这是从2010/01/12-2011/12/09一家在英国的网络电商的真实数据,所以数据类型和值都具有很强的随机性,实践性较强。 该电商的主营业务是卖一些订制礼物。所以本次分析的目的是对该电商的客户进行分类,以让业务部门可以对不同的顾客有不一样的促销方式(marketing initiatives or offer),以增大销量。 数据源:https://www.kaggle.com/carrie1/ecommerce-data 在数据已经被清理干净之后,我们可以对其特征进行观察 还有一种情况就是Stockcode为D的时候,后面都注释该商品为打折商品 这些数据对我们造成了很大的困扰, 因为被取消,造成的原因很多,例如拍错或者不想要等原因, 这个可以之后在关注流失的时候重点分析,我们现在可以将他们先行取消。 现在数据已经基本上彻底“干净”,我们可以开始进行RFM分析: 首先我们选择以天数为最小时间单位,创建新的一列date: R:最近的一次的消费。我们采用最后一天(max)作为“今天”减去每位顾客最后一次消费的时间 F: 每位顾客购买的频次 M:每位顾客购买的销量总额: unitprice*quantity 聚类里有一个重要的参数是K,也就是我们将数据分为几类是最合适的。这个会有欠拟合和过拟合的问题,所以K的选择至关重要。本次选用手肘法进行评测: 手肘法的核心就是观察SSE(误差平方和),当你分类越多,样本划分就越来越精细,SSE自然会逐渐减小,但当K增大到一定程度时,对结果的影响就不会很大。所以我们画出分类从1至10,看SSE的变化趋势,选出拐点处对应的类数。 看到所有顾客已经被分为3类,我们接着探究一下每类的特性 R & Cluster 从R分析顾客的等极度为: 2>3>1 F & Cluster 从F分析顾客的等极度为: 3>2>1 M & Cluster 从M分析顾客的等极度为: 2>3>1 综上: 可以得到第二类是最需要保值的顾客,我们可以将他们列为我们的“黄金VIP”提高留存。第三类其次,第一类则为相对逊色的普通用户。 然而,在聚类中,我们只分了三大类。 根据业务要求,如果想参照经典的RFM将每个指标都分类划分,目的也是能根据更精细划分来增强营销的精准性,则会采用另外一种编程方法实现。 当然,具体对于每一个指标划分点在现实工作中要和业务进行讨论,如果在没有经验数据的基础上,用分位数函数进行分组就是最科学的。 我的方法是先定义2个不同的函数,因为3个参数的中需要R越低越好,而F和M则是最高越好。 接下来,将函数运用在rfm中: 这时,有2种方法: 第一种为直接合并法:1+1+1=111 然后确定分类 第二种是将每组的得分利用权重相加: 本次分析采用第二种,但是将第一种的实现写在下面: 第二种的权重法: 得到下图: 我们分别利用了聚类和分箱的方式,实现了RFM顾客分层,结合业务后,提出了对于营销的一些意见。并且由于此数据量的类型非常全面,之后我们也可以去从不同的维度分析该公司情况,包括用更多的算法来测试哪一个参数对总销售额的影响最大,以更完备的提供一些可实用性建议和意见。 PS:这是我写的第二篇数据分析的报告,如果大家发现有错误欢迎评论区留言,这样可以互相进步!如果没有欢迎大家给个鼓励!嘿嘿 下面的链接是我第一篇处女座数据分析报告,主要是针对2019年airbnb纽约的房源进行的可视化一些练习,也欢迎大家移步去看看。(十二卖瓜,自卖自夸,哈哈):
实验背景:
实验内容:
数据预处理:
1.导入观察数据:
#import all necessary package import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings("ignore") #load data df=pd.read_csv(r'E:testecommerce-datadata.csv',encoding='ISO-8859-1') df.head() 
观察数据一共有8列,根据已经显示的前5列,发现数据特点是同一个顾客ID可能在同一个INVOCE中购买了多项商品,并且逐行显示。2.清理数据:
#观察数据 df.info() 
重点关注InvoiceDate 是object格式,为了之后方便计算,我们最好将其变换为Datetime的格式。#利用Datetime函数,加入指定格式,识别参数 df['InvoiceDate']=pd.to_datetime(df.InvoiceDate,format='%m/%d/%Y %H:%M') 3.检查空值
