置并行度,默认值其实就是 totalCores 数量,这也印证了我们之前说的textFiletextFile,这个方法有点特殊,我们看一下它的参数是什么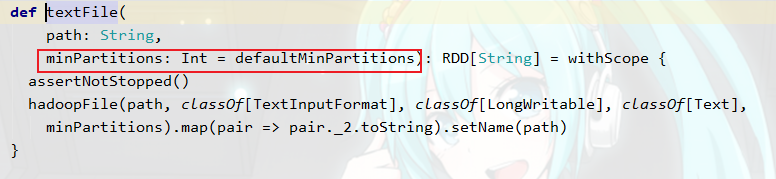
可以发现,这个和makeRDD类似,都有两个参数,而且第二个参数也有默认值,不过,重点来了!!!
这个并行度叫做 minPartitions,顾名思义,这个是最小的并行度,是什么意思的?意思就是最小并行度由我们设置,但是实际的并行度可能会比我们设置的大
那么为什么会出现这种情况呢?因为我们可以看到如下👇
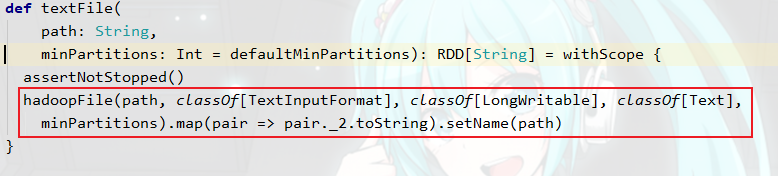
该textFile底层实质是调用Hadoop的TextInputFormat来进行读取数据,我们知道MR的数据默认读取组件就是TextInputFormat,当时的读取规则是按照文件来进行逻辑切片,一个文件达到默认128M逻辑切片一次,所以一个文件至少产生一个MapTask任务
所以,textFile进行读取的时候也会这样进行切片,一个文件至少对应生成一个分区public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException { Stopwatch sw = new Stopwatch().start(); FileStatus[] files = listStatus(job); // Save the number of input files for metrics/loadgen job.setLong(NUM_INPUT_FILES, files.length); long totalSize = 0; // compute total size for (FileStatus file: files) { // check we have valid files if (file.isDirectory()) { throw new IOException("Not a file: "+ file.getPath()); } totalSize += file.getLen(); } long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input. FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize); // generate splits ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits); NetworkTopology clusterMap = new NetworkTopology(); for (FileStatus file: files) { Path path = file.getPath(); long length = file.getLen(); if (length != 0) { FileSystem fs = path.getFileSystem(job); BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { blkLocations = fs.getFileBlockLocations(file, 0, length); } if (isSplitable(fs, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(goalSize, minSize, blockSize); long bytesRemaining = length; while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length-bytesRemaining, splitSize, clusterMap); splits.add(makeSplit(path, length-bytesRemaining, splitSize, splitHosts[0], splitHosts[1])); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length - bytesRemaining, bytesRemaining, clusterMap); splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining, splitHosts[0], splitHosts[1])); } } else { String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap); splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1])); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.elapsedMillis()); } return splits.toArray(new FileSplit[splits.size()]); } 由源码我们大致可以知道,并行度和文件数量以及文件大小有关,有兴趣的小伙伴可以去深入研究一下,我在这里就不过多阐述了
总结一下
textFile方法,那就是我们可以控制并行度最小有多少个,但是实际的并行度会根据实际的文件大小和文件个数进行调整!【2】
Standalone和Yarn 模式下textFile方法在集群模式下和local模式下都一样,所以就不说了,重点说一下makeRDD,集群模式下和local模式还是有一点区别的!!!CoarseGrainedSchedulerBackend

我们可以看到,集群模式下在我们没有设置并行度的情况下,默认最小是2
集群👇

本地👇

集群和本地并行度的区别就在这里,其他的都和local模式大同小异!!!
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


