开发环境 与spring结合使用 扩展及新技术 场景 来源 4v特征 量大、种类多、价值密度低、速度快 技术 技术架构挑战 其他挑战 如何对大数据存储和分析 hadoop技术实现 学习 名字源于孩子玩具hadoop 开源、分布式存储+计算、可扩展 扩展、容错(副本)、海量存储 infoq.com 谷歌 现在Hadoop3.x HDP安装和升级,添加和删除节点比较费劲 预测发货 亚马逊 分块-副本不同节点上 hadoop https://bennyrhys.blog.csdn.net/article/details/108904326 cdh版本的hadoop和其他第三方具有稳定性 java环境 先搭建伪分布式 配置环境变量 如果提示没有可用的软件包,是本机安装的时候就自动安装了 .开头目录默认隐藏 拷贝文件 验证是否配置成功 没有安装ifconfig等命令,运行ifconfig命令就会出错。 解决方法: yum search ifconfig Linux-SSH报错:Could not resolve hostname node1: Name or service not know bin文件 etc/hadoop 2启动hdfs 页面可以查看当前活跃节点 测试查看指令帮助 提示使用hadoop fs + 参数 创建本地文件/root/data 上传文件 法2copy 过期建议使用-R https://192.168.210.121:50070/ 本地映射 centos映射 uname -n :查看host对应的域名 1 先在/etc/hostname 配置想要的域名 默认localhost.localdomain修改hadoop101 2 在/etc/hosts 配置ip和域名映射 192.168.31.101 hadoop101 创建本地maven项目 指定cdh的本地仓库和url地址(默认没有cdh的包) 注意导入的包 Java代码 验证虚拟机生成文件 关闭安全模式 NameNode(全局把控,唯一) 客户端请求(默认配置128M的块,3个副本) 客户端 分块12M/块 客户端 提供名字 读写数据有完善的容错机制 缺 官网配置 https://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0/ etc/hadoop/yarn-site.xml: 启动 ResourceManager 停止 序列化、比较 接口 申请Node资源,获取信息,启动指定Node的Container 选择新版本的Mapper 本地打jar包 确保hello.txt文件在hdfs上 启动 检验输出wc在hdfs上 防止重复执行文件,形成重复输出的报错 场景 验证生效 jps可以验证 yarn开启聚合 修改配置文件 其中包含了生成hdfs的保存的路径
文章目录
导学

学做镜像

生态圈

目录

实战
分析客户端登录日志

大数据概述
足球预判分析人物特性
购物推荐



采集-存储-分析-可视化
量大,无法用结构化数据库,关系型数据库
经典数据库没有考虑数据多类别 比如json
实时性的技术挑战
网络架构、数据中心、运维挑战
数据隐私

谷歌可以支持pc机处理,成本低。但容错要处理特别好。只有技术论文,没有技术实现
mr mr
bigtable hbase
gfs hdfs
官网-英文-实战-社区活动-动手练习-持续初识Hadoop
概述

核心组件
HDFS分布式文件系统
128m数据块

文件-分块-备份 (编号)

资源调度系统YARN

Hadoop1.x只支持rm,但Hadoop2.x通过Yarn支持其他(spark)

MapReduce


shuffing重新洗牌,把相同的key分到一个地方优势



发展史
https://www.infoq.cn/article/hadoop-ten-years-interpretation-and-development-forecast
Apache hadoop开源 2006, 900节点1T 209秒 世界最快 2008 商业化公司 首Hadoop发行版 《权威指南》2009
Hbse、Pig、Hive、Zookeep脱离Hadoop成为Apache顶级项目
Spark逐渐代替MR成为Hadoop执行引擎 2014

IBM-基于hadoop数据分析软件
移动-大云 研究hadoop
阿里-云梯 处理电子商务数据
Mapr公司 推出mapr和分布式文件系统生态系统


有hadoop不够,mr只能实现离线批处理,但如果还要实时计算还需要生态系统的其他玩家 spark

39.47
hive: sql->mr 适用离线文件分析
R 统计分析
Mathout深度学习 往spark方向去了,底层mr不更新了
pig脚本->mr 适合离线分析
Oozie 依赖关系工作流
Zookeeper分布式协调管理多组件 (Hbase单点故障问题)
Flume分布式日志收集
Sqoop传统数据库和hadoop数据传输
Hbase结构化可伸缩的存储数据库 实时查询数据 快查(s级别上)发行版本选择

解决jar包冲突
商业按照
CDH提供cm码,浏览器下一步安装,文档丰富,Spark合作,cm不开源可能有坑
https://archive.cloudera.com/cdh5/cdh/5/
选择尾缀相同的tar.gz cdh

CDH >HDP > Apache企业应用案例
构建购买人群模型,发邮件 怀孕
啤酒和尿布第3章 分布式文件系统HDFS

设计分布式文件系统

每个文件128M存入前分块,解决并行处理提升效率,多副本存储负载均衡。

架构


运行在Linux上HDFS由Java编写副本机制
hdfs不支持多并发写。

副本存放策略
先同机架,后不同机架。为了安全应该最少一个机架
副本挂掉之后可以到另一个机架获取

环境搭建
java-jdk
mysql
 ### 关闭防火墙
### 关闭防火墙设置防火墙 查看防火墙状态 systemctl status firewalld.service 停止firewall systemctl stop firewalld.service 禁止firewall开机启动 systemctl disable firewalld.service Mac上的仿xshell
CDH版-hadoop
https://archive.cloudera.com/cdh5/cdh/5/
 hadoop需要配合java环境和ssh使用
hadoop需要配合java环境和ssh使用

ssh

jdk
// 解压 tar -zxvf 待解压文件 -C 指定目录解压 // 配置 vi /etc/profile export JAVA_HOME=/root/software/jdk1.8.0_91 export PATH=$JAVA_HOME/bin:$PATH // 刷新 source /etc/profile // 验证 java -version java version "1.8.0_91" Java(TM) SE Runtime Environment (build 1.8.0_91-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode) 
tar -zxvf 文件 -C 解压路径