df.isnull().sum() 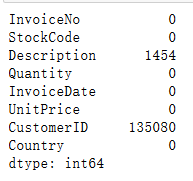
可以看到CID有相当多的空值,由于刚刚没有显示空值行的属性,现在单独将其列出进行分析:Nan_rows=df[df.isnull().T.any()] Nan_rows.tail(5) 
因为我们无法通过别的列进行推断或者根据已有数据进行插值法补全CID,所以将其归类为脏数据删除df=df.dropna(subset=['CustomerID']) df.isnull().sum() 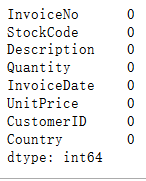
当我们删除CID之后,Description也为0。说明之前的那些CID为NaN的行里有一部分的Description也为NaN4.重复值检查
df.duplicated().sum() 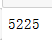
重复值只有5000多行,影响不大,我们选择删除df.drop_duplicates(inplace=True) 数据分析与观察
1:找出Country一共有几种:
df.Country.unique() 
顾客来自很多国家,那具体的下单数量和国家有很大的关联吗?我们可以将每个国家的下单数量进行排序并且可视化进行分析:#先要将重复的CID去除,保证一个顾客只被计算了一次 order_unique_cus=df.drop_duplicates(['CustomerID'], keep='first', inplace=False) order_sum=order_unique_cus.groupby(by='Country').UnitPrice.count() order_sum=order_sum.sort_values(ascending=False).head(5) plt.figure(figsize=(20,5)) sns.barplot(order_sum.index,order_sum.values,palette="Greens_r") plt.ylabel('Counts') plt.title('Num of orders in different country',fontsize=15,color='r',fontweight='bold') plt.xticks(rotation=45) 
明显的可以观察等到英国的购买人数占主要消费,计算出占比为:order_unique_cus.loc[order_unique_cut.Country=='United Kingdom'].shape[0]/order_unique_cut.shape[0 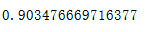
综上,由于主要消费群体为英国,并且每个国家的用户购买习惯也不一样,之后的RFM分析将只会针对英国的顾客进行分析df.describe()  我们可以看到QUANTITY和Unitprice都有极大值的影响,图像应该是严重的长尾状态。
我们可以看到QUANTITY和Unitprice都有极大值的影响,图像应该是严重的长尾状态。
并且发现QUANTITY里竟然有负数的出现,将这些负数取出进行观察:#option1: df[df['Quantity']<0].head(5) #option2: df1=df.query("Quantity<0").head(5) 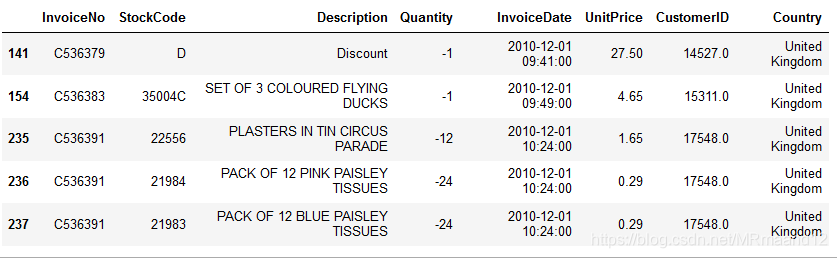
发现Q为负数的时候,InvoiceNo前面都有C的出现,经过确认C开头意味着取消的订单。#用DROP,删除掉<0的行(以Index为索引) df.drop(df[ df.Quantity<0].index, inplace=True) df.describe() 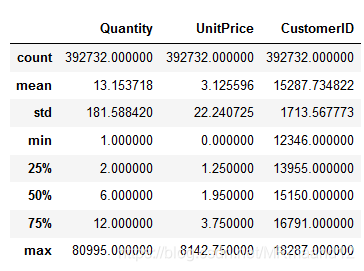
英国顾客的RFM分析
import datetime df['date']=df['InvoiceDate'].apply(lambda x: x.date) 