验证生效
source /etc/pro // 也可以这样

ssh免密登录
sudo yum install ssh 没有可用软件包 ssh。 错误:无须任何处理 

[root@hadoop01 jdk1.8.0_91]# ssh-keygen -t rsa // 连续回车 // 存储 Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. // 进入存储 .sh查 [root@hadoop01 ~]# ls -al
ls -al // 展示.开头文件进入目录


[root@hadoop01 .ssh]# cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys [root@hadoop01 .ssh]# cat authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDcNTPFpbnrmR3TAp+3Hw8aFpr7uGp88vzCJi3BCn6EIInEIWp0LMgDglDnUx3OJ8/fg2bNKfrukWmcKQUcpLXrXlw0cFsSHM9Jwh1weNgq3JBsS3dfQ8Vu5OdNkOL85PwbL3/K9BdkZcJhtCKEYGuyK20XMgrD+8WHGxtvTXX6G3WstvbuzLU/ex+K1zopjb12z9gJ1tpUZyCShllnU/NbSQMeMPSOKyb2Z18YGF+ienOf1lfklzE9zj4LGgxG5gQQtgmSWrI85sOrBKqCgzBBVYxA2Rh97XKqbJlD9DdOoc0F4kBBBz6i1pJA4jDg8shEpfz/jD8oKunS7UQLQxEt root@hadoop01 // 验证登录 [root@hadoop01 .ssh]# ssh localhost The authenticity of host 'localhost (::1)' can't be established. ECDSA key fingerprint is 84:7e:3a:83:2a:8e:26:e3:ba:15:72:36:4b:05:45:d6. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Last login: Thu Oct 1 12:13:45 2020 from 192.168.210.1 [root@hadoop01 ~]# exit 登出 // 解决ssh hadoop01 找不到名称 [root@hadoop01 ~]# ssh hadoop01 The authenticity of host 'hadoop01 (::1)' can't be established. ECDSA key fingerprint is 84:7e:3a:83:2a:8e:26:e3:ba:15:72:36:4b:05:45:d6. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop01' (ECDSA) to the list of known hosts. Last login: Sun Oct 4 02:22:22 2020 from 192.168.210.1 [root@hadoop01 ~]# exit 登出 Connection to hadoop01 closed. [root@hadoop01 ~]# ssh hadoop01 Last login: Sun Oct 4 02:22:32 2020 from localhost [root@hadoop01 ~]# exit 登出 Connection to hadoop01 closed.

解决ifconfig命令失效
yum install net-tools.x86_64解决ssh报错
#vi /etc/hosts 127.0.0.1 localhost hadoop01 localhost4 localhost4.localdomain4 ::1 localhost hadoop01 localhost6 localhost6.localdomain6 // 重启 reboot hadoop
客户端

删除所有cmd文件,这是windows上使用的

[root@hadoop01 hadoop-2.6.0-cdh5.7.0]# cd bin [root@hadoop01 bin]# ll 总用量 84 -rwxr-xr-x. 1 1106 4001 5509 3月 24 2016 hadoop -rwxr-xr-x. 1 1106 4001 8298 3月 24 2016 hadoop.cmd -rwxr-xr-x. 1 1106 4001 12175 3月 24 2016 hdfs -rwxr-xr-x. 1 1106 4001 6915 3月 24 2016 hdfs.cmd -rwxr-xr-x. 1 1106 4001 5463 3月 24 2016 mapred -rwxr-xr-x. 1 1106 4001 5949 3月 24 2016 mapred.cmd -rwxr-xr-x. 1 1106 4001 1776 3月 24 2016 rcc -rwxr-xr-x. 1 1106 4001 12176 3月 24 2016 yarn -rwxr-xr-x. 1 1106 4001 10895 3月 24 2016 yarn.cmd [root@hadoop01 bin]# rm *.cmd rm:是否删除普通文件 "hadoop.cmd"? rm:是否删除普通文件 "hdfs.cmd"? rm:是否删除普通文件 "mapred.cmd"? rm:是否删除普通文件 "yarn.cmd"
配置文件
sbin
启动集群的
hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
案例使用
hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar

hadoop配置文件的修改
etc/hadoop

// 获取java位置 [root@hadoop01 ~]# echo $JAVA_HOME /root/software/jdk1.8.0_91 //修改文件 hadoop]# vi hadoop-env.sh # The java implementation to use. export JAVA_HOME=/root/software/jdk1.8.0_91 hdfs配置伪分布式1个节点

etc/hadoop/core-site.xml: // hdfs生成目录 <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:8020</value> </property> // 解决:临时目录变指定目录hdfs位置(注意创建目录) <property> <name>hadoop.tmp.dir</name> <value>/root/hadoop/tmp</value> </property> etc/hadoop/hdfs-site.xml: <property> <name>dfs.replication</name> <value>1</value> </property> // 集群slave,1个nameNode和多个dateNode 有多少个dateNode,直接把hostname写到slaves中 vi slaves hadoop01 [root@hadoop01 ~]# mkdir hadoop [root@hadoop01 ~]# cd hadoop/ [root@hadoop01 hadoop]# mkdir tmp [root@hadoop01 hadoop]# cd tmp/ [root@hadoop01 tmp]# ll 总用量 0 [root@hadoop01 tmp]# pwd /root/hadoop/tmp 启动hdfs

1格式化文件系统// hdfs格式化启动(一次启动,不可多次启动) $ bin/hdfs namenode -format // 过时hadoop改用hdfs DEPRECATED: Use of this script to execute hdfs command is deprecated. bin]# ./hadoop namenode -format Start NameNode daemon and DataNode daemon: $ sbin/start-dfs.sh sbin]# ./start-dfs.sh yes // 验证1 jps [root@hadoop01 sbin]# jps 2599 DataNode 2521 NameNode 2778 SecondaryNameNode 2890 Jps // 假设出现问题追踪日志 out->log 启动时有路径 sbin]# cat /root/software/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-namenode-hadoop01.log // 验证2 网页 https://192.168.210.121:50070/
存活的节点信息
日志目录输出 data name namesecondary[root@hadoop01 ~]# cd /root/hadoop/tmp/ [root@hadoop01 tmp]# ll 总用量 0 drwxr-xr-x. 5 root root 48 10月 4 06:36 dfs [root@hadoop01 tmp]# cd dfs/ [root@hadoop01 dfs]# ll 总用量 0 drwx------. 3 root root 38 10月 4 06:36 data drwxr-xr-x. 3 root root 38 10月 4 06:36 name drwxr-xr-x. 3 root root 38 10月 4 06:38 namesecondary 
停止hdfs
[root@hadoop01 sbin]# ./stop-dfs.sh [root@hadoop01 sbin]# jps 3243 Jps HDFS 常用shell指令

配置hadoop/bin环境变量
vi /etc/profile export HADOOP_HOME=/root/software/hadoop-2.6.0-cdh5.7.0 export PATH=$HADOOP_HOME/bin:$PATH source /etc/profile 指令帮助
hdfs Usage: hdfs [--config confdir] COMMAND where COMMAND is one of: dfs run a filesystem command on the file systems supported in Hadoop. namenode -format format the DFS filesystem secondarynamenode run the DFS secondary namenode namenode run the DFS namenode journalnode run the DFS journalnode zkfc run the ZK Failover Controller daemon datanode run a DFS datanode dfsadmin run a DFS admin client haadmin run a DFS HA admin client fsck run a DFS filesystem checking utility balancer run a cluster balancing utility jmxget get JMX exported values from NameNode or DataNode. mover run a utility to move block replicas across storage types oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to an legacy fsimage oev apply the offline edits viewer to an edits file fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot lsSnapshottableDir list all snapshottable dirs owned by the current user Use -help to see options portmap run a portmap service nfs3 run an NFS version 3 gateway cacheadmin configure the HDFS cache crypto configure HDFS encryption zones storagepolicies list/get/set block storage policies version print the version [root@hadoop01 bin]# hdfs dfs Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] <path> ...] [-cp [-f] [-p | -p[topax]] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] <src> <localdst>] [-help [cmd ...]] 前提环境-启动hdfs
[root@hadoop01 sbin]# ./start-dfs.sh [root@hadoop01 sbin]# jps 3665 DataNode 3555 NameNode 3925 Jps 3822 SecondaryNameNode 本地上传文件到hdfs
[root@hadoop01 ~]# mkdir data [root@hadoop01 ~]# cd data/ [root@hadoop01 data]# vi hello.txt hello world hello hadoop hello hdfs [root@hadoop01 ~]# cd /root/data/ [root@hadoop01 data]# hadoop fs -ls / 20/10/04 07:29:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@hadoop01 data]# hadoop fs -put hello.txt / 20/10/04 07:29:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@hadoop01 data]# hadoop fs -ls / 20/10/04 07:29:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items -rw-r--r-- 1 root supergroup 37 2020-10-04 07:29 /hello.txt [root@hadoop01 data]# hadoop fs -cat /hello.txt 20/10/04 07:30:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable hello world hello hadoop hello hdfs [root@hadoop01 data]# hadoop fs -copyFromLocal hello.txt /hello/a/b/h.txt 20/10/04 07:39:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@hadoop01 data]# hadoop fs -lsr / lsr: DEPRECATED: Please use 'ls -R' instead. 20/10/04 07:39:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello/a drwxr-xr-x - root supergroup 0 2020-10-04 07:39 /hello/a/b -rw-r--r-- 1 root supergroup 37 2020-10-04 07:39 /hello/a/b/h.txt -rw-r--r-- 1 root supergroup 37 2020-10-04 07:29 /hello.txt [root@hadoop01 data]# hadoop fs -cat /hello/a/b/h.txt 20/10/04 07:39:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable hello world hello hadoop hello hdfs HDFS创建递归文件夹-p
// mkdir -p 递归创建hdfs上的文件夹 [root@hadoop01 data]# hadoop fs -mkdir -p /hello/a/b 20/10/04 07:32:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@hadoop01 data]# hadoop fs -ls / 20/10/04 07:33:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello -rw-r--r-- 1 root supergroup 37 2020-10-04 07:29 /hello.txt [root@hadoop01 data]# hadoop fs -ls /hello 20/10/04 07:34:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello/a [root@hadoop01 data]# hadoop fs -ls /hello/a 20/10/04 07:34:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello/a/b 递归查看文件夹lsr
[root@hadoop01 data]# hadoop fs -lsr / lsr: DEPRECATED: Please use 'ls -R' instead. 20/10/04 07:35:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello/a drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello/a/b -rw-r--r-- 1 root supergroup 37 2020-10-04 07:29 /hello.txt HDFS文件下载到本地 -get
[root@hadoop01 data]# ls hello.txt [root@hadoop01 data]# hadoop fs -get /hello/a/b/h.txt 20/10/04 07:41:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@hadoop01 data]# ls hello.txt h.txt HDFS删除文件,文件夹
// 删除文件rm [root@hadoop01 data]# hadoop fs -rm /hello 20/10/04 07:43:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable rm: `/hello': Is a directory [root@hadoop01 data]# hadoop fs -rm /hello.txt 20/10/04 07:44:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Deleted /hello.txt [root@hadoop01 data]# hadoop fs -ls -R / 20/10/04 07:44:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello drwxr-xr-x - root supergroup 0 2020-10-04 07:32 /hello/a drwxr-xr-x - root supergroup 0 2020-10-04 07:39 /hello/a/b -rw-r--r-- 1 root supergroup 37 2020-10-04 07:39 /hello/a/b/h.txt // 删除文件夹必须递归 -R [root@hadoop01 data]# hadoop fs -rm -R /hello 20/10/04 07:45:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Deleted /hello [root@hadoop01 data]# hadoop fs -ls -R / 通过页面浏览128M的分块
上传文件小于128,和大于128的情况// h可以展示暂用空间 [root@hadoop01 software]# ls -lh 总用量 472M drwxr-xr-x. 15 1106 4001 4.0K 10月 4 06:35 hadoop-2.6.0-cdh5.7.0 -rw-r--r--. 1 root root 298M 10月 1 12:28 hadoop-2.6.0-cdh5.7.0.tar.gz drwxr-xr-x. 8 10 143 4.0K 4月 1 2016 jdk1.8.0_91 -rw-r--r--. 1 root root 173M 10月 1 12:29 jdk-8u91-linux-x64.tar.gz -rw-r--r--. 1 root root 961K 10月 1 12:28 mysql-connector-java-5.1.38.jar [root@hadoop01 software]# hadoop fs -put hadoop-2.6.0-cdh5.7.0.tar.gz / 
 小于128,1块
小于128,1块
 大于128,298,分成3块
大于128,298,分成3块