DATE一列已经被创造出来,且我们保存了原来的InvoiceDate 方便之后进行对照,RFM的定义不再赘述,下面是针对该实验的每个参数的实现方法:#创建消费总额列 df['M']=df['UnitPrice']*df['Quantity'] #将需要分析的列提出,创建一个RFM数据透视表 rfm=pivot_table(index='CustmerID',values=['date','InvoiceNo','M'],aggfunc=['date':'max','InvoiceNo':'count','M':'sum']) #将Invoice的列名修改成F rfm.rename(columns={'Invoice':'F'},inplace=True) #计算最近一次消费,并且将结果类型换算成可计算的数据类型 rfm['R']=(rfm.date.max()-rfm.date)/np.timedelta64(1,'D') #再次取出需要分析的3列 rfm1=rfm[['R','F','M']] rfm1 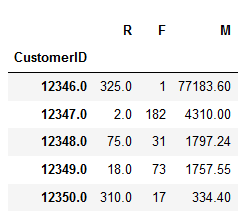
接下来,我们用**聚类(KMEANS)**进行RFM分析:#我们选择1-10 ,对每一个都进行评估 SSE=[] for k in range(1,10): estimator=Kmeans(n_cluster=k) estimator.fit(rfm1) SSE.append(estimator.inertia_) x=range(1,10) plt.plot(x,SSE,'x-') plt.show() 
当K=3的时候,会获得最好的分类,接下来我们就可以使用kmeans包进行计算#选用3作为合适的簇,进行拟合 kmeans=KMeans(n=cluster=3,random_state=0.fit(rfm1) #获取每个点的label rfm1['cluster']=kmeans.labels_ rfm1.sort_values(by='cluster') 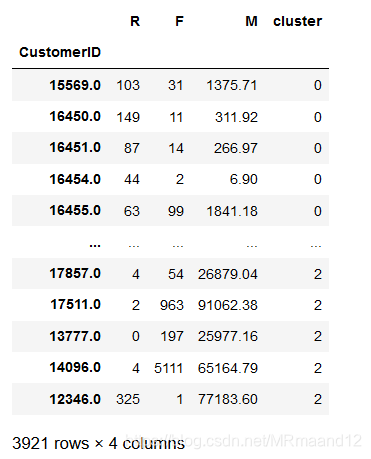
sns.boxyplot(rfm1.cluaster,rfm.R) plt.title('boxplot across R and Cluster',fontsize=15,color='r',fontweight='bold') plt.savefig(r'E:testecommerce-databoxplot across R and cluster.png') 
首先因为R代表的最近的一次消费,所以需要R越小越好,根据箱线分布图:
sns.boxplot(rfm1.cluster,rfm1.F) plt.title('boxplot across F and Cluster',fontsize=15,color='r',fontweight='bold') plt.savefig(r'E:testecommerce-databoxplot across F and cluster.png') 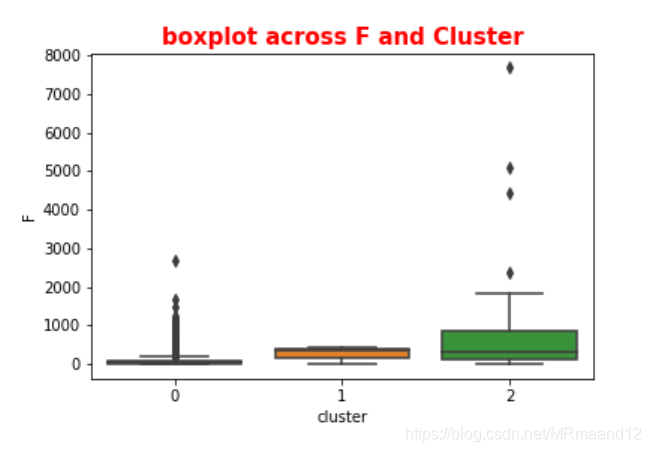
由于F代表频数,我们希望F越大越好,说明买的次数多,根据箱线分布图:
sns.boxplot(rfm1.cluster,rfm1.M) plt.title('boxplot across M and Cluster',fontsize=15,color='r',fontweight='bold') plt.savefig(r'E:testecommerce-databoxplot across M and cluster.png') 
最后M也是商家最在乎的消费总金额,越高买的金额数越大,商家就越获利,根据箱线分布图:
#在每一次新的计算,我偏向于创建一个变量,这样保证原始文件的完整性。 rfm2=rfm[['R','F','M']] #将原始的RFM数据分为4等分 quantile=rfm2.quantile(q=[0.25,0.5,0.75]) def Rscore(x,col): if x<=quantile[col][0.25]: return 1 elif x<=quantile[col][0.5]: return 2 elif x<=quantile[col][0.75]: return 3 else: return 4 def FMScore(x.col): if x<=quantile[col][0.25]: return 4 elif x<=quantile[col][0.5]: return 3 elif x<=quantile[col][0.75]: return 2 else: return 1 rfm2['Rscore']=rfm2['R'].apply(Rscore,args=('R')) rfm2['f_score']=rfm2['F'].apply(FMscore,args=('F')) rfm2['m_score']=rfm2['M'].apply(FMscore,args=('M')) 
#直接合并法:因为rfm为数值型变量,我们需要将他们变为字符串相加 rfm2['str_score']=rfm2['r_score'].apply(str)+rfm2['f_score'].apply(str)+rfm2['m_score'].apply(str) #或者用map直接对每一列的数值一一映射成为STR rfm2['rfmscore']=rfm2['r_score'].map(str)+rfm2['f_score'].map(str)+rfm2['m_score'].map(str) #我将M的权重设为0.5为最重要,R设为0.2,F设为0.3 rfm2['rfm_total_score']=rfm2['r_score']*0.2+rfm2['f_score']*0.3+rfm2['m_score']*0.5

得到得分后,我们对每一个等级的顾客进行贴标签化:bins=rfm2['rfm_total_score'].quantile(q=[0,0.125,0.25,0.375,0.5,0.625,0.75,0.875,1]) bins[0] =0 labels = ['流失客户','一般维持客户','一般发展客户','潜力客户','重要挽留客户','重要保持客户','重要发展客户','重要价值客户'] rfm2['level'] = pd.cut(rfm2.rfm_total_score,bins,labels=labels) 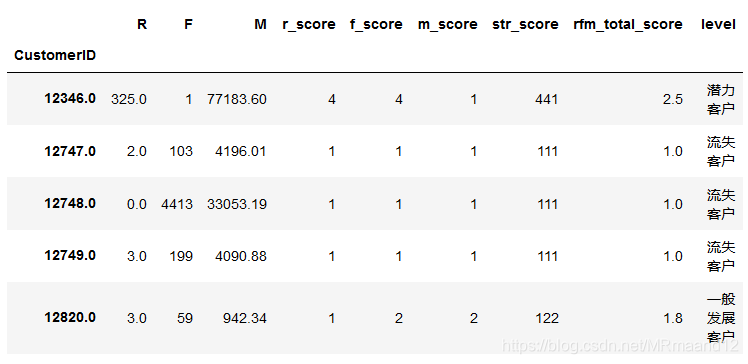
可视化:#这块是为保证可视化输出 中文不是小方块的问题 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = [u'SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.figure(figsize=(15,8)) #准备好要可视化的表格 cus=rfm2.groupby('level').count().sort_values('R') x=cus.index y=cus.R #画图修饰 plt.bar(x,y,alpha=0.9, facecolor = 'lightskyblue', edgecolor = 'white') plt.xticks(x,rotation=60,fontsize=15) plt.title('The Number Of Customer n In Different Type',fontsize=20,color='r',fontweight='bold') plt.ylabel('Num of Customer',fontsize=15) plt.xlabel('Level',fontsize=15) plt.savefig(r'E:testecommerce-dataThe number of customer in different type.png') 
从这个可以看到重要发展客户占绝大多数,说明该电商的前景还是很乐观的,可以在保证重要价值客户依旧留存的基础上,加大营销力度等,将更多的重要发展客户变为忠诚客户,扩展业务。实验结果
https://blog.csdn.net/MRmaand12/article/details/105788430
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