配置Mac本地host映射
bennyrhys$ sudo vim /etc/hosts # 大数据hadoop测试 192.168.210.121 hadoop01 192.168.210.122 hadoop02 192.168.210.123 hadoop03 
Java-API操作HDFS文件

host映射
bennyrhys$ vim /etc/hosts # 大数据hadoop测试 192.168.210.121 hadoop01 192.168.210.122 hadoop02 192.168.210.123 hadoop03
Centos7和别的版本有点区别127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.210.121 hadoop01 192.168.210.122 hadoop02 192.168.210.123 hadoop03 开发环境

<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <hadoop.version>2.7.3</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency>
https://repository.cloudera.com/
 cdh版本安装
cdh版本安装
https://repository.cloudera.com/cloudera/webapp/#/home<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <hadoop.version>2.6.0-cdh5.7.0</hadoop.version> </properties> <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> </dependencies> Java-API

虚拟机配置文件[root@hadoop01 hadoop]# vi core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.210.121:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/root/hadoop/tmp</value> </property> </configuration> package com.bennyrhys.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.net.URI; /** * HADDOP HDFS API 操作 * @Author bennyrhys * @Date 2020-10-04 13:34 */ public class HDFSApp { public static final String HDFS_PATH = "hdfs://hadoop01:9000"; FileSystem fileSystem = null; Configuration configuration = null; /** * 创建目录 * @throws Exception */ @Test public void mkdir() throws Exception{ /*System.setProperty("HADOOP_USER_NAME","root"); Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoop01:9000"); conf.set("dfs.replication", "1"); FileSystem fs = FileSystem.get(conf); fs.mkdirs(new Path("/hdfsapi1/test"));*/ fileSystem.mkdirs(new Path("/hdfsapi2/test")); } @Before public void setUp() throws Exception { System.out.println("HDFS.setUp"); configuration = new Configuration(); fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "root"); } @After public void tearDown() throws Exception { configuration = null; fileSystem = null; System.out.println("HDFS.tearDown"); } } [root@hadoop01 hadoop]# hadoop fs -ls -R / 20/10/04 12:28:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable -rw-r--r-- 1 root supergroup 311585484 2020-10-04 07:52 /hadoop-2.6.0-cdh5.7.0.tar.gz drwxr-xr-x - root supergroup 0 2020-10-04 12:14 /hdfsapi drwxr-xr-x - root supergroup 0 2020-10-04 12:14 /hdfsapi/test -rw-r--r-- 1 root supergroup 37 2020-10-04 07:47 /hello.txt 解决角色不同,不可写

fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "root");解决由于hdfs安全模式无法操作
hdfs dfsadmin -safemode leave HDFS-JavaAPI增删改查
package com.bennyrhys.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.util.Progressable; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; /** * HADDOP HDFS API 操作 * @Author bennyrhys * @Date 2020-10-04 13:34 */ public class HDFSApp { public static final String HDFS_PATH = "hdfs://hadoop01:9000"; FileSystem fileSystem = null; Configuration configuration = null; /** * 创建目录 * @throws Exception */ @Test public void mkdir() throws Exception{ /*System.setProperty("HADOOP_USER_NAME","root"); Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoop01:9000"); conf.set("dfs.replication", "1"); FileSystem fs = FileSystem.get(conf); fs.mkdirs(new Path("/hdfsapi1/test"));*/ fileSystem.mkdirs(new Path("/hdfsapi2/test")); } /** * 创建一个文件 * @throws Exception */ @Test public void create() throws Exception{ FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/a.txt")); output.write("hello world".getBytes()); output.flush(); output.close(); } /** * 查看文件 */ @Test public void cat() throws Exception{ FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test/a.txt")); IOUtils.copyBytes(in, System.out, 1024); in.close(); } /** * 文件重命名 */ @Test public void rename() throws Exception{ Path oldPath = new Path("/hdfsapi/test/a.txt"); Path newPath = new Path("/hdfsapi/test/b.txt"); fileSystem.rename(oldPath, newPath); } /** * 本地上传小文件 */ @Test public void copyFromLocalFile()throws Exception{ Path localPath = new Path("/Users/bennyrhys/Desktop/hello.txt"); Path targetPath = new Path("/hdfsapi/test/"); fileSystem.copyFromLocalFile(localPath,targetPath); } /** * 本地上传大文件 * io流操作 */ @Test public void copyFromLocalFileWithProgess()throws Exception{ /*Path localPath = new Path("/Users/bennyrhys/Desktop/hadoop/hadoop-2.6.0-cdh5.7.0.tar.gz"); Path targetPath = new Path("/hdfsapi/test/"); fileSystem.copyFromLocalFile(localPath,targetPath);*/ //297M ls -lh // io 输入 InputStream in = new BufferedInputStream( new FileInputStream( new File("/Users/bennyrhys/Desktop/hadoop/hadoop-2.6.0-cdh5.7.0.tar.gz"))); // 输出 进度显示 FSDataOutputStream out = fileSystem.create(new Path("/hdfsapi/test/hadoop-2.6.0.tar.gz"), new Progressable() { @Override public void progress() { System.out.println("."); // 带进度提醒信息 } }); IOUtils.copyBytes(in, out, 4096); } /** * hdfs下载到本地 * @throws Exception */ @Test public void copyToLocalFile() throws Exception{ Path hdfsPath = new Path("/hdfsapi/test/b.txt"); Path localPath = new Path("/Users/bennyrhys/Desktop/temp.txt"); fileSystem.copyToLocalFile(hdfsPath, localPath); } /** * hdfs指定路径的文件信息 * @throws Exception */ @Test public void listStatus() throws Exception { FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hdfsapi/test/")); for (FileStatus fileStatus : fileStatuses) { String isDir = fileStatus.isDirectory() ? "文件夹" : "文件"; short replication = fileStatus.getReplication(); // 副本数量(hdfs上传有副本预设1,本地没有预设显示3) long len = fileStatus.getLen(); Path path = fileStatus.getPath(); System.out.println(isDir + "t" + replication + "t" + len + "t" + path); } } /** * 删除目录下的文件 * @throws Exception */ @Test public void delete() throws Exception{ fileSystem.delete(new Path("/hdfsapi/test/"), true); // 默认递归删除 } @Before public void setUp() throws Exception { System.out.println("HDFS.setUp"); configuration = new Configuration(); fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "root"); } @After public void tearDown() throws Exception { configuration = null; fileSystem = null; System.out.println("HDFS.tearDown"); } } HDFS读写流程
写数据
DataNode(数据存储,多个)
创建副本(流水线串联副本创建)
NameNode 记住每个块,所对应的DataNode存在哪几个副本节点
DataNode 存储并返回NameNode成功存储读数据
NameNode 提供名字对应的(多个被拆分的块id,及对应的副本DataNode位置)
客户端-DataNode获取最近数据HDFS优缺点
流式数据,一次写入多次读取
适合大文件存储
构建在廉价机器上
低延迟数据访问
小文件(会暂用内存,NameNode压力也就变大)总结
HDFS架构 1 Master(NameNode/NN) 带 N个Slaves(DataNode/DN) HDFS/YARN/HBase 1个文件会被拆分成多个Block blocksize:128M 130M ==> 2个Block: 128M 和 2M NN: 1)负责客户端请求的响应 2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理 DN: 1)存储用户的文件对应的数据块(Block) 2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况 A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case. NameNode + N个DataNode 建议:NN和DN是部署在不同的节点上 replication factor:副本系数、副本因子 All blocks in a file except the last block are the same size Hadoop伪分布式安装步骤 1)jdk安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系统环境变量: ~/.bash_profile export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79 export PATH=$JAVA_HOME/bin:$PATH 使得环境变量生效: source ~/.bash_profile 验证java是否配置成功: java -v 2)安装ssh sudo yum install ssh ssh-keygen -t rsa cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys 3)下载并解压hadoop 下载:直接去cdh网站下载 解压:tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app 4)hadoop配置文件的修改(hadoop_home/etc/hadoop) hadoop-env.sh export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79 core-site.xml <property> <name>fs.defaultFS</name> <value>hdfs://hadoop000:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/app/tmp</value> </property> hdfs-site.xml <property> <name>dfs.replication</name> <value>1</value> </property> slaves 5)启动hdfs 格式化文件系统(仅第一次执行即可,不要重复执行):hdfs/hadoop namenode -format 启动hdfs: sbin/start-dfs.sh 验证是否启动成功: jps DataNode SecondaryNameNode NameNode 浏览器访问方式: https://hadoop000:50070 6)停止hdfs sbin/stop-dfs.sh Hadoop shell的基本使用 hdfs dfs hadoop fs Java API操作HDFS文件 文件 1 311585484 hdfs://hadoop000:8020/hadoop-2.6.0-cdh5.7.0.tar.gz 文件夹 0 0 hdfs://hadoop000:8020/hdfsapi 文件 1 49 hdfs://hadoop000:8020/hello.txt 文件 1 40762 hdfs://hadoop000:8020/install.log 问题:我们已经在hdfs-site.xml中设置了副本系数为1,为什么此时查询文件看到的3呢? 如果你是通过hdfs shell的方式put的上去的那么,才采用默认的副本系数1 如果我们是java api上传上去的,在本地我们并没有手工设置副本系数,所以否则采用的是hadoop自己的副本系数 第4章 分布式资源调度YARN

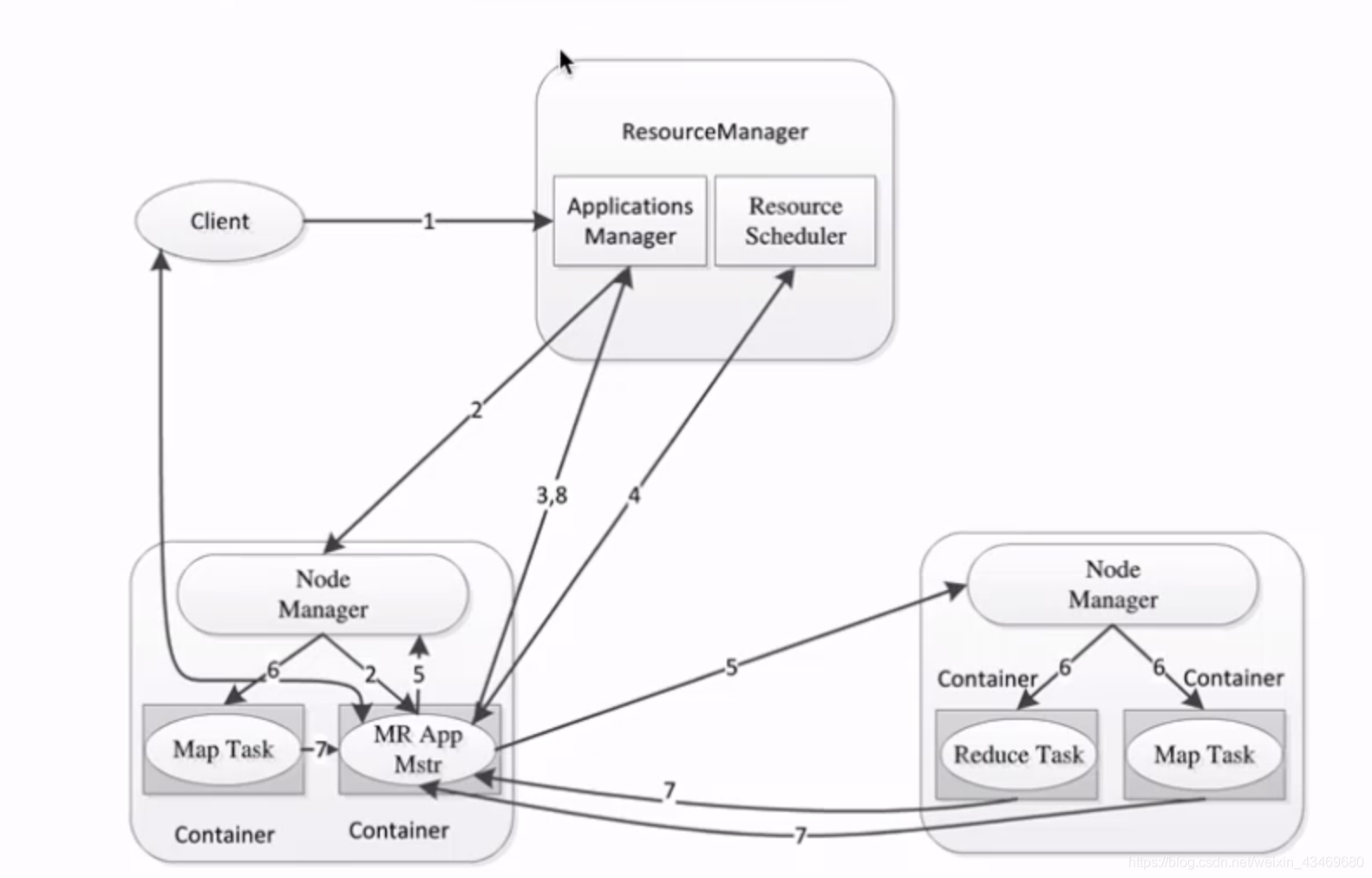
产生背景



概述

架构



执行流程

环境搭建



告诉mr是跑在yarn上
etc/hadoop/mapred-site.xml: <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
$ sbin/start-yarn.sh
检验
https://localhost:8088/

jps
NodeManager
$ sbin/stop-yarn.sh提交作业mr到yarn
[root@hadoop01 mapreduce]# pwd /root/software/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce [root@hadoop01 mapreduce]# ll 总用量 4876 -rw-r--r--. 1 1106 4001 523960 3月 24 2016 hadoop-mapreduce-client-app-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 753831 3月 24 2016 hadoop-mapreduce-client-common-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 1542374 3月 24 2016 hadoop-mapreduce-client-core-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 171256 3月 24 2016 hadoop-mapreduce-client-hs-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 10467 3月 24 2016 hadoop-mapreduce-client-hs-plugins-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 43777 3月 24 2016 hadoop-mapreduce-client-jobclient-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 1499926 3月 24 2016 hadoop-mapreduce-client-jobclient-2.6.0-cdh5.7.0-tests.jar -rw-r--r--. 1 1106 4001 91087 3月 24 2016 hadoop-mapreduce-client-nativetask-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 50818 3月 24 2016 hadoop-mapreduce-client-shuffle-2.6.0-cdh5.7.0.jar -rw-r--r--. 1 1106 4001 276202 3月 24 2016 hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar drwxr-xr-x. 2 1106 4001 4096 3月 24 2016 lib drwxr-xr-x. 2 1106 4001 29 3月 24 2016 lib-examples drwxr-xr-x. 2 1106 4001 4096 3月 24 2016 sources [root@hadoop01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3 hadoop jar 包名.jar 方法 参数总结
Hadoop1.x时: MapReduce:Master/Slave架构,1个JobTracker带多个TaskTracker JobTracker: 负责资源管理和作业调度 TaskTracker: 定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况; 接收来自JT的命令:启动任务/杀死任务 YARN:不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度 XXX on YARN的好处: 与其他计算框架共享集群资源,按资源需要分配,进而提高集群资源的利用率 XXX: Spark/MapReduce/Storm/Flink YARN架构: 1)ResourceManager: RM 整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度 处理客户端的请求: 提交一个作业、杀死一个作业 监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何进行处理 2) NodeManager: NM 整个集群中有多个,负责自己本身节点资源管理和使用 定时向RM汇报本节点的资源使用情况 接收并处理来自RM的各种命令:启动Container 处理来自AM的命令 单个节点的资源管理 3) ApplicationMaster: AM 每个应用程序对应一个:MR、Spark,负责应用程序的管理 为应用程序向RM申请资源(core、memory),分配给内部task 需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面 4) Container 封装了CPU、Memory等资源的一个容器 是一个任务运行环境的抽象 5) Client 提交作业 查询作业的运行进度 杀死作业 YARN环境搭建 1)mapred-site.xml <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> 2)yarn-site.xml <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> 3) 启动YARN相关的进程 sbin/start-yarn.sh 4)验证 jps ResourceManager NodeManager https://hadoop000:8088 5)停止YARN相关的进程 sbin/stop-yarn.sh 提交mr作业到YARN上运行: /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar hadoop jar hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3 第5章 分布式计算框架MapReduce

概述

 前置条件 haddop的安装并运行(hdfsyarn)
前置条件 haddop的安装并运行(hdfsyarn)WorldCount词频统计案例



编程模型

map和reduce执行流程


整个过程就是kv形式,记录偏移量 长度

Format



拆分split,默认和block128M是对应的

记录读取器,读取每一行


架构
1.x

MapReduce1.x的架构 1)JobTracker: JT 作业的管理者 管理的 将作业分解成一堆的任务:Task(MapTask和ReduceTask) 将任务分派给TaskTracker运行 作业的监控、容错处理(task作业挂了,重启task的机制) 在一定的时间间隔内,JT没有收到TT的心跳信息,TT可能是挂了,TT上运行的任务会被指派到其他TT上去执行 2)TaskTracker: TT 任务的执行者 干活的 在TT上执行我们的Task(MapTask和ReduceTask) 会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT 3)MapTask 自己开发的map任务交由该Task出来 解析每条记录的数据,交给自己的map方法处理 将map的输出结果写到本地磁盘(有些作业只仅有map没有reduce==>HDFS) 4)ReduceTask 将Map Task输出的数据进行读取 按照数据进行分组传给我们自己编写的reduce方法处理 输出结果写到HDFS 2.x
方便扩充第三方的spark
Java写WordCount

JAVA代码
package com.bennyrhys.hadoop.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @Author bennyrhys * @Date 2020-10-09 23:39 * 使用MapReduce开发WordCount */ public class WordCount { /** * Map:输入文件 * Text当成Java中的字符串 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 接收一行指定数据 String line = value.toString(); // 根据指定字符进行分割 String[] words = line.split(" "); for (String word : words) { // 通过上下文,将分割的map赋值v=1,处理结果输出 context.write(new Text(word), one); } } } public static class MyReduce extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0; for (LongWritable value : values) { // LongWritable -> java类型 .get // 求key出现次数的总和 sum += value.get(); } // 求最后统计结果的输出 context.write(key, new LongWritable(sum)); } } /** * Driver: 封装MapReduce */ public static void main(String[] args) throws Exception { // 创建 hadoop 的configuration Configuration configuration = new Configuration(); // 创建 job Job job = Job.getInstance(configuration, "wordcount"); // 设置job的处理类 job.setJarByClass(WordCount.class); // 设置作业处理的输入路径 FileInputFormat.setInputPaths(job, new Path(args[0])); // 设置map参数 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 设置reduce参数 job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 设置作业处理的输出路径 FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
clean-》package,在target里面找到
 本地上传到服务器
本地上传到服务器scp hdfs-api-1.0-SNAPSHOT.jar root@hadoop01:~/lib [root@hadoop01 data]# hadoop fs -cat /hello.txt 20/10/05 14:54:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable hello world hello hadoop hello hdfs [root@hadoop01 data]# hadoop jar /root/data/hdfs-api-1.0-SNAPSHOT.jar com.bennyrhys.hadoop.mapreduce.WordCount hdfs://hadoop01:9000/hello.txt hdfs://hadoop01:9000/output/wc [root@hadoop01 data]# hadoop fs -lsr /output/wc lsr: DEPRECATED: Please use 'ls -R' instead. 20/10/05 15:00:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable -rw-r--r-- 1 root supergroup 0 2020-10-05 14:57 /output/wc/_SUCCESS -rw-r--r-- 1 root supergroup 35 2020-10-05 14:57 /output/wc/part-r-00000 [root@hadoop01 data]# hadoop fs -cat /output/wc/part-r-00000 20/10/05 15:00:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 1 hadoop 1 hdfs 1 hello 3 world 1 手动删除
写脚本,先删除输出文件在执行// 改变执行权限 -rw-r--r--. 变成 -rwxr--r-- chmod u+x wc_rm.sh ./wc_rm.sh java自动删除

MapReduce编程之Combiner



Combiner hadoop jar /home/hadoop/lib/hadoop-train-1.0.jar com.imooc.hadoop.mapreduce.CombinerApp hdfs://hadoop000:8020/hello.txt hdfs://hadoop000:8020/output/wc 使用场景: 求和、次数 + 平均数 X
运行的屏幕输出

MapReduce之Partitioner



 检验四个partation
检验四个partation

MapReduce配置history

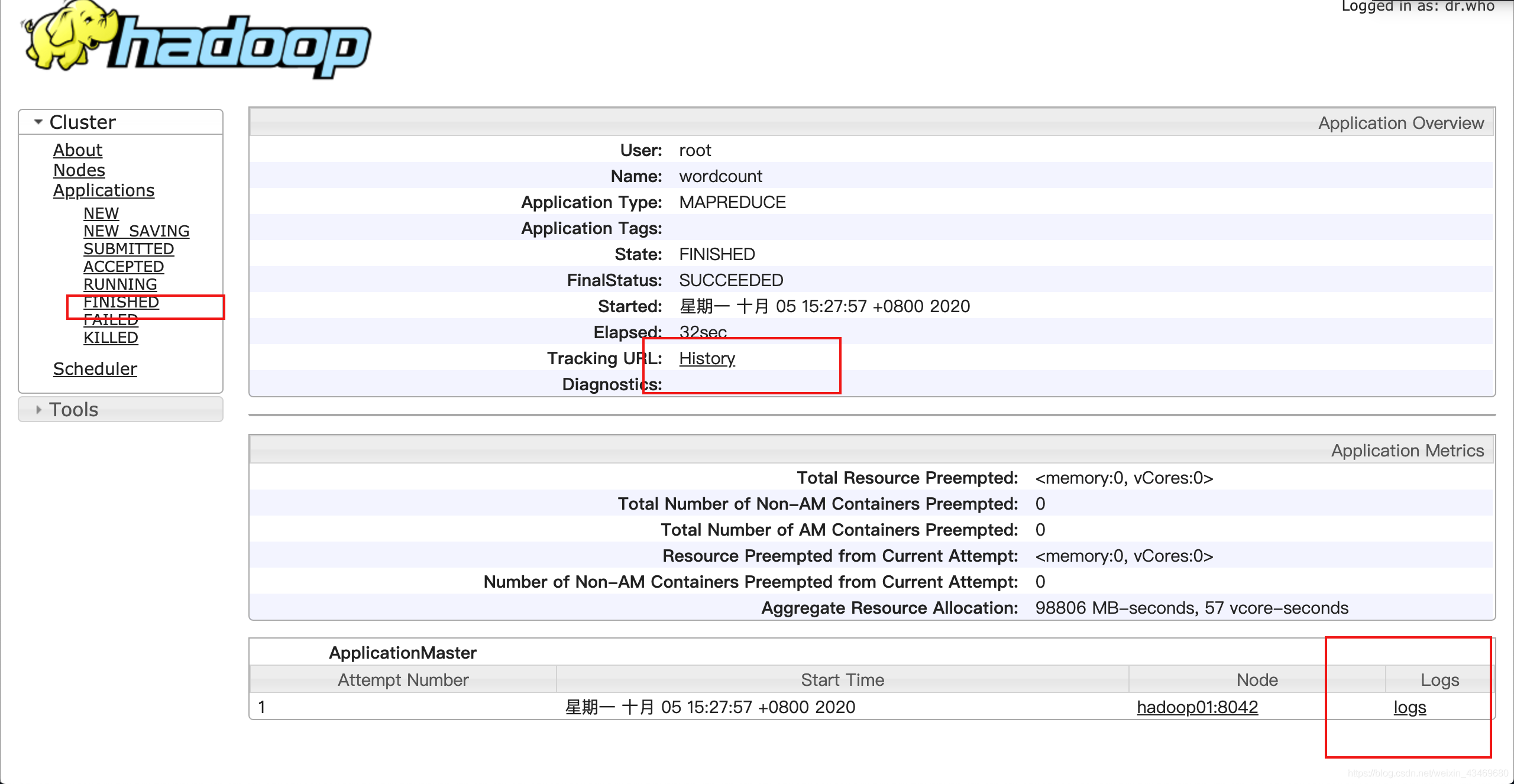


重启yarn
启动jobhistory

hdfs输出文件验证

解决聚合没有打开 log无法查看


wordcount: 统计文件中每个单词出现的次数 需求:求wc 1) 文件内容小:shell 2)文件内容很大: TB GB ???? 如何解决大数据量的统计分析 ==> url TOPN <== wc的延伸 工作中很多场景的开发都是wc的基础上进行改造的 借助于分布式计算框架来解决了: mapreduce 分而治之 (input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output) 核心概念 Split:交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元 HDFS:blocksize 是HDFS中最小的存储单元 128M 默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议) InputFormat: 将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; TextInputFormat: 处理文本格式的数据 OutputFormat: 输出 MapReduce1.x的架构 1)JobTracker: JT 作业的管理者 管理的 将作业分解成一堆的任务:Task(MapTask和ReduceTask) 将任务分派给TaskTracker运行 作业的监控、容错处理(task作业挂了,重启task的机制) 在一定的时间间隔内,JT没有收到TT的心跳信息,TT可能是挂了,TT上运行的任务会被指派到其他TT上去执行 2)TaskTracker: TT 任务的执行者 干活的 在TT上执行我们的Task(MapTask和ReduceTask) 会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT 3)MapTask 自己开发的map任务交由该Task出来 解析每条记录的数据,交给自己的map方法处理 将map的输出结果写到本地磁盘(有些作业只仅有map没有reduce==>HDFS) 4)ReduceTask 将Map Task输出的数据进行读取 按照数据进行分组传给我们自己编写的reduce方法处理 输出结果写到HDFS 使用IDEA+Maven开发wc: 1)开发 2)编译:mvn clean package -DskipTests 3)上传到服务器:scp target/hadoop-train-1.0.jar hadoop@hadoop000:~/lib 4)运行 hadoop jar /home/hadoop/lib/hadoop-train-1.0.jar com.imooc.hadoop.mapreduce.WordCountApp hdfs://hadoop000:8020/hello.txt hdfs://hadoop000:8020/output/wc 相同的代码和脚本再次执行,会报错 security.UserGroupInformation: PriviledgedActionException as:hadoop (auth:SIMPLE) cause: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop000:8020/output/wc already exists Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop000:8020/output/wc already exists 在MR中,输出文件是不能事先存在的 1)先手工通过shell的方式将输出文件夹先删除 hadoop fs -rm -r /output/wc 2) 在代码中完成自动删除功能: 推荐大家使用这种方式 Path outputPath = new Path(args[1]); FileSystem fileSystem = FileSystem.get(configuration); if(fileSystem.exists(outputPath)){ fileSystem.delete(outputPath, true); System.out.println("output file exists, but is has deleted"); } Combiner hadoop jar /home/hadoop/lib/hadoop-train-1.0.jar com.imooc.hadoop.mapreduce.CombinerApp hdfs://hadoop000:8020/hello.txt hdfs://hadoop000:8020/output/wc 使用场景: 求和、次数 + 平均数 X Partitioner hadoop jar /home/hadoop/lib/hadoop-train-1.0.jar com.imooc.hadoop.mapreduce.ParititonerApp hdfs://hadoop000:8020/partitioner hdfs://hadoop000:8020/output/partitioner 第6章 Hadoop项目实战
求职中 • Java全栈养成计划公众号 • 让我遇见相似的灵魂回复领取:竞赛 书籍 项目 面试左手代码,右手吉他,这就是天下:如果有一天我遇见相似的灵魂 那它肯定是步履艰难 不被理解 喜黑怕光的。如果可以的话 让我触摸一下吧 它也一样孤独得太久。 不一样的文艺青年,不一样的程序猿。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)













 7906
7906